
2024年11月15日に開催された第7回FEVERワークショップで、ファクトチェックシステムの評価に焦点を当てた参加21チームによる共有タスクAVeriTeCの結果が発表されました。
AVERITEC共有タスクの概要
ワークショップの中心的なイベントとなったAVERITECでは、以下の能力が求められました:
- 証拠収集: ウェブまたは提供された知識ストアから関連する証拠を検索。
- 真偽判定: 主張を「Supported」「Refuted」「Not Enough Evidence」「Conflicting Evidence/Cherry-picking」のいずれかに分類。
- 証拠の質と判定の正確性: 両方を評価する「AVERITECスコア」で測定。
上位5チームのアプローチ
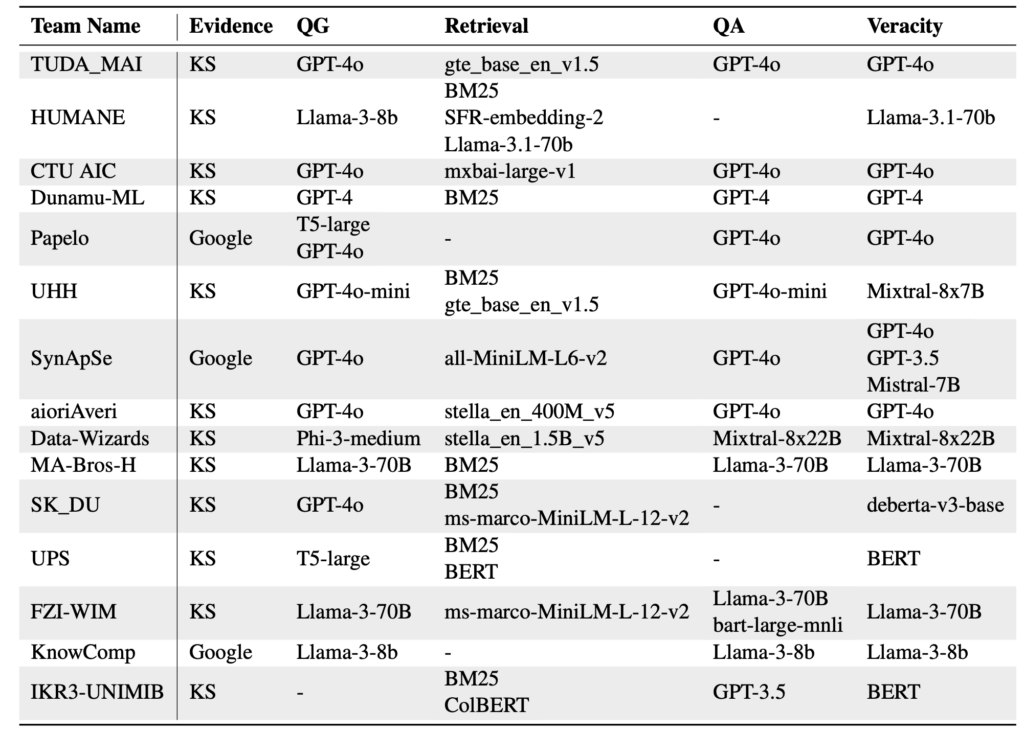
1位: TUDA_MAI (INFACTシステム)
TUDA_MAIのINFACTは、6段階のパイプラインを採用しました。質問生成や証拠収集、大規模言語モデル(GPT-4O)の活用による推論能力が特長で、63%のスコアを記録しました。特に、セマンティック検索技術の利用が証拠収集の精度向上に寄与しました。
2位: HUMANE (HerOシステム)
HerOは、公開されている大規模言語モデル(LLM)のみを使用し、仮想的な質問生成と証拠強化が特徴です。コードをオープンソース化し、57%のスコアを達成しました。低コストかつアクセス可能な設計が注目されています。
3位: AIC CTU
AIC CTUは、Retrieval-Augmented Generation(RAG)をベースにしたシンプルなパイプラインで、BM25を活用して証拠検索を効率化しました。50%のスコアを記録し、コスト効率の良さが評価されました。
4位: Dunamu-ml
Dunamu-mlは、LLMと非パラメトリック手法(BM25)を融合し、質問と回答のペアを生成して検索精度を高めました。50%のスコアを達成し、柔軟なデータ補完アプローチが強みです。
5位: Papelo
Papeloは、マルチホップエビデンス追求を採用し、追加の質問を生成しながら証拠を収集する独自の方法を使用しました。48%のスコアを記録し、複雑な証拠探索に対応しました。
自動ファクトチェック技術の考察
1. 少数クラスへの対応力不足
自動ファクトチェックの現在のシステムが直面する大きな課題の一つは、「Not Enough Evidence」や「Conflicting Evidence」のような少数クラスへの対応力不足です。これらのクラスはデータセット内でも発生頻度が低いため、モデルが十分に学習できず、予測精度が低くなる傾向にあります。
この問題は、上位5チームすべてに共通しており、特に「Conflicting Evidence」はファクトチェックの質を左右する重要な要素であるにもかかわらず、予測が困難です。こうした課題を克服するには、少数クラスを含む多様なデータセットを構築したり、それらに特化した学習アルゴリズムを開発する必要があります。
2. 計算コストと効率性
現在の多くのファクトチェックシステムでは、大規模言語モデル(LLM)を使用しています。特にGPT-4Oのようなモデルは、推論能力が高い一方で、コストが非常に高いのが現実です。例えば、TUDA_MAIのシステムでは1つの主張を処理するのに約0.46ドルのコストがかかるとされています。
計算コストの高さは、システムの大規模運用における障壁となります。この問題に対応するため、軽量なモデルを組み合わせたハイブリッドなシステムや、タスクに特化した効率的なモデルの開発が求められています。
3. 証拠収集の正確性と網羅性
ファクトチェックの信頼性を確保するには、正確で網羅的な証拠収集が不可欠です。しかし、現在のシステムでは、証拠を収集する際にいくつかの制限が存在します。例えば:
- ウェブスクレイピングの失敗により、重要な証拠を取得できない。
- スニペットや断片的な情報に依存しており、十分な文脈を得られないケースがある。
- Dunamu-mlのようにYouTubeのトランスクリプトやPDFのデータを取り込む工夫がなされていても、情報源の多様性には限界がある。
これらの課題を解決するには、ウェブ上の多様なデータソースに対応できる堅牢な証拠収集機能の開発が必要です。
4. データセットの限界
多くのチームが指摘しているように、AVERITECデータセットは約3,000件の主張しか含まれておらず、モデルを十分にトレーニングするにはデータが不足しています。また、英語のみを対象としているため、多言語対応が必要な現実世界の問題には対応しきれていません。
この問題に対応するには、より大規模で多様性のあるデータセットを構築する必要があります。特に、多言語や異なる文化圏でのファクトチェックに対応するデータセットの拡充が求められます。
5. 人間との協働の重要性
完全な自動化には限界があり、人間との協働が重要です。現在のシステムでは、生成された証拠や判定結果を人間が確認することで、誤判定のリスクを軽減する仕組みが求められています。また、システムが提供するエビデンスの説明可能性を高めることで、透明性を確保することも重要です。


コメント
I never considered of that before; your point of view is mind-stimulating.
This site is a great resource for anyone interested in learning about a variety of subjects. Thanks for all that you do.
I always emailed this weblog post page to all
my associates, for the reason that if like to read it after that my friends will too.
Spot on with this write-up, I absolutely feel this web site needs much more attention. I’ll
probably be back again to read through more, thanks for the
advice!
Thanks for any other informative website. The place else
could I get that kind of info written in such an ideal method?
I have a undertaking that I’m just now running on, and I have been at
the look out for such info.
Werden Sie Teil unserer Community und erhalten Sie die neuesten Boni und Aktionen direkt in Ihren Posteingang.
Jeder zumindest 18-jähriger Besucher hat die
Möglichkeit, eine Vielzahl von Spielautomaten, Jackpot- und Tischspielen mit erstklassigen Live Dealern auszuprobieren. Nachdem
Ihre Reise nach Wien ist zu Ende, finden Sie problemlos die
beliebten Spielangebote in online Version. Beim Tropical Stud spielen Sie nicht gegen die anderen Spieler am Tisch, sondern nur gegen die Bank.
Klassisches Black Jack können Sie im ersten Stock
des Casino Wiens an vier Tischen spielen.
Daher sollten Sie sich im Voraus überlegen, wo Sie spielen, Ihr
Glück auf die Probe stellen oder wahres Können zeigen wollen. Hier hat jeder Gast
die Möglichkeit, Poker Casino Wien zu spielen, aber
auch viele andere Spiele. Um in diesem Casino spielen zu können,
benötigen Sie zumindest eine Mindesteinzahlung. Erstens
bietet das Film Casino Wien eine erstaunliche Auswahl an Glücksspielunterhaltung.
References:
https://online-spielhallen.de/die-kingmaker-casino-mobile-app-ihr-konigliches-spielvergnugen-fur-unterwegs/
Zum Beispiel, ab 20 € Gewinn mit dem Spielen aufzuhören oder zu Echtgeld zu wechseln, wenn der Bonus ausgeschöpft ist.
Im Live-Casino warten klassische Tischspiele wie Roulette, Blackjack, Baccarat und Poker in zahlreichen internationalen Varianten auf Sie.
Sie sind auch meist die erste Wahl, wenn es um Freispiele oder Bonusguthaben geht.
Während Freispiele oft auf bestimmte Slots beschränkt sind, lässt sich Bonusguthaben flexibler auf viele Casino-Titel anwenden. No Deposit Boni können meist
bei einer Vielzahl von Spielen eingesetzt werden – von Spielautomaten über Tischspiele
bis hin zu Jackpot-Games.
Umsatzbedingung – Sie geben an, wie oft
du den Betrag spielen musst, bevor du dir die Gewinne auszahlen lassen kannst.
Es gibt immer wieder neue Aktionen mit weiteren Slots, wenn du einen bestimmten Automaten kostenlos spielen möchtest, lohnt es sich
daher, immer mal wieder zu suchen. Mit Freispielen kannst
du kostenlos im Casino spielen ohne Einzahlung. Dafür hat man aber selbst die Wahl, welches Spiel man mit dem Guthaben spielen möchte.
Außerdem sind mit Freispielen im Vergleich zu der Höhe von üblichen Bonusguthaben mehr Drehungen üblich.
Für das Online Casino ist der Bonus ohne Einzahlung eine der vielen Marketing-Optionen,
mit denen man versucht, neue Kunden zu gewinnen.
Manchmal müssen Sie ihn aktivieren oder einfach ein Spiel starten, um die Freispiele freizuschalten. Derzeit können Sie sich bei vielen Online-Casinos Freispiele oder Gratis-Guthaben sichern. In einigen Fällen ist ein exklusiver Promo-Code erforderlich, um den Bonus ohne Einzahlung zu erhalten.
Nach der Anmeldung wird das Gratis-Spielguthaben oder
die Freispiele automatisch Ihrem Konto gutgeschrieben. Um den beworbenen Bonus ohne Einzahlung zu erhalten,
müssen Sie lediglich ein Konto bei einem Casino Ihrer
Wahl erstellen.
References:
https://online-spielhallen.de/umfassende-betrachtung-des-vulkan-vegas-cashback-programms/
Our team handles enquiries about deposits, withdrawals, bonus terms, and technical difficulties with games or website functionality.
Our live chat support operates continuously to provide instant assistance with account queries, game issues, and payment concerns.
Level Up Casino features over 7,000 casino games from 50+ software providers,
with an extensive focus on premium pokies and live dealer experiences.
Whether you need help with your account, have questions about
our games and promotions, or require any other support, our dedicated team is just a click or
call away. As one of the premier online casinos in Australia, casino offers a compelling blend of advantages and
considerations for local players.
The casino’s jackpot winners often share positive experiences regarding prize payouts and verification processes.
Level Up Casino has built a solid reputation among Australian players since launching in 2020, with ratings based on over
2,195 community member votes and feedback from 84 real players.
Our table games section includes multiple variants
of blackjack, roulette, and baccarat. We feature progressive slots
with massive jackpots alongside video poker variants for strategic
players. Our extensive collection spans all major game categories with titles from industry giants like
NetEnt, Microgaming, and Pragmatic Play.
References:
https://blackcoin.co/minimum-deposit-casino-sites-with-payid/
Our security protocols monitor account activity for
suspicious behaviour and implement automatic safeguards when irregular patterns are detected.
Account verification requires valid identification and proof of address before withdrawals can be processed.
Our platform implements advanced encryption technology to safeguard personal and financial data during all transactions.
Our VIP programme includes mobile-exclusive rewards and faster point accumulation for app users.
We’ve optimised the casino app to perform consistently across various device specifications.
Level Up Casino supports a wide range of iOS and Android
devices with seamless compatibility across different screen sizes and
operating system versions.
With over 50 software providers including NetEnt, Microgaming,
and Evolution Gaming, players consistently find engaging content.
The casino’s established presence since 2020 has allowed Australian players to build
trust through consistent positive experiences.
The casino’s minimum withdrawal of $10 and maximum daily limit of $3,
000 accommodate both casual and high-roller players effectively.
The casino’s 4.4-star Trustpilot rating reflects genuine satisfaction from
verified players who appreciate the platform’s reliability.
You can enjoy a wide selection of games, including a massive library
of online pokies (slots), classic table games (Blackjack, Roulette,
Baccarat, Poker), immersive live dealer games,
and fast-paced crash games. LevelUp Casino makes financial transactions easy and convenient for Australian players, supporting
both traditional and modern payment solutions, including popular cryptocurrencies.
Level Up Casino supports multiple banking options for deposits
and withdrawals, including credit/debit cards, e-wallets, bank transfers,
and cryptocurrencies.
References:
https://blackcoin.co/we-tested-50-aussie-online-casinos-these-paid-real-money/
When selecting an online casino, it’s essential to consider the types of promotions available.
This helps us make sure every platform we show is one of the
top online casino Australia sites. Wondering where your next favourite place to gamble online for real
money might be? Trustworthy casinos are regularly audited by independent third parties to confirm the fairness of their
games.
Weekly reloads and slot tournaments keep the action going well past the initial bonus.
Baccarat fans enjoy high RTP tables, while crypto users get instant deposits with zero fees.
Make sure to check your local laws before playing.
Thanks for reading and remember to play responsibly!
Our team’s favourite turned out to be CrownSlots, but it’s different strokes for different folks, so don’t hesitate to check our list again and make a
choice based on your preferences.
References:
https://blackcoin.co/monte-casino-overview/
Professional dealers host games in real-time, creating an authentic casino atmosphere from the comfort of your home.
VIP players receive even more benefits, including a personal VIP manager, customized bonuses, higher limits, and faster withdrawals.
With over 7,000 games and monthly cashouts exceeding A$8
million, SkyCrown has proven itself as a trusted gaming destination for Australian players.
SkyCrown Casino brings you an amazing gaming adventure with huge bonuses, thousands of games,
and lightning-fast payouts. Yes, Skycrown fully supports AUD
for deposits, withdrawals, and gameplay, so you won’t need to deal
with currency conversions or extra fees.
In some cases, you can turn to VPN casinos to access games that are otherwise restricted in your region.
By this line of thinking, playing at online casinos
as an individual isn’t illegal in Australia. Look for games with
lower minimum bet requirements to get more spins and
rounds out of your current budget at the best Australian online casino.
Leading casinos are compatible with online bank transfers for
deposits and payouts. Popular e-wallets such as NeoSurf, Interac,
and Skrill are used to make deposits and receive payouts at AU online casinos.
The SkyCrown Casino icon will appear on your device’s home screen, ready for you to start gaming!
Open your mobile browser and visit the SkyCrown Casino website.
Follow our step-by-step guide to ensure a seamless experience.
Downloading the latest version of the SkyCrown bonus
apk is a simple process with no complex steps and
is completely free. Enjoy seamless gaming across multiple platforms
with full accessibility. Enjoy lightning-fast loading
times and stable performance across all devices.
I think the admin of this web page is really working hard
in favor of his site, because here every data is quality based material.
online casinos paypal
References:
https://wsurl.link/
paypal casino usa
References:
http://www.grapvocar.site/bbs/board.php?bo_table=free&wr_id=211
us poker sites that accept paypal
References:
https://jobsinodisha.org/companies/paypal-casinos-2025-best-casino-sites-that-accept-paypal/
online casino real money paypal
References:
https://www.joblagbe.com/employer/40-best-australian-online-casinos-for-real-money-in-december-2025/
online casinos that accept paypal
References:
https://hirenhigher.co.nz/companies/die-besten-online-casino-mit-paypal-im-test-2025/
online casino for us players paypal
References:
https://job.dialnumber.in/profile/sung90m145914
Wir empfehlen Dir, einige der erstaunlichen Bonus Angebote ohne Einzahlung online auszuprobieren. Ein Registrierungsbonus ohne Einzahlung hat für beide Seiten Vorteile. Mobile Online Casino Glücksspiele werden immer beliebter, und die besten Online Casinos bieten aufgrund der neuen Technologien auch mobil das beste Spielerlebnis. Einen Bonus ohne Einzahlung kannst Du Dir nicht als Bargeld auszahlen lassen. Wenn Du einen Online Casino Echtgeld Bonus ohne Einzahlung beanspruchst, ist es immer wichtig zu wissen, dass dieser mit einer Reihe von Geschäftsbedingungen verbunden ist. In einigen Casinos musst Du Dich zuerst an den Kundendienst wenden, um den Bonus zu erhalten, oder es kann auch ab und zu sein, dass Du einen bestimmten Bonus Code eingeben musst. Online Casinos legen Bedingungen (häufig Wettanforderungen) fest, um sicherzustellen, dass sie eine Gegenleistung erhalten.
Jeder Spieler sollte wissen, dass ein Geldbonus kein einfaches Geschenk ist. Eine verbesserte Methode zur Freischaltung von Bonusangeboten ist der Bonuslink. Du kannst online oder im Fernsehen Werbung für Casino Gutschein Bonus Codes sehen, die aus Buchstaben- und/oder Zahlenfolgen bestehen. Der Vorteil dieser Belohnungsart ist, dass Sie bei Erfüllung der Umsatzbedingungen tatsächlich Geld gewinnen können. Sie können jedes Spiel schon unter 10 Euro genießen und dabei echtes Geld gewinnen.
References:
https://s3.amazonaws.com/onlinegamblingcasino/casino%20thessaloniki%20greece.html
References:
Palace of chance
References:
https://sciencewiki.science/wiki/Speed_Limits_Fees
References:
Test and anavar before and after
References:
https://digitaltibetan.win/wiki/Post:Anavar_Before_and_After_Results
References:
Taking anavar before and after
References:
https://www.youtube.com/redirect?q=https://candy96.fun
References:
Gsn slots
References:
https://marvelvsdc.faith/wiki/WD40_Casino_Review_Bonus_Codes_2026
References:
No deposit poker
References:
https://hack.allmende.io/s/40GjNUOQe
male enhancement trial offer
References:
https://www.adpost4u.com/user/profile/4238736
brain enhancing drugs for sale
References:
https://may22.ru/user/donaldkevin55/
References:
Women anavar before after
References:
https://gpsites.stream/story.php?title=oxandrolon-anavar-einsatz-wirkung-im-sport-6
References:
Blood work before and after anavar hdl ldl
References:
https://currie-lykke.technetbloggers.de/anavar-cycle-guide-2025-dosage-results-side-effects-and-stacks
prednisone weight lifting
References:
https://lovebookmark.win/story.php?title=pfizer-genotropin-pen-for-sale-in-the-uk-buy-pfizer-genotropin-uk
References:
Anavar female before and after reddit
References:
http://pattern-wiki.win/index.php?title=griffinfoldager8794
%random_anchor_text%
References:
https://freebookmarkstore.win/story.php?title=trump-warned-hell-need-to-cough-up-700billion-for-greenland-ahead-of-proposal
is there any legal steroids
References:
https://yogicentral.science/wiki/Meilleur_Booster_Testostrone_en_pharmacie_naturel_avis
benefits of steroids in sports
References:
https://oren-expo.ru/user/profile/795525
References:
Anavar only cycle before and after
References:
http://community.srhtech.net/user/yogurteggnog8
References:
Nooksack casino
References:
http://stroyrem-master.ru/user/basedrive5/
References:
Casino barriere lille
References:
https://funsilo.date/wiki/Candy96_Reviews_Read_Customer_Service_Reviews_of_candy96_com
References:
Phoenix casino
References:
http://semdinlitesisat.eskisehirgocukduzeltme.com/user/georgeleg30/
References:
Harrah’s cherokee casino
References:
https://socialbookmark.stream/story.php?title=faq-le-risposte-alle-domande-piu-frequenti-candy-italia
%random_anchor_text%
References:
http://theconsultingagency.com/members/parkpine07/activity/1393/
is buying steroids online illegal
References:
https://linkvault.win/story.php?title=verschreibungspflichtige-oder-rezeptfrei-erhaeltliche-medikamente-im-ausland-oder-online-kaufen
%random_anchor_text%
References:
https://nerdgaming.science/wiki/Legale_Drogen_I_Definiton_Wirkung_Risiken_Behandlung
what does androgenic mean
References:
https://coolpot.stream/story.php?title=come-procurarsi-testosterone-senza-ricetta
References:
Grand falls casino
References:
https://lau-fleming-2.thoughtlanes.net/3-ways-to-check-your-payment-history-on-candy-crush
References:
Poliqon
References:
https://bandori.party/user/384369/sugarafrica6/
References:
Thief river falls casino
References:
https://rentry.co/xem8yww7
References:
Online casino malaysia
References:
https://notes.io/eim9A
sustanon deca dianabol cycle
References:
http://okprint.kz/user/timersnake03/
anabolic steroid classification
References:
https://sportpoisktv.ru/author/refundvision0/
how steroids affect the body
References:
https://farmsolutionsja.com/members/jeffcup78/activity/21815/
cutting agent bodybuilding
References:
https://livebookmark.stream/story.php?title=buy-winstrol-oral-stanozolol-50-mg-online-legal-anabolic-steroids-in-usa
References:
Northern quest casino spokane
References:
https://hedge.fachschaft.informatik.uni-kl.de/s/dwNT6HNoo
References:
Grand online casino
References:
https://gaiaathome.eu/gaiaathome/show_user.php?userid=1831465
References:
Playboy casino
References:
https://numberfields.asu.edu/NumberFields/show_user.php?userid=6492939
References:
Lucky nugget mobile casino
References:
https://www.tikosatis.com/index.php?page=user&action=pub_profile&id=510696
References:
Crazy vegas casino
References:
https://pattern-wiki.win/wiki/Die_besten_Online_Poker_Boni_ohne_Einzahlung_2026
References:
Venetian casino macau
References:
https://elclasificadomx.com/author/tiecrayon03/
References:
Three rivers casino
References:
https://numberfields.asu.edu/NumberFields/show_user.php?userid=6498067
References:
Roulette secrets
References:
https://marvelvsdc.faith/wiki/Best_PayID_Casino_2025_Top_Online_Casinos_With_PayID
References:
Online casino sverige
References:
http://premiumdesignsinc.com/forums/user/latexknight24/
before and after steroids 6 weeks
References:
https://bom.so/oNPoxq
References:
Europa casino
References:
https://linkagogo.trade/story.php?title=best-instant-payout-casinos-australia-2026-fast-withdrawal-sites
Thank you, I’ve recently been looking for info about this topic for ages and yours is the greatest I have discovered so far. But, what about the bottom line? Are you sure about the source?
are steroids legal in uk
References:
https://swaay.com/u/rophernrovt48/about/
how much testosterone do bodybuilders take
References:
https://onlinevetjobs.com/author/quinceevent0/
steroids drugs
References:
https://chessdatabase.science/wiki/Can_You_Buy_Clenbuterol_Legally_A_Comprehensive_Guide
where to order testosterone online
References:
https://lovebookmark.win/story.php?title=winstrol-review-cycle-benefit-dosage-cost-and-alternative-everything-you-need-to-know
Hi I am so glad I found your blog page, I really found you by error,
while I was browsing on Digg for something else, Anyhow I am here now and would just like
to say thanks a lot for a fantastic post and a all round enjoyable blog (I also love the
theme/design), I don’t have time to look over it all at the moment but I have saved it and also included your RSS feeds, so when I have time I will be
back to read much more, Please do keep up the awesome job.
cutting cycle supplements
References:
https://bookmark4you.win/story.php?title=wo-bekommt-man-anavar-24-7-is
physical side effects of steroids
References:
https://graph.org/Clenbuterol-Nebenwirkung–Wechselwirkung-02-05
buy anadrol online
References:
https://urlscan.io/result/019c2f09-58f4-74bd-a0dc-0960ace8e3d1/
where to order steroids
References:
http://karayaz.ru/user/radishturn7/
top selling legal steroids
References:
https://korsgaard-vick-2.technetbloggers.de/buy-tren-ace-max-trenbolone-acetate-for-sale-at-au-roids-to
gnc legal steroids
References:
http://pattern-wiki.win/index.php?title=junkershepherd8329
best injectable steroids for cutting
References:
http://premiumdesignsinc.com/forums/user/coveremery39/
steroids to get ripped
References:
https://dreevoo.com/profile.php?pid=1066674
muscle building pills like steroids
References:
http://jobboard.piasd.org/author/detailskiing8/
dangers of steriods
References:
http://ezproxy.cityu.edu.hk/login?url=https://suntana.com/art/?buy_hgh_37.html
santa rosa casino
References:
https://www.sommer-architekt-warstein.de/VPB-Expertenrat;focus=TKOMSI_com_cm4all_wdn_Flatpress_22800952&frame=TKOMSI_com_cm4all_wdn_Flatpress_22800952?x=entry:entry250319-115544%3Bcomments:1
talking stick casino
References:
https://xypid.win/story.php?title=online-casino-games-real-money-top-13-beste-online-casinos-fuer-deutsche-2026-graz
casino la toja
References:
https://md.un-hack-bar.de/s/nw5ffxxIRB
william hill casino login
References:
https://able2know.org/user/cobwebdonald28/
ottawa quebec
References:
https://dickerson-lunde-3.technetbloggers.de/casinos-mit-schneller-auszahlung-sofort-gewinne-2026
online casino sites
References:
https://urlscan.io/result/019c88ee-69ed-70fe-89c9-b756b10183c5/
diamond jo casino dubuque
References:
https://etuitionking.net/forums/users/ariesfear8/
ct casinos
References:
https://www.instapaper.com/p/17492716
kewadin casino st ignace
References:
https://firsturl.de/O69G4Za
hoosier park casino
References:
https://xn--41-4lcpj.xn--j1amh/user/pingwave6/
california indian casinos
References:
https://adsintro.com/index.php?page=user&action=pub_profile&id=834923
casino william hill
References:
https://hedge.fachschaft.informatik.uni-kl.de/s/-s4DKlLu3
winning at slots
References:
https://bookmarkstore.download/story.php?title=promos-mr-o-casino-blog
walking dead time slot
References:
https://justbookmark.win/story.php?title=galaxy-96-casino-review-australia-bonuses-games-banking
I have read some good stuff here. Certainly worth bookmarking for revisiting. I surprise how much effort you put to make such a magnificent informative website.
%random_anchor_text%
References:
https://www.tikosatis.com/index.php?page=user&action=pub_profile&id=571643
%random_anchor_text%
References:
https://www.giveawayoftheday.com/forums/profile/1666322
anabolic steroids effects on males
References:
https://atesoglusogutma.com/user/helenlisa5/
pachislo slot machine
References:
https://homedecorideas24.co.uk/nomadic-army-crossword-clue/
%random_anchor_text%
References:
https://www.instapaper.com/p/17497646
ultimate texas holdem
References:
https://wspomozycielka-lodz.pl/?p=907
best online casino usa
References:
https://wspomozycielka-lodz.pl/?p=745
lady luck casino nemacolin
References:
https://fashionandtravelreporter.com/buzios-os-principais-pontos-turisticos-da-cidade/
rushmore casino
References:
https://animallovergifts.com/loveyourpetday/
shoshone rose casino
References:
https://vivek-desai.com/pages/page-left-sidebar/
gnc cutting supplements
References:
https://medibang.com/author/27868048/
pill to build muscle
References:
https://fravito.fr/user/profile/2194230
steroid use side effects
References:
https://md.chaosdorf.de/s/nSSENdwlTZ
References:
Blue diamond stakes
References:
https://doc.adminforge.de/s/M7Q4vQKrVm
References:
Penis on steroids
References:
https://www.fightdynasty.com/companies/naposim-10-vermodje-alpha-pharma-steroids-on-line-sales-of-legal-steroidspurchase-naposim-online-openwaterwiki/
References:
Dangers of anabolic steroids
References:
https://blomberg-bogensport.de/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_5334430&path=&frame=STRATP_com_cm4all_wdn_Flatpress_5334430?x=entry:entry180903-201845%3Bcomments:1
References:
Arnold schwarzenegger and steroids
References:
https://www.st-toenis-erleben.de/STARTSEITE/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_22934050&frame=STRATP_com_cm4all_wdn_Flatpress_22934050?x=entry:entry200328-131356;comments:1
References:
Illegal steroids online
References:
https://www.fsv-kappelrodeck.de/;focus=TKOMSI_com_cm4all_wdn_Flatpress_22523288&path=?x=entry:entry250518-192130%3Bcomments:1
References:
Steroid transformation
References:
https://doriswimmer.de/VorderRenteBLOG/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_48109594&frame=STRATP_com_cm4all_wdn_Flatpress_48109594?x=entry:entry241213-142235;comments:1
References:
Is it safe to take steroids
References:
https://www.aktive-wirtschaft-ditzingen.de/MITGLIEDER-NEWS/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_13827129&path=&frame=STRATP_com_cm4all_wdn_Flatpress_13827129?x=entry:entry190504-093910%3Bcomments:1
References:
The effects of anabolic steroids
References:
https://engelswege.com/Blog/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_8442873&path=&frame=STRATP_com_cm4all_wdn_Flatpress_8442873?x=entry:entry170322-185856%3Bcomments:1
References:
What type of drug are steroids
References:
https://www.whitebloom.fi/Ajankohtaista/index.php/;focus=PLNT15_com_cm4all_wdn_Flatpress_404405&path=&frame=PLNT15_com_cm4all_wdn_Flatpress_404405?x=entry:entry231020-175238%3Bcomments:1
References:
Why do bodybuilders use steroids
References:
http://43.143.175.54:3000/adacowell2820
References:
Is a steroid a hormone
References:
https://www.fcla.de/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_38266970&path=&frame=STRATP_com_cm4all_wdn_Flatpress_38266970?x=entry:entry260112-175639%3Bcomments:1
References:
Where to get winstrol
References:
https://servus-nachbar.at/Neuigkeiten/index.php/;focus=W4YPRD_com_cm4all_wdn_Flatpress_7491266&path=&frame=W4YPRD_com_cm4all_wdn_Flatpress_7491266?x=entry:entry240507-143256%3Bcomments:1
References:
What is the safest steroid for building muscle
References:
https://classifieds.ocala-news.com/author/baysex8
References:
Banque casino fr espace client
References:
https://ondashboard.win/story.php?title=willkommensbonus-200-
References:
Negative side effects of steroids
References:
https://www.fcla.de/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_38266970&path=&frame=STRATP_com_cm4all_wdn_Flatpress_38266970?x=entry:entry250120-090734%3Bcomments:1
References:
Ulisses jr steroids
References:
https://gitee.planhomecloud.cn/mitchcatani683/mitch2019/wiki/Spasmo-Mucosolvan%C2%AE-20Stk-Schleiml%C3%B6ser-%26-krampfl%C3%B6send-bei-Husten-20-St-mit-dem-E-Rezept-kaufen
References:
How to make steroid powder
References:
http://47.100.212.83:3000/murraycastles
References:
Most anabolic supplements
References:
http://111.21.163.58:2321/deidre40797139/4565976/wiki/Spiropent-Tabletten%3A-Dosierung%2C-Nebenwirkung-%26-Wirkung
References:
Are steroids legal in the us
References:
http://111.21.163.58:2321/melainehutchis
References:
Steroids to lose weight fast
References:
https://gitea.alexandermohan.com/lawrencelieb5/175.27.229.2112019/wiki/Leitfaden-zur-Dosierung-von-CBD-%C3%96l-f%C3%BCr-Anf%C3%A4nger-2026
References:
Creatine illegal
References:
https://gratisafhalen.be/author/winesquash0/
References:
Best supplement stacks for muscle gain
References:
https://pad.geolab.space/s/cXIpM1NwP
References:
Casino jackpot
References:
http://uchkombinat.com.ua/user/alibiangle89/
References:
Casino ontario
References:
https://pediascape.science/wiki/Comprehensive_Guide_to_WinSpirit_Casino_Licensing_in_Australia
References:
Bodybuilding supplements review
References:
http://101.43.238.71:3000/jefferyleedom
References:
Kai green steroids
References:
https://git.hanumanit.co.th/kathieroderick
References:
Designer steroids for sale
References:
https://music.wzsipku.cn/cedricdisney91
В этой статье вы найдете познавательную и занимательную информацию, которая поможет вам лучше понять мир вокруг. Мы собрали интересные данные, которые вдохновляют на размышления и побуждают к действиям. Открывайте новую информацию и получайте удовольствие от чтения!
Подробнее можно узнать тут – https://vivod-iz-zapoya-2.ru/
References:
Tongkat Ali Testosteron steigern
References:
http://karayaz.ru/user/deskhook51/
References:
Jon skywalker steroids
References:
http://187.216.152.151:9999/adrienewilks23
References:
Steroid to lose weight fast
References:
https://maxtravelagencys.com/employer/how-to-do-an-intramuscular-injection-of-testosterone-glutes-deltoids-quads/
References:
Muscle growth pills gnc
References:
http://43.139.2.237:3000/priscillaosbur
References:
The rock uses steroids
References:
https://fanajobs.com/profile/eldenhowerton1
References:
Corticosteroid drugs are very useful for
References:
https://hero-cloud-stg-code.cnbita.com/iolagrainger2/iola1997/wiki/The-Largest-Online-Healthcare-Clinic-in-North-America%2C-Affordable-Pricing%2C-Enjoy-Increased-Energy-%26-Focus%21
References:
Where to buy gear bodybuilding
References:
http://play.kkk24.kr/bbs/board.php?bo_table=online&wr_id=343674
References:
Anabolics.com reddit
References:
http://116.198.44.217:8040/floydhartin534
Effectively voiced certainly! .
References:
https://carver-nicolaisen-2.thoughtlanes.net/instant-casino-freispiele-entdecken-cashback-bonus-promo-code
References:
Instant Casino Live Chat
References:
http://adrestyt.ru/user/offervinyl9/
References:
Instant Casino Freispiele
References:
http://csmouse.com/user/versemoat3/
References:
Instant Casino Freispiele
References:
https://topbookmarks.cloud/item/595664
References:
Instant Casino Auszahlung sofort
References:
https://www.udrpsearch.com/user/brassoval98
References:
Instant Casino mobile spielen
References:
https://zumpadpro.zum.de/nJhOgGnDS0a0hkCx9d79AA/
References:
Instant Casino Slots
References:
https://enouvelles.top/item/596132
References:
Instant Casino App
References:
https://lovebookmark.win/story.php?title=instant-casino-mobile-app-instant-auf-handy-spielen
References:
William hill app android
References:
https://pattern-wiki.win/wiki/Winspirit_Real_Money_2025
References:
Instant Casino App Android
References:
https://rentry.co/g5t5wktb
References:
Top online casinos
References:
https://telegra.ph/Winspirit-Affiliates-Program-Reviews-04-01
References:
Instant Casino Treueprogramm
References:
https://graph.org/Willkommensbonus-200-04-04
References:
Echtgeld casino erfahrungen
References:
https://scientific-programs.science/wiki/Top_10_Echtgeld_Casinos_Deutschland_2026_Testsieger_Expertenmeinung
References:
Winner casino mobile
References:
https://topbookmarks.xyz/item/483037
References:
Casino mit echter auszahlung
References:
https://lichnyj-kabinet-vhod.ru/user/mailpilot16/
References:
Where can i get anavar
References:
https://jobcopeu.com/employer/7-best-sites-to-buy-testosterone-online-in-2026/
References:
Interesting facts about anabolic steroids
References:
https://sponsorjobs.com.au/employer/top-8-best-growth-hormone-supplements-in-2026/
References:
Bodybuilders before and after steroids
References:
https://www.complete-jobs.com/employer/human-growth-hormone-for-athletes-buy-legal-hgh-for-sports-in-europe
References:
What is anabolic steroids made of
References:
https://guateempleos.com/companies/somatropin-191aa-150-iu-kit-usa-domestic-www-ecbt-org/
References:
Winstrol muscle gains
References:
https://jobs.atlanticconcierge-gy.com/employer/17-natural-appetite-suppressants-for-weight-loss/
References:
Testosteron Supplemente sinnvoll
References:
https://penn-junker-3.technetbloggers.de/boosting-testosterone-natural-and-medical-approaches
References:
Are steroids bad for you
References:
http://pattern-wiki.win/index.php?title=robinsonkrogsgaard9019
References:
Best gnc supplements for muscle building
References:
https://historydb.date/wiki/Clenbuterol_Nebenwirkung_Wechselwirkung
References:
As part of the omnibus crime control act of 1990
References:
https://platform.joinus4health.eu/forums/users/virgodaniel8/
References:
Closest legal supplement steroids
References:
https://pattern-wiki.win/wiki/Anavar_Deutschland_Legal_Alles_was_Sie_ber_legale_Steroide_wissen_mssen
cialis commercial cialis prescription cialis or viagra
References:
Best steroid to build muscle
References:
https://christiansen-lemming-3.blogbright.net/eleven-einfache-tipps-um-das-wachstumshormon-hgh-naturlich-zu-steigern-2025
References:
Muscle building pills gnc
References:
https://yogaasanas.science/wiki/Winstrol_Anabolic_steroids_Side_Effects_Uses_Dosage_Interactions_Warnings
References:
Getting off steroids side effects
References:
https://md.un-hack-bar.de/s/bLzEITYRZQ
References:
Best post cycle therapy for steroids
References:
https://enregistre-le.site/item/413822
References:
graph.org
References:
https://classifieds.ocala-news.com/author/chainraft2
References:
Do legal steroids really work
References:
https://watchpants0.bravejournal.net/steroide-kaufen-deutschland-laborgepruft-eu-versand
References:
Best bulking steroids
References:
https://menwiki.men/wiki/Hgh_Kaufen_Norditropin_Simplexx_Novo_Nordisk_Somatropin
References:
Most common steroid
References:
https://www.24propertyinspain.com/user/profile/1160738
References:
Buy steroid online
References:
https://222mon.anidub.bet/user/brandypig2/
References:
Online Casino Echtgeld legal
References:
https://yogicentral.science/wiki/Online_Casino_Echtgeld_2026_Beste_Anbieter_im_Vergleich
References:
Online Casino Echtgeld seriös
References:
https://bookmarks4.men/story.php?title=top-online-casinos-mit-merkur-echtgeld-spielen-2026
Основной этап включает постановку капельницы с растворами, направленными на выведение токсинов, восстановление водно-солевого баланса и нормализацию работы внутренних органов. В состав могут входить витамины, седативные препараты, гепатопротекторы и кардиопротекторные средства. В случае ломки и снятия симптомов зависимости у больного, все препараты подбираются индивидуально, чтобы минимизировать дискомфорт и ускорить восстановление.
Получить дополнительную информацию – [url=https://narkolog-na-dom-samara-6.ru/]нарколог на дом вывод[/url]
Суть капельницы заключается в том, чтобы быстро ввести в организм необходимые растворы, которые помогают восстановить водно-солевой баланс, очищают организм от токсинов, ускоряют обмен веществ и снижают нагрузку на внутренние органы. Врачи-наркологи используют специальные составы, которые включают в себя жидкости, электролиты, витамины и лекарственные средства для снятия симптомов похмелья.
Подробнее тут – [url=https://kapelnicza-ot-pokhmelya-nizhnij-novgorod-2.ru/]капельница от похмелья цена[/url]
Перед постановкой капельницы специалист оценивает общее состояние пациента, измеряет давление, пульс, уточняет анамнез и возможные противопоказания. На основании этих данных формируется индивидуальный состав, который обеспечивает не только устранение симптомов похмелья, но и безопасное восстановление организма.
Ознакомиться с деталями – http://kapelnicza-ot-pokhmelya-samara-7.ru
Особую роль на первом этапе играет диагностика: важно выявить не только тип наркотика, но и наличие сопутствующих расстройств, стадию зависимости, мотивационное состояние пациента. От этого зависит, будет ли выбрана амбулаторная или стационарная форма лечения, какие методы будут применяться.
Ознакомиться с деталями – http://lechenie-narkomanii-murmansk0.ru/czentr-lecheniya-narkomanii-marmansk/
Первые положительные изменения обычно появляются уже через 15–20 минут после начала капельницы. Уменьшается головная боль, снижается чувство тошноты, стабилизируется давление и пульс. К концу процедуры большинство симптомов становится значительно менее выраженными.
Изучить вопрос глубже – https://kapelnicza-ot-pokhmelya-samara-8.ru/
Капельница от похмелья — это внутривенное введение специально подобранных растворов, которые помогают ускорить выведение токсинов, восстановить водно-электролитный баланс и нормализовать обмен веществ. В состав капельницы могут входить различные компоненты, такие как солевые растворы, витамины, глюкоза и препараты для детоксикации. Она особенно эффективна при последствиях запоя и хронического алкоголизма.
Узнать больше – [url=https://kapelnicza-ot-pokhmelya-nizhnij-novgorod.ru/]капельница от похмелья нижний новгород[/url]
References:
Online Casino Echtgeld Freispiele
References:
https://holm-hunter-5.technetbloggers.de/beste-echtgeld-casinos-2026-online-echtes-geld-gewinnen
References:
Echtgeld Casino Strategie
References:
https://pikidi.com/seller/profile/potatoinch4
References:
Clenbuterol kaufen Ohne Rezept
References:
https://historydb.date/wiki/Clenbuterol_as_PreWorkout_Key_Facts
Капельница от похмелья — это один из наиболее эффективных методов экстренной медицинской помощи, который позволяет быстро снять симптомы алкогольной интоксикации и восстановить организм после злоупотребления алкоголем. В наркологической клинике «Частный медик 24» в Самаре мы предоставляем услугу выезда нарколога на дом и капельной терапии для пациентов, испытывающих тяжёлые симптомы похмелья. Это удобный способ получить необходимую помощь без лишнего стресса, сохраняя анонимность и комфорт пациента.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-samara-1.ru/]капельница от похмелья цена[/url]
Срочная медицинская помощь на дому позволяет не только стабилизировать состояние пациента, но и начать его восстановление без стресса, связанного с поездкой в клинику. Врач приедет с необходимым оборудованием и медикаментами, чтобы провести все необходимые процедуры и помочь пациенту стабилизировать состояние в домашних условиях.
Узнать больше – [url=https://narkolog-na-dom-samara-2.ru/]врач нарколог на дом в самаре[/url]
Капельница от похмелья в Самаре с устранением симптомов интоксикации и контролем состояния в наркологической клинике «Частный медик 24»
Получить дополнительную информацию – [url=https://kapelnicza-ot-pokhmelya-samara-2.ru/]капельница от похмелья на дому в самаре[/url]
Для жителей Воронежа выезд нарколога на дом — это быстрый и удобный способ получить экстренную помощь. Когда человек переживает запой, а его физическое и эмоциональное состояние быстро ухудшается, наркологическая помощь на дому становится оптимальным решением. Врач приезжает и немедленно оценивает состояние пациента: проверяет его пульс, давление, частоту дыхания, уровень сознания и другие важные показатели. Это помогает составить точный план лечения, который будет направлен на восстановление организма, снятие токсинов и стабилизацию состояния пациента.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-voronezh-4.ru/]вызвать нарколога на дом[/url]
Критерий
Изучить вопрос глубже – http://narkologicheskaya-klinika-murmansk0.ru/chastnaya-narkologicheskaya-klinika-marmansk/
References:
Steroid transformation before and after
References:
https://graph.org/Order-Trenbolone-Buy-Safely-Online-04-15
References:
Trenbolone for sale
References:
https://watkins-reese-4.blogbright.net/find-trenbolone-for-sale
References:
Testosterongel rezeptfrei
References:
https://md.chaosdorf.de/s/CmtAj5PjCU
References:
Harrah’s casino tunica
References:
https://rentry.co/vx4p5coo
Запойное состояние сопровождается выраженной интоксикацией, нарушением сна, слабостью и тревожностью, что характерно для алкоголизма и различных форм зависимости. При этом самостоятельный выход из него часто затруднён из-за ухудшения самочувствия и отсутствия контроля над симптомами. Выезд нарколога позволяет быстро стабилизировать состояние человека и начать восстановление без дополнительной нагрузки, связанной с поездкой в клинику, а при необходимости вовремя определить показания к лечению в стационаре.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-9.ru/]вывод из запоя на дому цена санкт-петербург[/url]
Капельница от похмелья применяется, когда симптомы интоксикации становятся выраженными и мешают нормальной жизнедеятельности пациента. Основные показания для использования капельницы включают:
Получить дополнительные сведения – [url=https://kapelnicza-ot-pokhmelya-samara-1.ru/]капельница от похмелья анонимно в самаре[/url]
Вывод из запоя на дому — это медицинская помощь, направленная на стабилизацию состояния пациента без госпитализации. Такой формат позволяет начать лечение сразу после обращения и снизить нагрузку на организм, связанную с транспортировкой. В наркологической клинике «Частный медик 24» помощь оказывается с выездом врача, который проводит диагностику и подбирает терапию в зависимости от текущего состояния.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/[/url]
После оформления вызова нарколог приезжает к пациенту и проводит комплексную оценку состояния. Врач измеряет давление, частоту пульса, оценивает уровень сознания и выраженность симптомов. На основании полученных данных формируется план лечения, который реализуется сразу на месте.
Разобраться лучше – [url=https://narkolog-na-dom-nizhnij-novgorod.ru/]врач нарколог на дом[/url]
Показаниями к срочному выезду являются:
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-10.ru/]вывод из запоя на дому круглосуточно санкт-петербург[/url]
Запой и алкогольная интоксикация могут приводить к целому ряду опасных симптомов, таких как головная боль, слабость, тошнота, рвота, обезвоживание и психоэмоциональная нестабильность. Если не начать лечение вовремя, такие состояния могут привести к более серьезным осложнениям, включая сердечные проблемы, галлюцинации и даже опасные для жизни нарушения работы организма. С помощью нарколога на дому можно начать экстренную терапию прямо в момент ухудшения состояния, не затягивая с лечением и не тратя время на поездки в клинику.
Подробнее – [url=https://narkolog-na-dom-samara-2.ru/]нарколог на дом вывод самара[/url]
References:
Trenbolone acetate where to buy
References:
https://botdb.win/wiki/Get_Tren_UK_Safe_Sources_Guide
Нарколог на дом в Воронеже с лечением без очередей, выездом врача и анонимной помощью в наркологической клинике «Частный медик 24»
Разобраться лучше – [url=https://narkolog-na-dom-voronezh-4.ru/]врач нарколог на дом в воронеже[/url]
Домашний формат ценят не только за удобство. Он помогает начать лечение анонимно, без дороги, без ожидания и без лишнего стресса для пациента. Для многих семей именно выездной наркологическая маршрут становится первой точкой, с которой начинается более серьёзное восстановление: обсуждаются не только снятие острых симптомов, но и кодирование, реабилитация, повторная консультация, а при необходимости — и маршруты помощи при наркомании. Особенно это актуально, если человек употребляет давно, уже несколько лет сталкивается со срывами и сам замечает, что проблема перестала ограничиваться только плохим самочувствием после алкоголя.
Узнать больше – [url=https://narkolog-na-dom-voronezh-2.ru/]narkolog-na-dom-voronezh-2.ru/[/url]
В подобных случаях время играет против пациента. Чем дольше человек остаётся без осмотра, тем выше вероятность, что к обезвоживанию и интоксикации добавятся нарушения сна, истощение, вегетативный срыв и ошибки с лекарствами, которые были приняты «для успокоения» без понимания общей картины. В практике выездной службы именно экстренное реагирование помогает не допустить ухудшения и в короткие сроки вернуть ситуацию под медицинский контроль.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-voronezh.ru/]нарколог на дом воронеж[/url]
Капельница от похмелья в Екатеринбурге с медицинским контролем и поддержкой организма в наркологической клинике «Частный медик 24»
Получить дополнительную информацию – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-6.ru/]капельница от похмелья анонимно в екатеринбурге[/url]
Выбор наркологического стационара с комфортными условиями требует внимательного подхода, чтобы убедиться, что все аспекты лечения и реабилитации будут выполнены на высоком уровне. Важно учитывать не только медицинскую составляющую, но и то, как созданы условия для пациентов, их психологический комфорт и безопасность на всех этапах лечения. Также стоит учитывать цену за стационарное лечение с круглосуточным наблюдением, чтобы выбрать оптимальный вариант, соответствующий потребностям пациента и его бюджету.
Подробнее – [url=https://narkologicheskij-staczionar-sankt-peterburg-4.ru/]наркологическая клиника стационар в санкт-петербурге[/url]
Наркологический стационар в Санкт-Петербурге: круглосуточное лечение, детоксикация и наблюдение специалистов в комфортных условиях в наркологической клинике «Похмельная служба»
Узнать больше – [url=https://narkologicheskij-staczionar-sankt-peterburg.ru/]наркологическая помощь стационар санкт-петербург[/url]
Наркологический стационар с круглосуточным наблюдением в Санкт-Петербурге — это специализированное медицинское учреждение, предоставляющее помощь пациентам с зависимостью от алкоголя, наркотиков или других психоактивных веществ. В таких стационарах пациенты получают не только лечение, но и постоянное медицинское наблюдение, что значительно повышает безопасность и эффективность терапии. Круглосуточная поддержка специалистов позволяет предотвратить осложнения и быстро реагировать на изменения в состоянии пациента. В некоторых случаях, таких как запой или хронический алкоголизм, может быть рекомендован выезд на дом для оказания неотложной помощи, прежде чем пациент будет переведен в стационар.
Исследовать вопрос подробнее – [url=https://narkologicheskij-staczionar-sankt-peterburg.ru/]частный наркологический стационар санкт-петербург[/url]
Стационарное лечение в наркологическом стационаре дает целый ряд преимуществ, которые трудно переоценить, особенно в случае тяжелых зависимостей. Пребывание в стационаре позволяет сосредоточиться исключительно на восстановлении здоровья, не отвлекаясь на внешние факторы, и получать постоянную помощь профессионалов. В некоторых случаях, в зависимости от состояния пациента, может потребоваться вывод из запоя, а также консультация специалистов, которые будут сопровождать пациента на протяжении года для долгосрочной реабилитации.
Углубиться в тему – [url=https://narkologicheskij-staczionar-sankt-peterburg-2.ru/]narkologicheskij-staczionar-sankt-peterburg-2.ru/[/url]
Капельница от похмелья — это эффективный способ снятия симптомов алкогольной интоксикации, который позволяет быстро восстановить организм после длительного употребления алкоголя. В наркологической клинике «Частный медик 24» в Екатеринбурге мы предлагаем капельную терапию, которая включает в себя комплекс препаратов для восстановления водно-электролитного баланса, выведения токсинов и нормализации состояния пациента. Процедура проводится в удобной обстановке, и мы обеспечиваем полное наблюдение врача на протяжении всего процесса лечения.
Узнать больше – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-5.ru/]капельница от похмелья в екатеринбурге[/url]
References:
Betsson casino
References:
https://euroclean-pro.fr/2024/05/27/salle-de-bains-sans-microbes/
References:
How do you play jacks
References:
https://www.tuttogossipnews.it/2023/02/14/piske-incontro-fan-instagram/
Процесс лечения начинается с консультации врача, который оценивает состояние пациента, его анамнез и определяет, какие процедуры и препараты нужно использовать. В большинстве случаев капельница включает в себя регидратацию, витамины группы B, антиеметики, препараты для улучшения работы печени и почек. Важно, что капельница не только помогает организму вывести токсины, но и восстанавливает нормальную работу всех систем организма, обеспечивая быстрое улучшение самочувствия.
Получить больше информации – https://kapelnicza-ot-pokhmelya-samara.ru/
Срочный домашний выезд особенно важен для семей, которые уже сталкивались с тяжёлыми последствиями алкоголизма и понимают, что обычные попытки «отпаивания» не решают проблему. Врач оценивает не только факт употребления, но и длительность запоя, возраст, наличие хронических болезней, уже принятые медикаменты, риск абстинентного синдрома, состояние сердца и общую нагрузку на организм. Такой формат позволяет анонимно вызвать специалиста, быстро провести необходимые вмешательства и определить, нужен ли только домашний вывод из острого состояния или дальше потребуется кодирование, повторная консультация, реабилитация либо более широкий маршрут помощи при наркомании.
Получить дополнительную информацию – [url=https://narkolog-na-dom-voronezh-3.ru/]нарколог на дом в воронеже[/url]
Когда человек сталкивается с симптомами похмелья, такие как головная боль, тошнота, слабость, головокружение, важно быстро принять меры, чтобы предотвратить развитие более серьёзных проблем. Капельница от похмелья помогает в этом, выводя токсины из организма, восстанавливая нормальное функционирование внутренних органов и возвращая пациента к нормальной жизни. Важно, что мы обеспечиваем полную анонимность на всех этапах лечения, что особенно важно для тех, кто не хочет, чтобы его зависимость стала известна.
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-6.ru/]капельница от похмелья на дому екатеринбург[/url]
Ключевым преимуществом вызова нарколога на дом является то, что лечение начинается в тот момент, когда оно особенно необходимо. Близкие пациента не должны волноваться о поиске клиники или медицинских центров в экстренной ситуации — помощь будет оказана немедленно, с минимальными затратами времени и без стресса для пациента.
Получить больше информации – [url=https://narkolog-na-dom-samara-1.ru/]narkolog-na-dom-samara-1.ru/[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, нестабильностью давления и изменениями в работе нервной системы. При длительном течении состояние может ухудшаться, и самостоятельный выход становится затруднённым. В таких случаях стационар рассматривается как пространство, где можно безопасно стабилизировать показатели и обеспечить постепенное восстановление.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-1.ru/]вывод из запоя на дому цена в нижнем новгороде[/url]
Комфортное окружение имеет огромное значение в процессе реабилитации. Спокойная атмосфера, приятные интерьеры, возможность заниматься хобби и спортивными упражнениями помогают снизить уровень стресса и тревоги, которые могут возникать у пациентов в период нахождения в стационаре. Это особенно важно, поскольку психологический комфорт является неотъемлемой частью эффективной реабилитации и предотвращения рецидивов. В некоторых случаях может быть предложена консультация и регулярный прием специалистов на протяжении года, чтобы обеспечить долгосрочный успех в восстановлении.
Изучить вопрос глубже – [url=https://narkologicheskij-staczionar-sankt-peterburg-4.ru/]частный наркологический стационар[/url]
Выезд нарколога на дом — это медицинская услуга, которая подразумевает не только экстренную помощь, но и полноценное обследование пациента в комфортных для него условиях. В наркологической клинике «Частный медик 24» мы обеспечиваем профессиональное лечение на дому, которое включает в себя несколько важных этапов, чтобы стабилизировать состояние пациента, улучшить его самочувствие и снизить риски дальнейших осложнений.
Получить дополнительные сведения – [url=https://narkolog-na-dom-samara-2.ru/]нарколог на дом вывод самара[/url]
Запрос на выезд врача связан не только с классическим запоем. На практике домашняя помощь нужна в разных ситуациях, когда организму уже трудно компенсировать последствия употребления, а откладывание визита увеличивает риск осложнений.
Подробнее – [url=https://narkolog-na-dom-voronezh-2.ru/]врач нарколог на дом в воронеже[/url]
References:
Leelanau sands casino
References:
https://vidmero.com/@corazonholcomb?page=about
Детоксикация на дому начинается с осмотра пациента. Доктора оценивают витальные показатели, уровень сознания и выраженность симптомов, анализируя текущие данные. После этого формируется план лечения, который реализуется сразу. Такой подход позволяет сократить время до начала терапии и повысить её эффективность.
Подробнее тут – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-10.ru/]анонимный вывод из запоя на дому санкт-петербург[/url]
Такие состояния требуют не только лечения, но и наблюдения, поскольку динамика может меняться в течение короткого времени. Стационар позволяет минимизировать риски и обеспечить безопасность пациента. При этом услуга может предоставляться анонимно, а цена лечения зависит от состояния пациента.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя на дому цена нижний новгород[/url]
Перед началом терапии врач проводит осмотр пациента. Измеряются основные показатели, включая давление и пульс, оценивается выраженность симптомов. На основании этих данных формируется состав капельницы и определяется тактика лечения, что позволяет эффективно провести вывод из запоя.
Исследовать вопрос подробнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-8.ru/]kapelnicza-ot-pokhmelya-voronezh-8.ru/[/url]
Процесс лечения капельницей помогает улучшить состояние пациента уже через короткий период. Важно, что процедура не только снимает симптомы похмелья, но и восстанавливает нормальную работу печени, почек и других органов, пострадавших от токсического воздействия алкоголя. Это помогает предотвратить долгосрочные последствия интоксикации, такие как хроническая усталость, проблемы с органами и психоэмоциональные расстройства.
Изучить вопрос глубже – https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/
Такие симптомы требуют медицинского вмешательства, поскольку могут усиливаться и приводить к ухудшению состояния. Капельница помогает стабилизировать самочувствие и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при необходимости пациент направляется на лечение в стационаре.
Получить дополнительную информацию – [url=https://kapelnicza-ot-pokhmelya-voronezh-6.ru/]капельница от похмелья цена в воронеже[/url]
Специалисты рекомендуют не откладывать вызов врача, если симптомы похмелья сильно нарушают обычный режим жизни. Чем раньше начнется лечение, тем быстрее произойдет стабилизация состояния. Наркологи также подчеркивают, что капельница от похмелья не является решением проблемы алкоголизма, но она помогает избавиться от острого дискомфорта и подготовить организм к более длительному восстановлению.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-nizhnij-novgorod-2.ru/]kapelnicza-ot-pokhmelya-nizhnij-novgorod-2.ru/[/url]
Работа с пациентами в наркологическом стационаре начинается с диагностики, которая помогает определить степень зависимости и сопутствующие заболевания. На основе этих данных разрабатывается индивидуальный план лечения. Врачи, наркологи и психотерапевты работают в тесном контакте с пациентом, что позволяет достичь наилучших результатов в процессе восстановления. Важно также убедиться, что клиника имеет необходимую лицензию, а для эффективного лечения могут быть предложены такие процедуры, как прием психотерапевта и кодирование от зависимости.
Ознакомиться с деталями – [url=https://narkologicheskij-staczionar-sankt-peterburg-3.ru/]наркологический стационар в санкт-петербурге[/url]
Капельница от запоя — это эффективное медицинское вмешательство, направленное на быстрое восстановление организма после длительного злоупотребления алкоголем. Процесс лечения с использованием капельницы способствует быстрому выводу токсинов, восстановлению водно-электролитного баланса и нормализации общего состояния пациента. Капельница оказывает комплексное воздействие на организм, улучшая его самочувствие уже в течение первых часов после процедуры.
Получить дополнительные сведения – [url=https://kapelnica-ot-zapoya-nizhnij-novgorod-5.ru/]капельницы от запоя вызов город[/url]
В Нижнем Новгороде стационарное лечение используется при выраженных симптомах или наличии факторов риска, особенно при тяжелом состоянии больного на фоне алкоголизма или длительного употребления алкоголя. Это позволяет исключить внешние нагрузки, обеспечить непрерывный мониторинг и при необходимости быстро скорректировать терапию. Решение о госпитализации принимается на основе осмотра, консультации специалиста и оценки текущего состояния человека, с учётом клинических данных.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod.ru/]вывод из запоя дешево в нижнем новгороде[/url]
Капельница от похмелья в Самаре: быстрое снятие симптомов, детоксикация и восстановление организма под контролем специалистов в наркологической клинике «Детокс»
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-samara-12.ru/]капельница от похмелья цена[/url]
Вывод из запоя на дому в Санкт-Петербурге с анонимным выездом врача, снятием интоксикации и поддержкой в наркологической клинике «Частный медик 24»
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому анонимно санкт-петербург[/url]
Наркологический стационар в Санкт-Петербурге: круглосуточное лечение, детоксикация и наблюдение специалистов в комфортных условиях в наркологической клинике «Похмельная служба»
Ознакомиться с деталями – [url=https://narkologicheskij-staczionar-sankt-peterburg.ru/]лечение в наркологическом стационаре санкт-петербург[/url]
Первичный осмотр включает оценку витальных показателей, уровня сознания, выраженности симптомов и факторов риска. После этого врач определяет объём вмешательства и приступает к терапии. В большинстве случаев применяется инфузионное лечение, направленное на восстановление водного баланса и выведение токсинов.
Детальнее – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]клиника наркологической помощи[/url]
Капельница от похмелья — это медицинская процедура, направленная на быстрое восстановление организма после алкогольной интоксикации. Она помогает устранить обезвоживание, нормализовать обменные процессы и снизить токсическую нагрузку на внутренние органы. В отличие от домашних методов, инфузионная терапия действует напрямую через кровоток, обеспечивая более быстрый и выраженный эффект.
Углубиться в тему – [url=https://kapelnicza-ot-pokhmelya-samara-8.ru/]капельница от похмелья цена самара[/url]
Такие состояния требуют медицинского вмешательства, поскольку могут ухудшаться без лечения. Капельница позволяет стабилизировать состояние и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при тяжёлых случаях рассматривается лечение в стационаре.
Узнать больше – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья на дому в воронеже[/url]
В Воронеже круглосуточная помощь при похмелье востребована в ситуациях, когда симптомы появляются внезапно или усиливаются в ночное время, особенно в запое или после запоя. Врач проводит консультацию, оценивает состояние пациента и принимает решение о проведении инфузионной терапии. Такой подход позволяет своевременно устранить симптомы и предотвратить их дальнейшее развитие. При необходимости можно оставить заявку, уточнить цены или получить помощь бесплатно на первичном этапе.
Ознакомиться с деталями – [url=https://kapelnicza-ot-pokhmelya-voronezh-7.ru/]kapelnicza-ot-pokhmelya-voronezh-7.ru/[/url]
Обращение в наркологический стационар в Санкт-Петербурге может стать важным шагом для людей, страдающих от алкогольной или наркотической зависимости. Стационарное лечение предоставляет пациентам не только медицинскую помощь, но и психологическую поддержку, необходимую для успешной реабилитации. Это подход, ориентированный на комплексное восстановление здоровья, физическое и психоэмоциональное состояние пациента.
Подробнее – [url=https://narkologicheskij-staczionar-sankt-peterburg-2.ru/]наркологическая помощь стационар санкт-петербург[/url]
Как отмечает врач-нарколог Сергей Иванов: “Самое главное преимущество капельницы с медицинским контролем — это точная диагностика состояния пациента перед началом процедуры и возможность корректировать лечение в процессе, что делает её гораздо более безопасной и эффективной по сравнению с самостоятельными методами.”
Получить дополнительные сведения – [url=https://kapelnicza-ot-pokhmelya-nizhnij-novgorod-1.ru/]капельница от похмелья вызов на дом нижний новгород[/url]
Для семьи это тоже имеет большое значение. Пока врач в пути, родственники часто совершают одни и те же ошибки: пытаются «отпаивать» человека через силу, смешивают несовместимые медикаменты, дают советы, которые только повышают тревогу, спорят или требуют немедленно взять себя в руки. Профессиональный выезд снимает эту хаотичность. После осмотра врач объясняет, какие симптомы связаны с алкогольной интоксикацией, какие могут указывать на осложнения, что допустимо дома, а что требует перевода в стационар. В этом и состоит ценность выезда: он возвращает контроль над ситуацией и позволяет начать лечение без лишних задержек.
Ознакомиться с деталями – [url=https://narkolog-na-dom-voronezh-1.ru/]нарколог на дом[/url]
Капельница от похмелья — это один из наиболее эффективных методов экстренной медицинской помощи, который позволяет быстро снять симптомы алкогольной интоксикации и восстановить организм после злоупотребления алкоголем. В наркологической клинике «Частный медик 24» в Самаре мы предоставляем услугу выезда нарколога на дом и капельной терапии для пациентов, испытывающих тяжёлые симптомы похмелья. Это удобный способ получить необходимую помощь без лишнего стресса, сохраняя анонимность и комфорт пациента.
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-samara-1.ru/]капельница от похмелья на дому самара[/url]
Для жителей Екатеринбурга наркологическая клиника «Частный медик 24» предлагает платную услугу выезда врача на дом для проведения капельницы от похмелья. Когда человек переживает сильные симптомы похмелья, такие как головная боль, тошнота, слабость, важно не тянуть с лечением и начать восстановление как можно скорее. Капельница от похмелья помогает хорошо облегчить самочувствие пациента, снять головную боль и улучшить общее состояние, восстановив водно-электролитный баланс в организме.
Получить дополнительные сведения – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-4.ru/]капельница от похмелья цена екатеринбург[/url]
Когда такие симптомы становятся ярко выраженными, важно не затягивать с лечением и вызвать нарколога на дом. Это позволит своевременно устранить токсические вещества из организма и предотвратить серьёзные проблемы с органами. Важно, чтобы лечение началось как можно быстрее, что возможно только через экстренный выезд специалиста на дом.
Детальнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-6.ru/]капельница от похмелья на дом в екатеринбурге[/url]
Для Воронежа выездной формат особенно востребован вечером, ночью и ранним утром, когда у больного резко усиливаются симптомы и поездка в медицинское учреждение становится тяжёлой или просто нереальной. Если человек несколько дней употреблял алкоголь, почти не спал, плохо переносит воду, жалуется на сердцебиение и слабость, то откладывать осмотр не стоит. Срочная наркологическая помощь нужна именно тогда, когда ситуация развивается быстро, а семья уже видит, что своими силами справиться не удаётся. Врач приезжает, проводит осмотр, определяет, нет ли признаков осложнений, и уже на месте решает, какие меры допустимы дома, а какие требуют другого формата оказания помощи.
Получить больше информации – [url=https://narkolog-na-dom-voronezh-3.ru/]запой нарколог на дом в воронеже[/url]
Нарколог на дом может помочь в следующих ситуациях:
Получить дополнительные сведения – [url=https://narkolog-na-dom-samara-1.ru/]нарколог на дом анонимно[/url]
Лечение в стационаре начинается с первичной оценки состояния пациента. Врач фиксирует витальные показатели, проводит клиническое интервью и определяет объём вмешательства. После этого формируется план лечения с чёткими целями и временными интервалами для оценки результата. При необходимости пациент или его близкие могут заранее заказать лечение или получить консультацию.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-1.ru/]нарколог на дом вывод из запоя[/url]
Выезд нарколога на дом — это медицинская услуга, которая подразумевает не только экстренную помощь, но и полноценное обследование пациента в комфортных для него условиях. В наркологической клинике «Частный медик 24» мы обеспечиваем профессиональное лечение на дому, которое включает в себя несколько важных этапов, чтобы стабилизировать состояние пациента, улучшить его самочувствие и снизить риски дальнейших осложнений.
Детальнее – [url=https://narkolog-na-dom-samara-2.ru/]нарколог на дом анонимно[/url]
Выбор наркологического стационара с комфортными условиями требует внимательного подхода, чтобы убедиться, что все аспекты лечения и реабилитации будут выполнены на высоком уровне. Важно учитывать не только медицинскую составляющую, но и то, как созданы условия для пациентов, их психологический комфорт и безопасность на всех этапах лечения. Также стоит учитывать цену за стационарное лечение с круглосуточным наблюдением, чтобы выбрать оптимальный вариант, соответствующий потребностям пациента и его бюджету.
Детальнее – [url=https://narkologicheskij-staczionar-sankt-peterburg-4.ru/]наркологическая клиника стационар[/url]
Первый этап — это стабилизация состояния. Он начинается с детальной оценки: измеряются витальные показатели, проводится клиническое интервью, уточняется длительность алкогольной интоксикации и сопутствующие факторы. После этого формируется план лечения с чёткими целями и временными интервалами оценки.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod.ru/]вывод из запоя на дому круглосуточно нижний новгород[/url]
Домашний формат ценят не только за удобство. Он помогает начать лечение анонимно, без дороги, без ожидания и без лишнего стресса для пациента. Для многих семей именно выездной наркологическая маршрут становится первой точкой, с которой начинается более серьёзное восстановление: обсуждаются не только снятие острых симптомов, но и кодирование, реабилитация, повторная консультация, а при необходимости — и маршруты помощи при наркомании. Особенно это актуально, если человек употребляет давно, уже несколько лет сталкивается со срывами и сам замечает, что проблема перестала ограничиваться только плохим самочувствием после алкоголя.
Получить дополнительную информацию – [url=https://narkolog-na-dom-voronezh-2.ru/]вызвать нарколога на дом в воронеже[/url]
Капельница от похмелья — это не просто средство для снятия симптомов, но и эффективный способ быстрого восстановления организма после алкогольной интоксикации. В наркологической клинике «Частный медик 24» в Екатеринбурге мы предоставляем услугу выезда нарколога на дом, что позволяет пациентам получить необходимую медицинскую помощь, не покидая комфорт своей обстановки. Это особенно важно в случае, если состояние пациента серьёзно ухудшилось, и он не может поехать в клинику самостоятельно.
Исследовать вопрос подробнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-7.ru/]капельница от похмелья на дом екатеринбург[/url]
В Санкт-Петербурге услуга срочного вывода из запоя на дому востребована в ситуациях, когда состояние пациента ухудшается и требуется немедленная помощь. Врач проводит консультацию, оценивает общее состояние, длительность запоя и выраженность симптомов, после чего определяет тактику лечения при алкоголизме. При необходимости помощь оказывается в кратчайшие сроки, без ожидания госпитализации в стационаре. Услугу можно заказать заранее или срочно через сайт клиники.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-10.ru/]вывод из запоя на дому анонимно санкт-петербург[/url]
Нарколог на дом в Самаре — помощь при запое и интоксикации в наркологической клинике «Частный медик 24»
Исследовать вопрос подробнее – https://narkolog-na-dom-samara-2.ru
В Нижнем Новгороде стационарный формат лечения применяется при наличии факторов, повышающих риск осложнений или снижающих эффективность домашней терапии. Врач принимает решение на основании осмотра, консультации и анализа данных, оценивая текущее состояние пациента и его реакцию на предыдущие попытки лечения. При необходимости можно заранее обратиться в центр лечения алкоголизма и наркомании или заказать услугу по телефону.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя с выездом в нижнем новгороде[/url]
Процесс лечения капельницей помогает улучшить состояние пациента уже через короткий период. Важно, что процедура не только снимает симптомы похмелья, но и восстанавливает нормальную работу печени, почек и других органов, пострадавших от токсического воздействия алкоголя. Это помогает предотвратить долгосрочные последствия интоксикации, такие как хроническая усталость, проблемы с органами и психоэмоциональные расстройства.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья цена в екатеринбурге[/url]
Перед началом терапии врач проводит осмотр пациента. Измеряются основные показатели, включая давление и пульс, оценивается выраженность симптомов. На основании этих данных формируется состав капельницы и определяется тактика лечения, что позволяет эффективно провести вывод из запоя.
Подробнее тут – [url=https://kapelnicza-ot-pokhmelya-voronezh-8.ru/]капельница от похмелья вызов на дом[/url]
Нарколог на дом — это формат помощи, при котором врач приезжает к пациенту в момент, когда состояние уже не позволяет спокойно ждать или самостоятельно ехать в клинику. При запое и выраженной интоксикации такой выезд особенно важен: человек может испытывать слабость, тошноту, тремор, сухость во рту, сердцебиение, скачки давления, тревогу и бессонницу. В наркологической клинике «Частный медик 24» домашний вызов строится не вокруг одной капельницы, а вокруг полноценного врачебного решения. Сначала проводится консультация, затем оцениваются симптомы, сопутствующие болезни, уже принятые медикаменты, риски для сердца, сосудов и нервной системы, и только после этого врач подбирает подходящую схему помощи. Такой подход особенно важен при алкоголизма, когда ошибка в самостоятельном лечении может быстро усилить нагрузку на организм.
Детальнее – [url=https://narkolog-na-dom-voronezh-2.ru/]врач нарколог на дом[/url]
Перед началом процедуры врач проводит осмотр пациента. Оцениваются основные показатели, включая давление и пульс, а также выраженность симптомов. На основании полученных данных формируется состав капельницы и определяется тактика лечения, что позволяет эффективно провести вывод из запоя.
Подробнее можно узнать тут – http://kapelnicza-ot-pokhmelya-voronezh-6.ru
Процесс восстановления с помощью капельницы с мягким восстановлением происходит в несколько этапов. Вначале происходит нормализация водно-солевого баланса, что помогает предотвратить обезвоживание и улучшить состояние кожи. Затем происходит восстановление энергетических запасов организма, что помогает уменьшить усталость и слабость, что также важно при лечении наркомании. Витамины и антиоксиданты восстанавливают функции клеток и органов, что способствует более быстрому очищению организма от продуктов распада алкоголя, при этом пациентам может быть доступна анонимное консультация и дальнейшая реабилитация.
Углубиться в тему – [url=https://kapelnicza-ot-pokhmelya-samara-12.ru/]капельница от похмелья вызов на дом в самаре[/url]
Такие состояния требуют не только лечения, но и наблюдения, поскольку динамика может меняться в течение короткого времени. Стационар позволяет минимизировать риски и обеспечить безопасность пациента. При этом услуга может предоставляться анонимно, а цена лечения зависит от состояния пациента.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя в нижнем новгороде[/url]
Вывод из запоя на дому — это медицинская помощь, направленная на стабилизацию состояния пациента без госпитализации. Такой формат позволяет начать лечение сразу после обращения и снизить нагрузку на организм, связанную с транспортировкой. В наркологической клинике «Частный медик 24» помощь оказывается с выездом врача, который проводит диагностику и подбирает терапию в зависимости от текущего состояния.
Получить больше информации – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому санкт-петербург[/url]
Нарколог на дом — это срочная врачебная помощь, которая нужна в тот момент, когда больного уже сложно везти в клинику, а ждать улучшения без осмотра опасно. Домашний формат особенно актуален при запое, выраженной интоксикации, повторной рвоте, скачках давления, сильном треморе, бессоннице и тревоге. В такой ситуации важно не просто заказать выезд и получить капельницу, а сразу запустить понятный медицинский маршрут: осмотр, консультация, оценка рисков, подбор терапии и решение, можно ли безопасно оставаться дома. Именно поэтому услуга «нарколог на дом» воспринимается не как разовая процедура, а как полноценная наркологическая помощь, где каждое действие связано с текущим состоянием пациента и его безопасностью.
Получить дополнительную информацию – [url=https://narkolog-na-dom-voronezh-3.ru/]нарколог на дом[/url]
Запой, длительное употребление алкоголя или случайное злоупотребление могут привести к неприятным симптомам похмелья, таким как головная боль, слабость, тошнота, головокружение и усталость. Эти симптомы обусловлены тем, что в организме остаются продукты распада алкоголя, которые токсически воздействуют на все органы. Капельница от похмелья на дому — это отличная возможность быстро снять острые симптомы и восстановить нормальное состояние организма, не выходя из привычной обстановки.
Исследовать вопрос подробнее – http://kapelnicza-ot-pokhmelya-samara-2.ru
В Нижнем Новгороде стационарное лечение используется при выраженных симптомах или наличии факторов риска, особенно при тяжелом состоянии больного на фоне алкоголизма или длительного употребления алкоголя. Это позволяет исключить внешние нагрузки, обеспечить непрерывный мониторинг и при необходимости быстро скорректировать терапию. Решение о госпитализации принимается на основе осмотра, консультации специалиста и оценки текущего состояния человека, с учётом клинических данных.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod.ru/]вывод из запоя капельница нижний новгород[/url]
Нарколог на дом может помочь в следующих ситуациях:
Подробнее можно узнать тут – [url=https://narkolog-na-dom-samara-1.ru/]врач нарколог на дом[/url]
Алкогольная интоксикация оказывает серьёзное влияние на организм, вызывая головную боль, тошноту, слабость и головокружение. Капельница помогает организму быстро избавиться от продуктов распада алкоголя, восстановить нормальное функционирование органов и минимизировать последствия для здоровья. Важно, что мы обеспечиваем полное наблюдение врача на протяжении всей процедуры, что помогает гарантировать безопасность пациента и максимальную эффективность лечения.
Получить больше информации – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья анонимно[/url]
Суть капельницы заключается в том, чтобы быстро ввести в организм необходимые растворы, которые помогают восстановить водно-солевой баланс, очищают организм от токсинов, ускоряют обмен веществ и снижают нагрузку на внутренние органы. Врачи-наркологи используют специальные составы, которые включают в себя жидкости, электролиты, витамины и лекарственные средства для снятия симптомов похмелья.
Получить дополнительные сведения – https://kapelnicza-ot-pokhmelya-nizhnij-novgorod-2.ru/
Капельница от запоя — это эффективное медицинское вмешательство, направленное на быстрое восстановление организма после длительного злоупотребления алкоголем. Процесс лечения с использованием капельницы способствует быстрому выводу токсинов, восстановлению водно-электролитного баланса и нормализации общего состояния пациента. Капельница оказывает комплексное воздействие на организм, улучшая его самочувствие уже в течение первых часов после процедуры.
Подробнее – [url=https://kapelnica-ot-zapoya-nizhnij-novgorod-5.ru/]капельницы от запоя вызов город[/url]
Работа с пациентами в наркологическом стационаре начинается с диагностики, которая помогает определить степень зависимости и сопутствующие заболевания. На основе этих данных разрабатывается индивидуальный план лечения. Врачи, наркологи и психотерапевты работают в тесном контакте с пациентом, что позволяет достичь наилучших результатов в процессе восстановления. Важно также убедиться, что клиника имеет необходимую лицензию, а для эффективного лечения могут быть предложены такие процедуры, как прием психотерапевта и кодирование от зависимости.
Выяснить больше – [url=https://narkologicheskij-staczionar-sankt-peterburg-3.ru/]наркологическая клиника стационар санкт-петербург[/url]
Капельница от похмелья — это эффективный способ снятия симптомов алкогольной интоксикации, который позволяет быстро восстановить организм после длительного употребления алкоголя. В наркологической клинике «Частный медик 24» в Екатеринбурге мы предлагаем капельную терапию, которая включает в себя комплекс препаратов для восстановления водно-электролитного баланса, выведения токсинов и нормализации состояния пациента. Процедура проводится в удобной обстановке, и мы обеспечиваем полное наблюдение врача на протяжении всего процесса лечения.
Подробнее тут – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-5.ru/]капельница от похмелья[/url]
Нарколог на дом в Самаре с выездом специалиста, детоксикацией и анонимной медицинской помощью в наркологической клинике «Частный медик 24»
Подробнее можно узнать тут – [url=https://narkolog-na-dom-samara-1.ru/]www.domen.ru[/url]
“Капельница с мягким восстановлением идеально подходит тем, кто ищет постепенный и безопасный способ вернуть себе нормальное состояние после пьянки. Такой подход не перегружает организм и помогает избежать нежелательных эффектов от слишком резкого восстановления.” — Алексей Смирнов, нарколог, клиника восстановления.
Узнать больше – [url=https://kapelnicza-ot-pokhmelya-samara-12.ru/]капельница от похмелья анонимно в самаре[/url]
Для семьи это тоже имеет большое значение. Пока врач в пути, родственники часто совершают одни и те же ошибки: пытаются «отпаивать» человека через силу, смешивают несовместимые медикаменты, дают советы, которые только повышают тревогу, спорят или требуют немедленно взять себя в руки. Профессиональный выезд снимает эту хаотичность. После осмотра врач объясняет, какие симптомы связаны с алкогольной интоксикацией, какие могут указывать на осложнения, что допустимо дома, а что требует перевода в стационар. В этом и состоит ценность выезда: он возвращает контроль над ситуацией и позволяет начать лечение без лишних задержек.
Выяснить больше – [url=https://narkolog-na-dom-voronezh-1.ru/]нарколог на дом анонимно воронеж[/url]
После оформления вызова нарколог приезжает к пациенту и проводит комплексную оценку состояния. Врач измеряет давление, частоту пульса, оценивает уровень сознания и выраженность симптомов. На основании полученных данных формируется план лечения, который реализуется сразу на месте.
Подробнее – [url=https://narkolog-na-dom-nizhnij-novgorod.ru/]запой нарколог на дом в нижнем новгороде[/url]
Первичный осмотр включает оценку витальных показателей, уровня сознания, выраженности симптомов и факторов риска. После этого врач определяет объём вмешательства и приступает к терапии. В большинстве случаев применяется инфузионное лечение, направленное на восстановление водного баланса и выведение токсинов.
Подробнее – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]наркологическая помощь[/url]
References:
Chicago casino
References:
https://graph.org/Ripper-Casino-Review-Bonuses–Games-04-20
Алкогольная зависимость — хроническое заболевание, требующее комплексного подхода. В клинике «КубаньМед» в Краснодаре разработаны авторские методики, направленные на полное преодоление зависимости и возвращение пациента к полноценной жизни. Мы предлагаем индивидуальные программы лечения, сочетающие медикаментозную детоксикацию, специализированные реабилитационные процедуры и профессиональные психологические консультации. Всё это в условиях полного комфорта и абсолютной конфиденциальности.
Исследовать вопрос подробнее – [url=https://lechenie-alkogolizma-krasnodar0.ru/]лечение алкоголизма краснодарский край[/url]
Процесс вывода из запоя на дому в Ярославле строится по четко отлаженной схеме, включающей несколько последовательных этапов, направленных на максимально быстрое и безопасное восстановление здоровья пациента.
Углубиться в тему – https://vyvod-iz-zapoya-yaroslavl00.ru/vyvod-iz-zapoya-na-domu-yaroslavl
Наркологическая клиника в Краснодаре играет важную роль в оказании медицинской помощи людям с различными формами зависимости. Современные методы диагностики и лечения позволяют эффективно справляться с проблемами, связанными с алкоголизмом, наркотической зависимостью и другими психоактивными веществами. Клиническая помощь организована с учетом индивидуальных особенностей пациентов и направлена на достижение стойкой ремиссии.
Выяснить больше – https://narkologicheskaya-klinika-krasnodar0.ru/platnaya-narkologicheskaya-klinika-krasnodar/
Особое внимание мы уделяем психологической составляющей. Нарколог на дом в Екатеринбурге в «НЕО+» — это не только физическое очищение, но и работа с мотивацией, разрушение психологических триггеров зависимости. Зависимость разрушает жизнь, поэтому мы предлагаем психотерапевтическое сопровождение. Родственники получают отдельную поддержку: консультации психолога помогают правильно выстроить общение с зависимым человеком и мотивировать его на дальнейшее лечение. Реабилитация может проходить амбулаторно или в стационаре партнёрских центров с комфортабельными условиями, где пациенты находятся под круглосуточным наблюдением.
Подробнее – [url=https://narkolog-na-dom-ekaterinburg-1.ru/]нарколог на дом анонимно екатеринбург[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. В сложные ситуации, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови, УЗИ внутренних органов и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-18.ru/]вывод из запоя в стационаре клиника[/url]
Вывод из запоя на дому в Екатеринбурге: срочное восстановление, детоксикация и медицинская помощь в наркологической клинике «Детокс»
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-20.ru/]анонимный вывод из запоя на дому[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. При отравление продуктами распада этанола, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Разобраться лучше – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]наркология вывод из запоя в стационаре[/url]
Непрерывный мониторинг витальных показателей позволяет фиксировать малейшие изменения в состоянии пациента и своевременно вносить коррективы в терапевтический план. В палатах клиники «Элегия Мед» установлены системы отслеживания частоты пульса, сатурации, температуры и артериального давления, данные с которых автоматически передаются в медицинскую карту. Медсестры и дежурные врачи проверяют состояние пациента по графику, проводят симптоматическую терапию, контролируют прием препаратов и обеспечивают комфортные условия для восстановления. Такая организация процесса исключает хаотичное назначение средств, предотвращает полипрагмазию и гарантирует, что каждый этап детоксикации проходит под строгим клиническим контролем. При необходимости применяются дополнительные методы очищения крови, включая плазмаферез, который эффективно помогает вывести стойкие токсины и метаболиты, не удаляемые стандартной инфузионной терапией.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-16.ru/]быстрый вывод из запоя в стационаре санкт-петербург[/url]
Принятие решения о госпитализации часто сопровождается внутренними сомнениями и попытками найти альтернативные пути решения проблемы. Однако современные клинические протоколы четко определяют ситуации, когда амбулаторный формат не способен обеспечить должный уровень безопасности и эффективности. Стационарное лечение назначается тогда, когда интоксикация затрагивает несколько систем организма одновременно, а риск развития соматических или психиатрических осложнений превышает допустимые пределы. В условиях медицинского учреждения исключается доступ к психоактивным веществам, обеспечивается изоляция от бытовых триггеров и создается контролируемая среда, способствующая физиологической стабилизации. Такой подход особенно важен для пациентов с длительным стажем употребления, когда самостоятельные попытки прекращения приводят к тяжелым абстинентным состояниям, требующим инфузионной поддержки и постоянного врачебного контроля.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-7.ru/]вывод из запоя в стационаре анонимно[/url]
К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. В тяжелых случаях резкое прекращение употребления без медицинской поддержки может спровоцировать отек головного мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При серьезных метаболических нарушениях интоксикация затрагивает центральную и периферическую нервной систему, что требует немедленного вмешательства. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения. В случаях сочетанной зависимости, когда в анамнезе присутствует наркотическая аддикция, протоколы детоксикации адаптируются под специфику веществ и включают усиленный кардиологический и нейрологический контроль.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-9.ru/]быстрый вывод из запоя в стационаре в нижнем новгороде[/url]
Вывод из запоя на дому в Екатеринбурге – это услуга, которая становится необходимой, когда состояние пациента ухудшается после длительного употребления алкоголя, и медицинская помощь требуется немедленно. На дому пациенту предоставляется квалифицированная помощь, направленная на быстрое снятие интоксикации, восстановление водно-солевого баланса и стабилизацию общего состояния.
Узнать больше – http://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru
Терапевтический процесс в стационаре строится по принципу последовательного выполнения клинических задач: диагностика, стабилизация, медикаментозная поддержка и подготовка к амбулаторному этапу. При поступлении врач проводит детальный осмотр, собирает анамнез, оценивает неврологический статус и при необходимости назначает лабораторные исследования. На основе полученных данных формируется индивидуальный протокол, учитывающий возраст, длительность интоксикации, наличие сопутствующих патологий и переносимость лекарственных компонентов. Мы применяем только сертифицированные препараты, зарегистрированные в РФ, и строго соблюдаем клинические рекомендации Минздрава, исключая псевдонаучные методики. Стандарты оказания медицинской помощи фиксируются во внутренних регламентах и регулярно проверяются независимыми аудиторами.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-17.ru/]нарколог вывод из запоя в стационаре санкт-петербург[/url]
References:
Fair go https://graph.org/Lucky-Green-Casino-Spin-to-Win-04-20 bitcoin deposit
Затяжной запой перестает быть бытовой проблемой в тот момент, когда организм теряет способность самостоятельно восстанавливаться после интоксикации. Накопление ацетальдегида, нарушение водно-электролитного баланса, истощение запасов витаминов и перегрузка сердечно-сосудистой системы создают состояние, при котором домашние методы перестают быть безопасными. Срочно стабилизировать самочувствие и быстро купировать абстинентный синдром позволяет только контролируемая медицинская среда. Вывод из запоя в стационаре в Нижнем Новгороде становится клинически обоснованным решением, когда требуется не просто снятие симптомов, а комплексная детоксикация под круглосуточным наблюдением врачей. Наркологическая клиника «Стармед» организует процесс лечения в соответствии с актуальными стандартами доказательной медицины, обеспечивая безопасность пациента, прозрачность процедур и плавный переход к противорецидивной терапии. Мы понимаем, что решение о госпитализации часто принимается в состоянии стресса, поэтому наша работа начинается с четкой диагностики, честного объяснения плана лечения и соблюдения строгих протоколов конфиденциальности. Опытные специалисты клиники помогут вызвать доверие к процессу восстановления уже на этапе первого контакта.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/]нарколог вывод из запоя в стационаре[/url]
Вывод из запоя на дому в Екатеринбурге: срочная помощь, детоксикация и восстановление под контролем специалистов в наркологической клинике «Детокс»
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-16.ru/]вывод из запоя на дому екатеринбург[/url]
Нарколог на дом в Екатеринбурге востребован в ситуациях, когда человеку нужна врачебная помощь после употребления алкоголя, при запое, выраженном похмельном синдроме, нарушении сна, тревоге, скачках давления, слабости и других признаках ухудшения самочувствия. Такой формат обращения часто выбирают семьи, которые хотят вызвать врача без поездки в клинику и быстро получить консультацию по состоянию больного. Домашний выезд особенно важен тогда, когда требуется детоксикация, наблюдение после нескольких дней употребления спиртного и оценка рисков, связанных с последствиями алкоголизма.
Выяснить больше – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]нарколог на дом вывод[/url]
При выводе из запоя на дому с быстрым облегчением используются различные медикаменты, направленные на быстрое восстановление водно-солевого баланса, улучшение функции печени и почек, а также снижение симптомов алкогольного абстинентного синдрома. Важно, что состав препаратов подбирается в зависимости от состояния пациента, и все препараты вводятся под контролем квалифицированного медицинского специалиста.
Детальнее – https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru
Выезд нарколога на дом в Самаре организован так, чтобы пациент получил помощь без ожидания и без лишней нагрузки на организм. После обращения специалист приезжает по указанному адресу, проводит первичный осмотр, оценивает общее состояние, уровень интоксикации, показатели давления, пульса, дыхания и собирает краткий анамнез. На основании этой оценки врач определяет, можно ли безопасно оказывать помощь на дому, и подбирает подходящую схему лечения, включая возможное кодирование или вывод из алкоголизма. Такой формат позволяет начать медицинские мероприятия сразу после осмотра и быстро перейти к стабилизации состояния.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-samara-5.ru/]www.domen.ru[/url]
Наркологический стационар с круглосуточным наблюдением предлагает комплексное лечение и восстановление для людей, страдающих от алкогольной или наркотической зависимости. Пациенты получают помощь в условиях стационара, что позволяет устранить риск срыва и обеспечить безопасное и комфортное выздоровление. В таких клиниках работают квалифицированные наркологи, психологи и другие специалисты, которые контролируют процесс реабилитации на всех этапах. В некоторых случаях может потребоваться вывод из запоя с применением капельниц, а также лечение в специализированном центре для более комплексного восстановления.
Детальнее – [url=https://narkologicheskij-staczionar-sankt-peterburg.ru/]наркологическая клиника стационар санкт-петербург[/url]
Наркологический стационар с комфортными условиями сочетает в себе высококлассное медицинское обслуживание и удобства, которые способствуют более быстрому восстановлению пациента. В таких клиниках пациенты не только получают лечение от зависимости, но и имеют возможность восстановиться в комфортных условиях, что важно для психоэмоционального состояния. Комфортные условия способствуют улучшению настроения, уменьшению стресса и созданию более эффективной атмосферы для лечения. В случае запоя или алкоголизма врач может предоставить помощь на дому, чтобы стабилизировать состояние пациента до перевода в стационар.
Узнать больше – https://narkologicheskij-staczionar-sankt-peterburg-4.ru
Когда человек или его родственники понимают, что нужна наркологическая помощь в Воронеже, время становится решающим фактором. Запой, ломка, тяжёлая интоксикация — в таких ситуациях промедление может привести к необратимым последствиям для здоровья и жизни. Наша клиника создана именно для того, чтобы оказывать эффективную круглосуточную наркологическую помощь в Воронеже в самых сложных случаях. Мы не заставляем ждать в очередях государственных учреждений, не ставим на учёт и не разглашаем информацию. Всё происходит анонимно, на дому или в комфортных условиях нашей партнёрской клиники. Пациенты из Воронежа, Воронежской области, а также соседних регионов уже более 12 лет выбирают «Клиника Плюс» благодаря сочетанию скорости, профессионализма, полной анонимности и доказанной результативности.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-voronezh-2.ru/]скорая наркологическая помощь воронеж[/url]
Капельница действует быстро благодаря тому, что активные вещества вводятся непосредственно в кровь, минуя желудочно-кишечный тракт. Это позволяет быстро уменьшить симптомы, такие как головная боль, тошнота, слабость, а также нормализовать работу печени и почек, которые страдают от длительного употребления алкоголя. В некоторых случаях, если требуется длительное наблюдение, пациент может быть направлен в стационар, и лечение может продолжаться на летний период с более тщательным контролем состояния.
Разобраться лучше – https://kapelnica-ot-zapoya-nizhnij-novgorod-5.ru
Игнорирование выраженных симптомов может привести к развитию таких опасных состояний, как алкогольный делирий, острые психозы, инфаркт или инсульт. Вызов нарколога на дом круглосуточно позволяет оперативно стабилизировать состояние пациента в привычной для него обстановке, минимизируя стресс и риски, связанные с транспортировкой в стационар. Анонимный формат обращения обеспечивает конфиденциальность и делает помощь доступной даже для тех, кто опасается огласки.
Получить больше информации – [url=https://narkolog-na-dom-samara-6.ru/]www.domen.ru[/url]
Наркологическая помощь в Воронеже: профессиональное лечение зависимостей, выезд врача, анонимная помощь в наркологической клинике «Клиника Плюс».
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-voronezh.ru/]круглосуточная наркологическая помощь воронеж[/url]
Наркологический стационар — это специализированное медицинское учреждение, предназначенное для лечения и реабилитации пациентов с зависимостью от алкоголя, наркотиков и других психоактивных веществ. В Санкт-Петербурге существует множество таких учреждений, которые предоставляют комплексную помощь людям, страдающим от зависимости. Лечение в стационаре часто является первым шагом на пути к выздоровлению, особенно в случаях тяжелых зависимостей, когда амбулаторное лечение может не дать должного эффекта. В случае запоя или хронического алкоголизма стационарное лечение может стать необходимым, особенно если выезд на дом не позволяет должным образом контролировать процесс восстановления.
Подробнее можно узнать тут – [url=https://narkologicheskij-staczionar-sankt-peterburg-3.ru/]лечение в наркологическом стационаре в санкт-петербурге[/url]
Многие семьи откладывают визит к наркологу, надеясь, что организм восстановится самостоятельно после отдыха, а обещания «больше не повторится» окажутся надежным ориентиром. На практике при сформированной зависимости такие ожидания лишь отнимают критическое время. Если промежутки между эпизодами употребления сокращаются, похмелье переносится тяжелее, а контроль над дозой утрачивается, проблема переходит из бытовой плоскости в медицинскую. Откладывание помощи формирует ложное чувство контроля, истощает ресурсы организма и снижает готовность пациента к терапии в будущем. Решение обратиться к профессионалам часто принимается на пределе эмоциональных и физических сил, но именно своевременный шаг определяет прогноз восстановления.
Узнать больше – [url=https://narkologicheskaya-pomoshh-voronezh-3.ru/]клиника наркологической помощи[/url]
Наркологическая помощь в Воронеже: срочный выезд нарколога, капельницы и лечение зависимостей в наркологической клинике «Клиника Плюс».
Углубиться в тему – [url=https://narkologicheskaya-pomoshh-voronezh-1.ru/]клиника наркологической помощи в воронеже[/url]
Перед началом терапии врач проводит осмотр пациента. Измеряются основные показатели, включая давление и пульс, оценивается выраженность симптомов. На основании этих данных формируется состав капельницы и определяется тактика лечения, что позволяет эффективно провести вывод из запоя.
Детальнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-8.ru/]капельница от похмелья на дому[/url]
Комплексное лечение в наркологическом стационаре включает несколько последовательных этапов, каждый из которых направлен на решение конкретных задач. Начальный этап включает в себя медицинское вмешательство, направленное на устранение токсинов из организма, и стабилизацию общего состояния пациента. Далее начинается реабилитация, которая помогает закрепить достигнутые результаты и восстановить психоэмоциональное состояние пациента. Для выбора подходящего стационара стоит ознакомиться с отзывами и дополнительной информацией о клинике, а также уточнить, в каком районе города она расположена.
Углубиться в тему – https://narkologicheskij-staczionar-sankt-peterburg-1.ru/
Наркологический стационар в Санкт-Петербурге: эффективное лечение, детоксикация и медицинская поддержка в наркологической клинике «Похмельная служба»
Ознакомиться с деталями – [url=https://narkologicheskij-staczionar-sankt-peterburg-3.ru/]наркологическая клиника стационар в санкт-петербурге[/url]
Реабилитация алкоголиков с анонимной поддержкой предоставляет несколько значительных преимуществ. Она помогает избежать социальных предрассудков, связанных с зависимостью, и позволяет пациенту сосредоточиться исключительно на своем здоровье и процессе восстановления. Это особенно важно для тех, кто чувствует себя изолированным или боится осуждения со стороны окружающих. Анонимность также способствует большему доверию к лечению и уменьшает внутреннее сопротивление пациента.
Получить больше информации – [url=https://reabilitacziya-alkogolikov-moskva-4.ru/]www.domen.ru[/url]
Обращение на стадии, когда человек не может самостоятельно справиться с зависимостью, значительно повышает шансы на успешное лечение и восстановление. Важно начать лечение на раннем этапе, когда физическая и психологическая зависимость еще не столь выражены.
Подробнее можно узнать тут – [url=https://narkologicheskaya-pomoshh-voronezh-4.ru/]вызов наркологической помощи в воронеже[/url]
Выезд врача на дом рассматривают в ситуациях, когда человеку тяжело добраться до медицинского учреждения, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстро получить очную оценку состояния. После осмотра определяют, допустим ли домашний формат, нужна ли капельница, достаточно ли наблюдения на дому или следует сразу рассматривать другой объем помощи. Если подобные эпизоды повторяются, дальнейшее обсуждение может касаться не только текущего состояния, но и лечения алкоголизма, кодирования, участия психолога, психиатра и реабилитации. В таких случаях наркологическая помощь рассматривается шире, чем разовый вызов на дом.
Получить больше информации – [url=https://narkolog-na-dom-moskva-20.ru/]нарколог на дом цена[/url]
Дополнительным поводом для обращения становится состояние, при котором больному тяжело вставать, пить воду, есть, спокойно лежать или переносить обычную бытовую нагрузку. В таких ситуациях домашний осмотр помогает быстрее определить, какого объема помощи достаточно на текущем этапе. Если обращение связано не только с алкоголем, но и с подозрением на употребление наркотиков, оценка проводится особенно осторожно, поскольку при наркомании клиническая картина может быть иной.
Получить дополнительные сведения – [url=https://narkolog-na-dom-moskva-21.ru/]запой нарколог на дом москва[/url]
Похмельный синдром сопровождается головной болью, слабостью, тошнотой, сухостью во рту и нарушением сна, что часто возникает после запоя или при алкоголизме. Эти симптомы появляются из-за накопления токсинов и нарушения водно-солевого баланса. Капельница помогает ускорить выведение вредных веществ и восстановить нормальные функции организма, снижая нагрузку на внутренние системы и помогая человеку быстрее выйти из состояния запоев.
Ознакомиться с деталями – [url=https://kapelnicza-ot-pokhmelya-voronezh-5.ru/]капельница от похмелья вызов на дом[/url]
Капельница от похмелья в Воронеже с нормализацией состояния и поддержкой организма в наркологической клинике «Похмельная служба»
Выяснить больше – [url=https://kapelnicza-ot-pokhmelya-voronezh-6.ru/]капельница от похмелья анонимно в воронеже[/url]
В Воронеже капельница от похмелья применяется в ситуациях, когда симптомы выражены и не проходят самостоятельно, особенно после запоя или в запое. Врач проводит консультацию, оценивает состояние пациента, выраженность интоксикации и принимает решение о проведении процедуры. Важно, что лечение направлено не только на снятие симптомов, но и на восстановление организма после алкоголизма. При необходимости можно оставить заявку и уточнить цены или получить помощь бесплатно в рамках первичной консультации.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья анонимно в воронеже[/url]
Капельница от запоя с детоксикацией организма в Нижнем Новгороде представляет собой одну из самых эффективных процедур для быстрого улучшения состояния пациента, страдающего от алкогольной зависимости. Такой подход направлен не только на устранение токсинов, но и на восстановление нормального функционирования внутренних органов, которые пострадали от длительного употребления алкоголя.
Узнать больше – [url=https://kapelnica-ot-zapoya-nizhnij-novgorod-4.ru/]поставить капельницу от запоя в нижнем новгороде[/url]
Капельница от похмелья — это медицинская процедура, направленная на быстрое устранение симптомов алкогольной интоксикации и восстановление нормальной работы организма. При выраженном похмельном синдроме самостоятельные методы часто оказываются недостаточными, поскольку не воздействуют на причины состояния. В наркологической клинике «Похмельная служба» используется инфузионная терапия с круглосуточным выездом специалиста, что позволяет начать лечение сразу после обращения.
Разобраться лучше – http://kapelnicza-ot-pokhmelya-voronezh-7.ru/
Услуги нарколога на дому в Самаре включают не только экстренный осмотр, но и комплекс медицинских мероприятий, направленных на снижение интоксикации, облегчение тяжелых симптомов и общее восстановление состояния пациента. Объем помощи зависит от клинической картины, длительности употребления алкоголя или других психоактивных веществ, возраста, хронических заболеваний и текущих рисков. Врач подбирает схему индивидуально, исходя из того, какие задачи необходимо решить в конкретный момент — снять острые проявления, стабилизировать самочувствие или подготовить пациента к дальнейшему лечению зависимости.
Получить дополнительные сведения – [url=https://narkolog-na-dom-samara-5.ru/]www.domen.ru[/url]
Острые состояния могут проявляться по-разному: от выраженной слабости, тошноты, тремора и бессонницы до мучительной ломки, резкой тревоги, скачков артериального давления, учащенного сердцебиения, раздражительности и спутанности сознания. У пациентов с хроническими заболеваниями, в пожилом возрасте или после длительного употребления риски возрастают еще сильнее. Особенно опасно ориентироваться только на внешнее впечатление, потому что даже в тех случаях, когда человек находится дома и формально «в сознании», его состояние уже может требовать медицинского вмешательства.
Узнать больше – [url=https://narkologicheskaya-pomoshh-voronezh.ru/]скорая наркологическая помощь[/url]
Особое внимание мы уделяем психологической составляющей. Наркологическая помощь в Воронеже в «Клиника Плюс» — это не только физическое очищение, но и работа с мотивацией, разрушение психологических триггеров зависимости. Родственники получают отдельную поддержку: консультации психолога помогают правильно выстроить общение с зависимым человеком и мотивировать его на дальнейшее лечение. Реабилитация может проходить амбулаторно или в стационаре партнёрских центров с комфортабельными условиями, где пациенты находятся под круглосуточным наблюдением.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-voronezh-2.ru/]наркологическая помощь воронеж[/url]
Выезд нарколога на дом в Самаре представляет собой структурированный медицинский процесс, направленный на быстрое облегчение состояния пациента и устранение последствий интоксикации. Все этапы оказания помощи проводятся с учетом клинической картины, длительности употребления и индивидуальных особенностей организма. В случае алкоголизма могут быть предложены процедуры кодирования, а также вывод из состояния запоя. При необходимости подключается психиатр для дополнительной оценки и лечения.
Изучить вопрос глубже – http://narkolog-na-dom-samara-6.ru/
Под этим термином понимается не универсальный набор процедур, а адаптивный протокол, который формируется после осмотра, сбора анамнеза и оценки рисков. На первом этапе задача врача — стабилизировать состояние, провести качественный детокс, купировать острую интоксикацию или абстиненцию, восстановить водно-солевой баланс и нормализовать сон. Однако качественная помощь не останавливается на снятии симптомов. Она обязательно включает планирование дальнейшего маршрута, учитывающего стаж употребления, наличие сопутствующих заболеваний, психологический статус и готовность пациента к изменениям. Мы понимаем, что каждый случай уникален, поэтому в клинике применяем только доказательные протоколы, исключающие шаблонные решения и подменяющие маркетинговые обещания медицинской логикой.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-pomoshh-voronezh-3.ru/]вызов наркологической помощи воронеж[/url]
Капельница от запоя — это эффективное медицинское вмешательство, направленное на быстрое восстановление организма после длительного злоупотребления алкоголем. Процесс лечения с использованием капельницы способствует быстрому выводу токсинов, восстановлению водно-электролитного баланса и нормализации общего состояния пациента. Капельница оказывает комплексное воздействие на организм, улучшая его самочувствие уже в течение первых часов после процедуры.
Исследовать вопрос подробнее – [url=https://kapelnica-ot-zapoya-nizhnij-novgorod-5.ru/]вызов на дом капельницы от запоя в нижнем новгороде[/url]
Наркологическая помощь в Воронеже: срочный выезд нарколога, капельницы и лечение зависимостей в наркологической клинике «Клиника Плюс».
Получить дополнительные сведения – http://narkologicheskaya-pomoshh-voronezh-1.ru
Многие пациенты и их родственники выбирают выезд врача на дом, когда пациент не в состоянии самостоятельно приехать в клинику. Домашняя помощь подходит в ситуациях, когда состояние пациента резко ухудшается, и важно начать лечение как можно быстрее.
Получить дополнительные сведения – [url=https://narkologicheskaya-pomoshh-voronezh-4.ru/]оказание наркологической помощи[/url]
Капельница от похмелья — это эффективный способ экстренной помощи, предназначенный для того, чтобы помочь организму быстро восстановиться после злоупотребления алкоголем. В наркологической клинике «Частный медик 24» в Самаре мы предоставляем услугу безопасной детоксикации и восстановления 24/7. Капельница помогает организму вывести токсины, восстановить водно-электролитный баланс и улучшить общее состояние пациента, не создавая дополнительных нагрузок на сердце, печень и почки.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-samara-2.ru/]капельница от похмелья вызов на дом в самаре[/url]
Наркологическая помощь в Воронеже: анонимное лечение алкоголизма и наркомании, круглосуточная помощь в наркологической клинике «Клиника Плюс».
Детальнее – [url=https://narkologicheskaya-pomoshh-voronezh-2.ru/]круглосуточная наркологическая помощь[/url]
Нарколог на дом в Екатеринбурге: круглосуточный выезд, детоксикация и лечение зависимостей в наркологической клинике «НЕО+».
Подробнее можно узнать тут – [url=https://narkolog-na-dom-ekaterinburg-1.ru/]вызвать нарколога на дом в екатеринбурге[/url]
Дополнительным поводом для вызова врача становится состояние, при котором больному трудно вставать, пить воду, есть, сохранять спокойствие или ориентироваться в самочувствии. В таких случаях осмотр на дому позволяет быстрее определить дальнейший маршрут помощи. Иногда уже первый звонок помогает понять, допустим ли домашний формат или лучше сразу рассматривать вывод в стационаре.
Получить больше информации – [url=https://narkolog-na-dom-ekaterinburg-4.ru/]нарколог на дом вывод екатеринбург[/url]
Для жителей Самары выезд нарколога на дом — это удобный и быстрый способ получить неотложную помощь при алкогольной или наркотической зависимости. Когда состояние пациента ухудшается и он не может самостоятельно обратиться за помощью, нарколог на дом становится единственным правильным решением. Важно понимать, что симптоматика абстиненции может развиваться стремительно, и чем быстрее будет оказана помощь, тем меньше рисков для здоровья пациента.
Подробнее тут – [url=https://narkolog-na-dom-samara-1.ru/]нарколог на дом цена самара[/url]
Нарколог на дом в Екатеринбурге востребован в ситуациях, когда человеку нужна врачебная помощь после употребления алкоголя, при запое, выраженном похмельном синдроме, нарушении сна, тревоге, скачках давления, слабости и других признаках ухудшения самочувствия. Такой формат обращения часто выбирают семьи, которые хотят вызвать врача без поездки в клинику и быстро получить консультацию по состоянию больного. Домашний выезд особенно важен тогда, когда требуется детоксикация, наблюдение после нескольких дней употребления спиртного и оценка рисков, связанных с последствиями алкоголизма.
Получить больше информации – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]нарколог на дом анонимно[/url]
Клиника «Клиника Плюс» предлагает комплексную наркологическую помощь в Воронеже, включая выезд нарколога на дом, медикаментозную терапию для вывода из запоя и реабилитацию. Мы понимаем, как важно для пациентов и их близких получить поддержку именно в тот момент, когда она нужна.
Подробнее тут – [url=https://narkologicheskaya-pomoshh-voronezh-4.ru/]наркологическая помощь на дому в воронеже[/url]
При необходимости врач может расширить состав капельницы, ориентируясь на жалобы пациента и клиническую картину:
Получить дополнительную информацию – [url=https://kapelnicza-ot-pokhmelya-samara-7.ru/]капельница от похмелья цена в самаре[/url]
Наркологический стационар с комфортными условиями сочетает в себе высококлассное медицинское обслуживание и удобства, которые способствуют более быстрому восстановлению пациента. В таких клиниках пациенты не только получают лечение от зависимости, но и имеют возможность восстановиться в комфортных условиях, что важно для психоэмоционального состояния. Комфортные условия способствуют улучшению настроения, уменьшению стресса и созданию более эффективной атмосферы для лечения. В случае запоя или алкоголизма врач может предоставить помощь на дому, чтобы стабилизировать состояние пациента до перевода в стационар.
Подробнее тут – [url=https://narkologicheskij-staczionar-sankt-peterburg-4.ru/]частный наркологический стационар[/url]
Very interesting information!Perfect just what I was looking for! “Neurotics build castles in the air, psychotics live in them. My mother cleans them.” by Rita Rudner.
I appreciate, result in I found just what I was taking a look for. You’ve ended my 4 day lengthy hunt! God Bless you man. Have a nice day. Bye
Зависимость редко начинается как «всё плохо». Чаще это выглядит как способ справиться с напряжением: расслабиться после тяжёлого дня, быстрее уснуть, пережить стресс или конфликт. Постепенно употребление становится регулярным, дозы растут, а трезвость даётся всё тяжелее. При попытке остановиться появляются бессонница, тревога, внутренний тремор, потливость, тошнота, скачки давления, раздражительность. В этот момент человек пьёт уже не ради удовольствия, а чтобы не столкнуться с ухудшением. Наркологическая клиника в Клину нужна, чтобы перевести ситуацию в понятный медицинский процесс: сначала оценка состояния и рисков, затем безопасная стабилизация, после — лечение зависимости и профилактика повторения.
Выяснить больше – [url=https://narkologicheskaya-klinika-klin12.ru/]наркологическая клиника клинский район московская московская область[/url]
В наркологической клинике «Путь Равновесия» вывод из запоя рассматривают как клиническую задачу, а не как разовую процедуру. Это означает, что помощь начинается с оценки рисков и особенностей состояния, затем проводится детоксикация и стабилизация с учётом давления, пульса, дыхания, признаков обезвоживания и сопутствующих заболеваний, а после — формируется план на ближайшие часы и 1–3 дня. Такой план важен потому, что запой не заканчивается в момент, когда стало легче после первой помощи: волнообразность отмены часто проявляется именно вечером, когда усиливаются тревога и бессонница, и без понятных ориентиров человек легко срывается в повторное употребление.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-orekhovo-zuevo12.ru/]vyvod iz zapoya na domu orekhovo[/url]
Детоксикация в основном фокусируется на печени и почках, помогая этим органам быстрее справляться с продуктами распада алкоголя. Такой подход гарантирует не только улучшение самочувствия, но и восстановление работы внутренних органов, которые пострадали в процессе злоупотребления алкоголем.
Узнать больше – [url=https://kapelnicza-ot-pokhmelya-samara-16.ru/]капельница от похмелья на дом в самаре[/url]
Капельница от похмелья в Самаре используется для устранения симптомов алкогольной интоксикации, которые могут включать головную боль, тошноту, слабость, рвоту и обезвоживание. Это достигается за счет введения специальных растворов, которые помогают организму восстановиться и очиститься от токсинов.
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-samara-14.ru/]капельница от похмелья анонимно[/url]
Капельница состоит из нескольких компонентов, которые способствуют восстановлению организма без чрезмерного стресса. Основные элементы включают в себя:
Исследовать вопрос подробнее – [url=https://kapelnicza-ot-pokhmelya-samara-12.ru/]капельница от похмелья на дому в самаре[/url]
Основной задачей капельницы от похмелья является очищение организма от токсинов, которые остаются после метаболизма алкоголя, обеспечивая быстрый вывод вредных веществ. Алкоголь в значительной степени нарушает водно-электролитный баланс, а его продукты распада могут вызывать неприятные симптомы, такие как головная боль, тошнота, слабость, головокружение и сухость во рту. Капельница помогает устранить эти симптомы, улучшить самочувствие и ускорить процесс восстановления организма, при этом при необходимости возможен вызов врача, анонимное лечение, а также дальнейшая реабилитация и помощь при наркомании.
Изучить вопрос глубже – https://kapelnicza-ot-pokhmelya-samara-15.ru
Непрерывный мониторинг витальных показателей позволяет фиксировать малейшие изменения в состоянии пациента и своевременно вносить коррективы в терапевтический план. В палатах клиники «Стармед» установлены системы отслеживания частоты пульса, сатурации, температуры и артериального давления, данные с которых автоматически передаются в медицинскую карту. Медсестры и дежурные врачи проверяют состояние больного по графику, проводят симптоматическую терапию, контролируют прием препаратов и обеспечивают комфортные условия для восстановления. Такая организация процесса исключает хаотичное назначение средств, предотвращает полипрагмазию и гарантирует, что каждый этап детоксикации проходит под строгим клиническим контролем.
Узнать больше – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-8.ru/]vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-8.ru/[/url]
После введения растворов активные вещества быстро распределяются по организму. Это способствует выведению продуктов распада алкоголя, улучшению работы нервной системы и восстановлению энергетического баланса. Уже в процессе инфузии уменьшаются головная боль, тошнота и слабость.
Ознакомиться с деталями – [url=https://kapelnicza-ot-pokhmelya-samara-8.ru/]капельница от похмелья в самаре[/url]
Алкогольная зависимость часто держится на страхе отмены. Человек заранее боится ночи: что не уснёт, начнётся паника, поднимется давление, появится дрожь и сильная слабость. Поэтому лечение начинается с оценки состояния: сколько длится употребление, как проходит отмена, были ли осложнения, какие заболевания есть у человека и какие препараты он уже принимал. Это позволяет выбрать безопасную тактику и понять, нужен ли стационар или можно начать амбулаторно.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-klin12.ru/]narkologicheskaya-klinicheskaya-bolnica[/url]
Наркологическая помощь в Воронеже актуальна в тех случаях, когда проблема с алкоголем или наркотическими веществами переходит в стадию, когда ситуация требует вмешательства специалиста. Это может быть как первый серьезный срыв, так и долгосрочное ухудшение самочувствия, вызванное хроническим употреблением. В обоих случаях крайне важно не упустить момент и обратиться за помощью, пока болезнь не привела к необратимым последствиям.
Подробнее – [url=https://narkologicheskaya-pomoshh-voronezh-4.ru/]круглосуточная наркологическая помощь воронеж[/url]
Отдельно выделяют ситуации, когда проблема выходит за рамки одного эпизода. Если запои повторяются, усиливаются последствия алкоголизма, нарушается обычный режим жизни, а состояние после употребления становится тяжелее, домашний выезд часто становится первым этапом более последовательной помощи. При выраженном ухудшении самочувствия, признаках отравлении алкоголем или высокой нагрузке на системы организма может потребоваться наблюдение не только дома, но и в стационаре.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg-4.ru/]нарколог на дом цена екатеринбург[/url]
Основой стационарного лечения является инфузионная терапия, направленная на ускоренное выведение токсинов, коррекцию кислотно-щелочного баланса и восстановление метаболических процессов. Стандартная капельница при выходе из запоя включает кристаллоидные и коллоидные растворы, витаминные комплексы группы B и C, гепатопротекторы, антиоксиданты и симптоматические препараты для нормализации сна и снижения тревожности. Состав, объем и скорость инфузии рассчитываются индивидуально с учетом возраста, массы тела, длительности интоксикации, функции почек и печени, а также наличия аллергических реакций. Мы быстро купируем мучительные проявления абстиненции, восстанавливаем аппетит, устраняем мышечные спазмы и нормализуем суточные ритмы. При необходимости подключаются препараты для стабилизации сердечного ритма, коррекции артериального давления и защиты нейрональных структур от эксайтотоксичности. Все медикаменты сертифицированы, применяются в строгом соответствии с клиническими рекомендациями Минздрава РФ и не вызывают вторичной зависимости. Дозировки ежедневно пересматриваются лечащим врачом на основе лабораторных анализов и клинической динамики, что гарантирует высокий уровень качества медицинской помощи и безопасность пациента. Снятие острых симптомов происходит уже в первые сутки, что значительно улучшает общее самочувствие и возвращает способность к адекватному восприятию действительности.
Углубиться в тему – http://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-7.ru/
Наркологическая помощь в Воронеже: эффективное лечение запоя, детокс и поддержка специалистов в наркологической клинике «Клиника Плюс».
Детальнее – [url=https://narkologicheskaya-pomoshh-voronezh-3.ru/]наркологическая помощь на дому в воронеже[/url]
Когда требуется нарколог на дом, обычно речь идёт не о «консультации на будущее», а о ситуации, которая уже мешает жить здесь и сейчас: затяжной запой, тяжёлая абстиненция, сильная тревога и бессонница, тремор, скачки давления, рвота, выраженная слабость, паника или состояние, при котором человек не готов ехать в клинику. В Пушкино выездная помощь востребована ещё и потому, что многим важно сохранить приватность и не вовлекать лишних людей: дома проще согласиться на осмотр, не тратить силы на дорогу и избежать стрессовой смены обстановки. В наркологической клинике «Стабильный Выбор» выезд врача строится по принципу «быстро, но безопасно»: сначала оценка состояния и рисков, затем индивидуальная тактика стабилизации и понятный план на ближайшие часы и сутки.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-pushkino12.ru/]выезд нарколога на дом[/url]
References:
Best roulette bets
References:
https://silver-play-casino.online-spielhallen.de/
Эта процедура помогает избежать агрессивных методов лечения, таких как медикаментозные таблетки, и оказывает мягкое, но эффективное влияние на организм.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-samara-16.ru/]капельница от похмелья самара[/url]
Часто люди приходят не во время запоя, а когда видят, что зависимость стала управлять жизнью: регулярное употребление, ухудшение памяти и внимания, проблемы на работе, потеря интересов, рост тревоги и раздражительности, срывы после периодов трезвости. Плановое обращение даёт больше возможностей: можно спокойнее подобрать программу, выстроить режим, подключить работу с психологическими факторами и профилактику рецидива. Это снижает вероятность того, что помощь понадобится уже в экстренном режиме.
Узнать больше – http://narkologicheskaya-klinika-orekhovo-zuevo12.ru/vrach-narkologicheskaya-klinika-v-orekhovo-zuevo/https://narkologicheskaya-klinika-orekhovo-zuevo12.ru
Особое внимание мы уделяем психологической составляющей. Нарколог на дом в Екатеринбурге в «НЕО+» — это не только физическое очищение, но и работа с мотивацией, разрушение психологических триггеров зависимости. Зависимость разрушает жизнь, поэтому мы предлагаем психотерапевтическое сопровождение. Родственники получают отдельную поддержку: консультации психолога помогают правильно выстроить общение с зависимым человеком и мотивировать его на дальнейшее лечение. Реабилитация может проходить амбулаторно или в стационаре партнёрских центров с комфортабельными условиями, где пациенты находятся под круглосуточным наблюдением.
Ознакомиться с деталями – https://narkolog-na-dom-ekaterinburg-1.ru
Отдельный риск — самолечение препаратами. Часто пытаются «уснуть» с помощью снотворных или седативных, принимают лекарства от давления без контроля цифр, смешивают алкоголь с успокоительными. Такие комбинации могут влиять на дыхание, сердечный ритм и уровень сознания. В итоге состояние становится менее предсказуемым, а риск осложнений — выше. Медицинский вывод из запоя начинается с того, что врач собирает информацию о том, что уже принималось, и оценивает состояние, чтобы не допустить опасных сочетаний и ошибок в тактике.
Разобраться лучше – [url=https://vyvod-iz-zapoya-zhukovskij12.ru/]нарколог вывод из запоя в жуковском[/url]
Домашние попытки обычно идут по двум сценариям. Первый — «пить понемногу, чтобы не трясло», что продлевает запой и усиливает истощение. Второй — резко прекратить и «терпеть», после чего симптомы отмены усиливаются волной, особенно ночью, и человек снова пьёт из страха. Врач помогает избежать этих крайностей: стабилизировать состояние и дать план, который делает первые сутки предсказуемыми и безопасными.
Выяснить больше – [url=https://narkologicheskaya-klinika-klin12.ru/]narkologicheskaya-klinika-klinskij-rajon[/url]
Эти компоненты вводятся в организме пациента постепенно, что позволяет обеспечить мягкое восстановление без резких скачков состояния. В отличие от интенсивных процедур, такой подход гарантирует, что организм восстанавливается более комфортно, не подвергаясь излишнему стрессу.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-samara-12.ru/]капельница от похмелья на дом в самаре[/url]
Непрерывный мониторинг витальных показателей позволяет фиксировать малейшие изменения в состоянии пациента и своевременно вносить коррективы в терапевтический план. В палатах клиники «Стармед» установлены системы отслеживания частоты пульса, сатурации, температуры и артериального давления, данные с которых автоматически передаются в медицинскую карту. Медсестры и дежурные врачи проверяют состояние больного по графику, проводят симптоматическую терапию, контролируют прием препаратов и обеспечивают комфортные условия для восстановления. Такая организация процесса исключает хаотичное назначение средств, предотвращает полипрагмазию и гарантирует, что каждый этап детоксикации проходит под строгим клиническим контролем.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-8.ru/]вывод из запоя в стационаре анонимно[/url]
Состав капельницы от похмелья зависит от состояния пациента и специфики его симптомов. Важно, чтобы капельница включала компоненты, направленные на улучшение общего состояния, восстановление водно-солевого баланса и поддержку работы внутренних органов.
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-samara-14.ru/]капельница от похмелья самара[/url]
References:
Wolfsburg
References:
https://bayern-jackpot-casino.online-spielhallen.de/
References:
Bergisch Gladbach
References:
https://krypto-casino.online-spielhallen.de/
Дополнительным поводом для вызова врача становится состояние, при котором больному трудно вставать, пить воду, есть, сохранять спокойствие или ориентироваться в самочувствии. В таких случаях осмотр на дому позволяет быстрее определить дальнейший маршрут помощи. Иногда уже первый звонок помогает понять, допустим ли домашний формат или лучше сразу рассматривать вывод в стационаре.
Выяснить больше – [url=https://narkolog-na-dom-ekaterinburg-4.ru/]нарколог на дом екатеринбург[/url]
Помощь начинается с первичной оценки. Врач уточняет длительность запоя, время последнего приёма алкоголя, ведущие симптомы, хронические заболевания, прошлые осложнения, аллергии, а также препараты, которые пациент уже принимал самостоятельно. Далее проводится осмотр: измеряются давление и пульс, оценивается дыхание, температура, признаки обезвоживания, уровень сознания, выраженность тремора и тревоги. На основании этой информации выбирается тактика и формат — на дому, амбулаторно или в стационаре, если риски высокие.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-orekhovo-zuevo12.ru/]chastnyj vyvod iz zapoya[/url]
References:
Bergisch Gladbach
References:
https://the-california-hotel-and-casino-las-vegas.online-spielhallen.de/
References:
Oldenburg
References:
https://casino-online-paypal-bezahlen.online-spielhallen.de/
Основой стационарного лечения является инфузионная терапия, направленная на ускоренное выведение токсинов, коррекцию кислотно-щелочного баланса и восстановление метаболических процессов. Стандартная капельница при выходе из запоя включает кристаллоидные и коллоидные растворы, витаминные комплексы группы B и C, гепатопротекторы, антиоксиданты и симптоматические препараты для нормализации сна и снижения тревожности. Состав, объем и скорость инфузии рассчитываются индивидуально с учетом возраста, массы тела, длительности интоксикации, функции почек и печени, а также наличия аллергических реакций. Мы быстро купируем мучительные проявления абстиненции, восстанавливаем аппетит, устраняем мышечные спазмы и нормализуем суточные ритмы. При необходимости подключаются препараты для стабилизации сердечного ритма, коррекции артериального давления и защиты нейрональных структур от эксайтотоксичности. Все медикаменты сертифицированы, применяются в строгом соответствии с клиническими рекомендациями Минздрава РФ и не вызывают вторичной зависимости. Дозировки ежедневно пересматриваются лечащим врачом на основе лабораторных анализов и клинической динамики, что гарантирует высокий уровень качества медицинской помощи и безопасность пациента. Снятие острых симптомов происходит уже в первые сутки, что значительно улучшает общее самочувствие и возвращает способность к адекватному восприятию действительности.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-7.ru/]быстрый вывод из запоя в стационаре[/url]
References:
Northern lights casino
References:
https://graph.org/Kingbillywin-Casino-Login-04-27
References:
Play casino online
References:
https://graph.org/Online-Casinos-In-Australia-04-27
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге предлагает помощь в комфортных условиях с акцентом на безопасность пациента. Врачи подбирают схему лечения с учётом состояния, анамнеза и сопутствующих рисков, проводят медицинскую стабилизацию и помогают выстроить план дальнейшего восстановления. Анонимность и профессионализм остаются приоритетом.
Получить больше информации – [url=https://new-narkolog.ru/stati/alkogolizm-odnogo-iz-roditeley.html]алкоголь и семья[/url]
«Оптимед» — наркологическая клиника в Кирове, где помогают справиться с алкоголизмом и наркоманией. Пациентам доступен вывод из запоя и длительная реабилитация. Центр работает анонимно и обеспечивает комплексное сопровождение на всех этапах лечения.
Подробнее можно узнать тут – [url=https://optimed-narkolog.ru/anonimnoe-lechenie-narkomanii/]пройти лечение от наркомании[/url]
В московской клинике «НаркоЗдравие» пациенты могут пройти лечение наркомании и алкоголизма, воспользоваться услугой нарколога на дом, пройти кодирование или вывод из запоя. Реабилитационные программы направлены на долгосрочное укрепление ремиссии.
Подробнее – [url=https://narko-zdravie.ru/uslugi/vyvod-iz-zapoya/kapelnitsa-ot-zapoya/]капельница от запоя на дому москва[/url]
Ожидание, что все пройдет само, чаще только затягивает проблему. Если повторяются срывы, растет раздражительность, ухудшается сон, появляются скрытность, долги, конфликты или навязчивые мысли об игре, консультация аддиктолога становится вполне обоснованным шагом. Важно учитывать и семейный фактор: нередко именно близкие первыми замечают ложь, отрицание проблемы и нарастающее напряжение дома.
Подробнее тут – [url=http://msk-clinica-plus.ru/]консультант аддиктолог[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Познакомиться с результатами исследований – [url=https://illady.ru/eto-interesno/11174-soxranenie-domashnego-ochaga-kak-zavisimost-razrushaet-uyut-i-gde-najti-vyxod.html]наркологический частный центр[/url]
«НОВЫЙ НАРКОЛОГ» в СПб — это профессиональная наркология, где лечение зависимости строится на комплексном подходе. Пациентам доступны детоксикационные процедуры, медикаментозная поддержка и психотерапевтическое сопровождение. Внимание к безопасности и постоянный контроль состояния помогают пройти лечение максимально предсказуемо.
Подробнее можно узнать тут – [url=https://new-narkolog.ru/stati/alkogol-i-fizicheskie-nagruzki.html]алкоголь и физические нагрузки[/url]
Процесс реабилитации алкоголиков включает в себя несколько методов, направленных на восстановление как физического, так и психоэмоционального состояния пациента. В Москве доступны различные программы, от традиционной детоксикации до современных подходов, при этом в отдельных случаях предусматривается вывод данных о состоянии пациента и динамике лечения при алкогольной зависимости, включая когнитивно-поведенческую терапию и арт-терапию.
Получить больше информации – [url=https://reabilitacziya-alkogolikov-moskva-3.ru/]алкоголик реабилитация наркоманов[/url]
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Обратиться к источнику – [url=https://womanka.com/zdorove/meditsinskie-strategii-vosstanovleniya-organizma-posle-intensivnyh-nagruzok-i-intoksikatsii]нарколог на дом частный[/url]
Клиника «Оптимед» в Кирове оказывает профессиональную наркологическую помощь. Пациентам доступны лечение алкоголизма и наркомании, вывод из запоя и программы реабилитационного центра. Специалисты подбирают индивидуальные методы восстановления для стабильного результата.
Получить больше информации – [url=https://optimed-narkolog.ru/reabilitatsionnyy-tsentr/]социально реабилитационный центр[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Читать дальше – [url=https://dettka.com/kriticheskaya-stadiya-zapoya-kak-raspoznat-opasnost-i-spasti-blizkogo-cheloveka/]вывод из запоя стационар[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Получить дополнительные сведения – [url=https://megamcpe.com/health/bezopasnyj-vyhod-iz-zapoya-proverennye-mediczinskie-metody-i-pervaya-pomoshh.html]прокапаться на дому[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить дополнительную информацию – [url=https://dvedoli.com/zdorove/istinnaya-krasota-pochemu-vneshnost-zavisit-ot-chistoty-organizma-i-detoksikaczii.html]наркологическая платная клиника[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Полная информация здесь – [url=https://sovety4mom.ru/alkogolnaja-intoksikacija-gran-mezhdu-domashnim-lecheniem-i-jekstrennoj-medicinskoj-pomoshhju/]нарколог на дому[/url]
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Познакомиться с результатами исследований – [url=https://mastersolution.ru/2026/04/17/tenevaya-storona-detstva-kak-roditelskaya-zavisimost-formiruet-lichnost-rebenka-i-gde-iskat-vyhod/]вывод из запоя на дому цена[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Перейти к статье – [url=https://kapitosha.net/zapoj-u-blizkogo-kogda-molchat-nelzya-i-pora-dejstvovat.html]вызов наркологической помощи[/url]
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Интересует подробная информация – [url=https://belady.online/health/alkogolizm-kak-verhushka-ajsberga-skrytye-psihiatricheskie-patologii-za-fasadom-zavisimosti/]цены на вывод из запоя на дому[/url]
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Ознакомиться с отчётом – [url=https://soapy.net.ru/2026/04/16/zdorovoe-vosstanovlenie-kak-privesti-organizm-v-normu-posle-cheredy-prazdnichnyh-zastoliy/]вывод из запоя дешево[/url]
Платная наркологическая клиника «НОВЫЙ НАРКОЛОГ» в Санкт-Петербурге предлагает лечение зависимости в комфортных условиях — амбулаторно или в стационаре, по медицинским показаниям. Специалисты оценивают риски, подбирают схему терапии и сопровождают пациента до стабилизации состояния. Анонимность и профессиональная этика обеспечивают спокойное обращение за помощью.
Углубиться в тему – [url=https://new-narkolog.ru/stati/ukol-ot-alkogolizma-pravda-i-mify.html]созависимость в семье алкоголика[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Продолжить изучение – [url=https://xozyaika.com/alkogolnaya-zavisimost-v-seme-plan-dejstvij-dlya-soxraneniya-zdorovya-i-nervov/]нарколог на дом частный[/url]
Неотъемлемой частью программы становится психотерапия — работа с мотивацией, психологической поддержкой, поиском и устранением “триггеров” зависимости, проработка самооценки, стрессоустойчивости. К работе обязательно подключаются близкие: совместные консультации помогают восстановить доверие, снизить уровень конфликтов, научиться поддерживать без контроля и упрёков.
Получить дополнительную информацию – http://
Реабилитация алкоголиков в Москве с комплексным подходом — это многогранный процесс, включающий в себя не только медицинские процедуры, но и психологическую поддержку, физическую реабилитацию и помощь в социальной адаптации. Профессиональный реабилитационный центр обеспечивает индивидуальный подход к каждому пациенту, включая такие методы, как кодирование и своевременное лечение запоя. Важно отметить, что успешное лечение алкоголизма требует учета множества факторов, таких как степень зависимости, психоэмоциональное состояние пациента, а также его физическое здоровье. Комплексный подход помогает эффективно устранить все составляющие проблемы, минимизируя риски рецидивов.
Ознакомиться с деталями – [url=https://reabilitacziya-alkogolikov-moskva-2.ru/]клиника реабилитации алкоголиков в москве[/url]
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Слушай внимательно — тут важно – [url=https://ladysarafan.ru/semya-i-otnosheniya/kak-pomoch-blizkomu-vyjti-iz-zapoya-rukovodstvo-dlya-semi-kotoroe-realno-rabotaet]лечение наркомании на дому[/url]
Нарколог на дом в Екатеринбурге: круглосуточный выезд, детоксикация и лечение зависимостей в наркологической клинике «НЕО+».
Выяснить больше – [url=https://narkolog-na-dom-ekaterinburg-1.ru/]запой нарколог на дом[/url]
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Раскрыть тему полностью – [url=https://divoch.ru/zapoy-i-detoksikatsiya-kak-kapelnitsy-pomogayut-vyyti-iz-opasnogo-sostoyaniya/]вывод из запоя цена воронеж[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Не упусти важное! – [url=https://glamourstudio.spb.ru/pohmele-ili-abstinentsiya-kak-rodstvennikam-raspoznat-opasnoe-sostoyanie/]врач нарколог выезд на дом[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Изучить эмпирические данные – [url=https://qllq.ru/meditsina/trezvost-kak-dar-predkov-put-istseleniya-dushi-i-tela-cherez-ochishhenie/]вывод из запоя на дому в самаре[/url]
Откройте для себя скрытые страницы истории и малоизвестные научные открытия, которые оказали колоссальное влияние на развитие человечества. Статья предлагает свежий взгляд на события, которые заслуживают большего внимания.
А что дальше? – [url=https://lechimsustavy.ru/raznoe/pochemu-alkogol-usilivaet-boli-v-tele-i-sustavah-prichiny-riski-i-puti-vosstanovleniya.html]вывод из запоя с выездом[/url]
Эта информационная заметка предлагает лаконичное и четкое освещение актуальных вопросов. Здесь вы найдете ключевые факты и основную информацию по теме, которые помогут вам сформировать собственное мнение и повысить уровень осведомленности.
Что ещё? Расскажи всё! – [url=https://lifepeople.info/novosti/kogda-prazdnik-idyot-ne-po-planu-pomoshh-vzroslomu-bez-lishnix-glaz/]нарколог на дом круглосуточно воронеж цены[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Лови подробности – [url=https://pczz.msk.su/alkogol-i-stress-v-it-kak-raspoznat-granitsu-i-vovremya-obratitsya-za-pomoschyu/]стоимость капельницы на дому екатеринбург[/url]
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Лови подробности – [url=https://1poortopedii.ru/metody/kogda-prazdniki-zatyanulis-kak-raspoznat-zapoj-i-vernut-blizkogo-cheloveka-k-normalnoj-zhizni.html]вывод из запоя на дому круглосуточно[/url]
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Кликни и узнай всё! – [url=https://spbobrazovanie.ru/ot-ustalosti-k-zavisimosti-kak-vovremya-zametit-trevozhnye-signaly/]вывести из запоя капельница[/url]
References:
Pålidelige casinoer med høj udbetaling
References:
https://gitea.cfpoccitan.org/murray30116420
За выездом врача обращаются в тех случаях, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстрее получить медицинскую консультацию на месте. После осмотра определяют, допустим ли домашний формат, требуется ли капельница, достаточно ли наблюдения на дому или нужен другой объем помощи. Если эпизоды повторяются, в дальнейшем могут обсуждаться лечение алкоголизма, кодирование, участие психолога, реабилитация и более широкая программа помощи при зависимости. Уже на этапе первичного обращения нередко уточняют, как вызвать специалиста, какие услуги доступны на дому и в каких случаях вывод из запоя рассматривают не дома, а в стационаре.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg-4.ru/]нарколог на дом анонимно в екатеринбурге[/url]
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Ознакомиться с деталями – [url=https://biography-live.ru/tyomnaya-storona-slavy-kak-znamenitosti-borolis-s-alkogolizmom/]вывод из запоя капельница нижний новгород[/url]
Этот обзор сосредоточен на различных подходах к избавлению от зависимости. Мы изучим традиционные и альтернативные методы, а также их сочетание для достижения максимальной эффективности. Читатели смогут открыть для себя новые стратегии и подходы, которые помогут в их борьбе с зависимостями.
Углубиться в тему – [url=https://womanfan.ru/trevozhnye-priznaki-alkogolnoy-intoksikatsii-kogda-pora-spasat-blizkogo-cheloveka/]капельница на дому нижний новгород цена от алкоголя[/url]
Процесс реабилитации алкоголиков включает в себя несколько методов, направленных на восстановление как физического, так и психоэмоционального состояния пациента. В Москве доступны различные программы, от традиционной детоксикации до современных подходов, при этом в отдельных случаях предусматривается вывод данных о состоянии пациента и динамике лечения при алкогольной зависимости, включая когнитивно-поведенческую терапию и арт-терапию.
Ознакомиться с деталями – [url=https://reabilitacziya-alkogolikov-moskva-3.ru/]центр реабилитации алкоголиков в москве[/url]
References:
Gevinstprocent
References:
https://livebookmark.stream/story.php?title=bedste-online-casino-udbetaling-hurtige-danske-casinoer-2026
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Почему это важно? – [url=https://северная2а.рф/puteshestviya-s-blizkim-chelovekom-kak-podgotovitsya-k-poezdke-pri-riske-sryva/]выведение из запоя на дому[/url]
Эта публикация обращает внимание на важность профилактики зависимостей. Мы обсудим, как осведомленность и образование могут помочь в предотвращении возникновения зависимости. Читатели смогут ознакомиться с полезными советами и ресурсами, которые способствуют здоровому образу жизни.
Изучить вопрос глубже – [url=https://ogkt.ru/raznoe/kak-alkogol-razrushaet-zhkt-i-kogda-nuzhna-detoksikatsiya.html]капельница от запоя в стационаре[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Полная информация здесь – [url=https://cdmarf.ru/pochemu-alkogol-i-cistit-nesovmestimy-posledstviya-dlya-zdorovya-i-metody-vosstanovleniya/]вывод из запоя круглосуточно[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Читать далее > – [url=https://griffin25.ru/44623-2/]стоимость капельницы в екатеринбурге[/url]
Нарколог на дом в Москве — это формат медицинской помощи, который рассматривают при состояниях после употребления алкоголя, когда больному требуется осмотр врача без поездки в клинику. Чаще всего обращение связано с запоем, выраженным похмельным синдромом, нарушением сна, тревогой, слабостью, тремором, обезвоживанием, скачками давления, сердцебиением и общим ухудшением самочувствия. Дальнейшая тактика зависит от состояния больного на момент осмотра, продолжительности употребления алкоголя, возраста и сопутствующих заболеваний.
Углубиться в тему – [url=https://narkolog-na-dom-moskva-19.ru/]нарколог на дом вывод[/url]
Эта статья погружает вас в увлекательный мир знаний, где каждый факт становится открытием. Мы расскажем о ключевых исторических поворотных моментах и научных прорывах, которые изменили ход цивилизации. Поймите, как прошлое формирует настоящее и как его уроки могут помочь нам строить будущее.
Информация доступна здесь – [url=https://dzintarsshop.ru/siyanie-iznutri-kompleksnyj-gid-po-vosstanovleniyu-organizma-i-kozhi-posle-prazdnichnogo-marafona.html]наркологическая помощь на дому[/url]
Этот краткий обзор предлагает сжатую информацию из области медицины, включая ключевые факты и последние новости. Мы стремимся сделать информацию доступной и понятной для широкой аудитории, что позволит читателям оставаться в курсе актуальных событий в здравоохранении.
Узнать больше – [url=https://stomatologist.org/semeynyy-mikroklimat-i-zdorove-rebenka-nevidimaya-svyaz-mezhdu-obrazom-zhizni-roditeley-i-razvitiem-malysha/]вывод из запоя стационар[/url]
Отдельно оценивают ситуации, когда эпизоды повторяются и становятся частью более устойчивой проблемы. Если после алкоголя регулярно развивается тяжелое состояние, нарушается привычный режим жизни, усиливаются последствия алкоголизма и возникают сложности с контролем употребления, домашний выезд может быть только первым этапом более длинного маршрута помощи. При этом наркологическая помощь может включать не только снятие острых проявлений, но и дальнейшую программу лечения зависимости, если речь идет о длительном течении заболевания.
Подробнее – [url=https://narkolog-na-dom-moskva-19.ru/]нарколог на дом цена[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Погрузиться в детали – [url=https://soft-gear.ru/2026/04/17/ot-stressa-k-zavisimosti-trevozhnye-signaly-trebuyuschie-vmeshatelstva-vracha/]платная наркологическая помощь на дому[/url]
В этой публикации мы обсуждаем современные методы лечения различных заболеваний. Читатели узнают о новых медикаментах, терапиях и исследованиях, которые активно применяются для лечения. Мы нацелены на то, чтобы предоставить практические знания, которые могут помочь в борьбе с недугами.
Подробнее тут – [url=https://gbuzrk-vpb.ru/alkogolnaya-zavisimost-kak-raspoznat-problemu-i-kuda-obratitsya-za-pomoschyu-k-spetsialistam/]вывод из запоя[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Где почитать поподробнее? – [url=https://malishi.online/u-rebenka/ustalost-roditelej-kogda-pora-bit-trevogu/]лечение наркомании на дому[/url]
Вывод из запоя на дому с медицинским контролем — это услуга, которая позволяет пациентам избавиться от алкогольной зависимости в комфортных условиях своего дома. В Екатеринбурге эта услуга становится все более востребованной, поскольку она предоставляет безопасный и эффективный способ вывода человека из запоя, при этом не требуя госпитализации. Процедура сопровождается контролем квалифицированных специалистов, что минимизирует риски и ускоряет процесс восстановления.
Получить больше информации – https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru
В этой статье рассматриваются различные аспекты избавления от зависимости, включая физические и психологические методы. Мы обсудим поддержку, мотивацию и стратегии, которые помогут в процессе выздоровления. Читатели узнают, как преодолеть трудности и двигаться к новой жизни без зависимости.
Секреты успеха внутри – [url=https://жби-юг.рф/hronicheskiy-stress-i-alkogolnaya-zavisimost-kak-raspoznat-i-kuda-obratitsya-za-pomoschyu-v-spb/]вывод из запоя в спб[/url]
Вывод из запоя на дому в Екатеринбурге: эффективное лечение, детоксикация и восстановление организма в наркологической клинике «Детокс»
Изучить вопрос глубже – https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru
Нарколог на дом в Москве: срочный выезд врача, капельницы и помощь при запое в наркологической клинике «Клиника доктора Калюжной».
Получить дополнительную информацию – [url=https://narkolog-na-dom-moskva-17.ru/]narkolog-na-dom-moskva-17.ru/[/url]
Если у пациента наблюдаются эти симптомы, важно своевременно обратиться к специалисту для назначения вывода из запоя на дому, что поможет предотвратить более серьезные осложнения и ускорить процесс восстановления, при этом можно заранее заказать помощь с учетом возраста пациента (в том числе после 40–50 лет), данных больного и особенностей его состояния.
Разобраться лучше – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]вывод из запоя на дому анонимно екатеринбург[/url]
Процесс вывода из запоя на дому с выездом врача в Екатеринбурге включает несколько этапов, начиная с первичного осмотра пациента и заканчивая корректировкой лечения в зависимости от его состояния. Врач-нарколог проводит полный осмотр, анализирует симптомы и составляет план лечения, который включает детоксикацию организма, поддерживающую терапию и медикаментозное лечение для снятия симптомов абстиненции.
Получить дополнительную информацию – https://vyvod-iz-zapoya-na-domu-ekaterinburg-16.ru
Процесс вывода из запоя на дому с выездом врача в Екатеринбурге включает несколько этапов, начиная с первичного осмотра пациента и заканчивая корректировкой лечения в зависимости от его состояния. Врач-нарколог проводит полный осмотр, анализирует симптомы и составляет план лечения, который включает детоксикацию организма, поддерживающую терапию и медикаментозное лечение для снятия симптомов абстиненции.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-16.ru/]нарколог на дом вывод из запоя[/url]
Отдельно оценивают ситуации, когда подобные эпизоды повторяются. Если человек уже не впервые переносит запой, тяжелый выход из него или выраженное ухудшение самочувствия после алкоголя, вопрос обычно выходит за рамки разовой помощи. Тогда уже при первичном обращении рассматривают не только текущую стабилизацию состояния, но и дальнейшие шаги. При затяжном течении проблемы могут обсуждаться лечение зависимости, программа восстановления и условия, при которых потребуется наблюдение в стационаре.
Узнать больше – [url=https://narkolog-na-dom-moskva-17.ru/]запой нарколог на дом[/url]
Когда зависимости становятся хроническими и угрожают жизни пациента, комплексная реабилитация при наркомании в специализированных клиниках Москвы, включая вывод из состояния в стационаре и последующий анализ данных о состоянии пациента, может стать единственным возможным решением. Процесс восстановления включает в себя работу не только с зависимостью, но и с психоэмоциональным состоянием, что делает лечение более эффективным и долговечным.
Получить больше информации – https://reabilitacziya-alkogolikov-moskva-2.ru/
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. При отравление продуктами распада этанола, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Изучить вопрос глубже – http://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/
За выездом врача обращаются в тех случаях, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстрее получить медицинскую консультацию на месте. После осмотра определяют, допустим ли домашний формат, требуется ли капельница, достаточно ли наблюдения на дому или нужен другой объем помощи. Если эпизоды повторяются, в дальнейшем могут обсуждаться лечение алкоголизма, кодирование, участие психолога, реабилитация и более широкая программа помощи при зависимости. Уже на этапе первичного обращения нередко уточняют, как вызвать специалиста, какие услуги доступны на дому и в каких случаях вывод из запоя рассматривают не дома, а в стационаре.
Подробнее – [url=https://narkolog-na-dom-ekaterinburg.ru/]narkolog-na-dom-ekaterinburg.ru/[/url]
Отдельно выделяют ситуации, когда родственники вызывают врача не только из-за текущего состояния, но и потому, что подобные эпизоды повторяются. Если накапливаются последствия алкоголизма, нарушается сон, меняется поведение, появляются устойчивые проблемы дома и в повседневной жизни, разовая помощь обычно рассматривается как первый этап последующей тактики. При тяжелом состоянии, признаках отравлении алкоголем или сочетании нескольких рисков сразу может понадобиться более интенсивное наблюдение в стационаре.
Изучить вопрос глубже – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]нарколог на дом анонимно в екатеринбурге[/url]
В данной публикации мы поговорим о процессе восстановления от зависимости, о том, как вернуть себе нормальную жизнь. Мы обсудим преодоление трудностей, значимость поддержки и наличие программ реабилитации. Читатели смогут узнать о ключевых шагах к успешному восстановлению.
Получить больше информации – [url=https://osteoz.ru/raznoe/trevozhnye-signaly-organizma-kogda-domashnie-metody-bessilny-i-trebuetsya-srochnaya-detoksikatsiya.html]поставить капельницу от запоя на дому цена[/url]
Выезд врача на дом рассматривают в ситуациях, когда человеку тяжело добраться до медицинского учреждения, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстро получить очную оценку состояния. После осмотра определяют, допустим ли домашний формат, нужна ли капельница, достаточно ли наблюдения на дому или следует сразу рассматривать другой объем помощи. Если подобные эпизоды повторяются, дальнейшее обсуждение может касаться не только текущего состояния, но и лечения алкоголизма, кодирования, участия психолога, психиатра и реабилитации. В таких случаях наркологическая помощь рассматривается шире, чем разовый вызов на дом.
Изучить вопрос глубже – [url=https://narkolog-na-dom-moskva-20.ru/]нарколог на дом анонимно москва[/url]
Нарколог на дом в Екатеринбурге — это формат помощи, который рассматривают в тех случаях, когда после употребления алкоголя больному требуется врачебный осмотр без поездки в клинику. Обычно речь идет о запое, выраженном похмельном синдроме, обезвоживании, слабости, треморе, тревоге, бессоннице, скачках давления, сердцебиении и общем ухудшении самочувствия. В такой ситуации состояние оценивают на месте и определяют, допустима ли помощь дома или нужен другой объем наблюдения.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]вызов нарколога на дом екатеринбург[/url]
Нарколог на дом в Екатеринбурге: выезд врача на дом, лечение запоя и консультации в наркологической клинике «НЕО+».
Ознакомиться с деталями – http://narkolog-na-dom-ekaterinburg.ru
Процесс реабилитации алкоголиков с комплексным подходом в Москве состоит из нескольких этапов, начиная от медицинской детоксикации, включающей курс процедур и вывод из состояния зависимости, и заканчивая психологической реабилитацией и социальной адаптацией. Этот процесс занимает обычно от нескольких недель до нескольких месяцев в зависимости от стадии зависимости и состояния пациента. Важной особенностью комплексной реабилитации является внимание не только к физическому состоянию, но и к эмоциональному состоянию пациента, что помогает предотвратить рецидивы и наладить нормальные отношения с окружающим миром.
Выяснить больше – [url=https://reabilitacziya-alkogolikov-moskva-2.ru/]клиника реабилитации алкоголиков город[/url]
В этой публикации мы предлагаем подробные объяснения по актуальным вопросам, чтобы помочь читателям глубже понять их. Четкость и структурированность материала сделают его удобным для усвоения и применения в повседневной жизни.
Кликни, не пожалеешь – [url=https://astmania.ru/novosti-meditsinyi/kak-alkogol-vlijaet-na-dyhanie-i-obshhee-sostojanie-organizma.html]капельница от запоя на дому круглосуточно[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
Узнать из первых рук – [url=https://catsway.ru/nezdorovaya-domashnyaya-obstanovka-razrushaet-zdorove-vashego-pitomtsa/]вывод из запоя воронеж[/url]
После нескольких дней употребления алкоголя организм работает с перегрузкой. Усиливается обезвоживание, ухудшается сон, появляется дрожь, растет тревожность, нарушается аппетит, могут беспокоить скачки давления, сердцебиение, слабость и тошнота. В такой ситуации состояние нередко требует осмотра врача, особенно если самочувствие продолжает ухудшаться или уже были неудачные попытки справиться своими силами. Подобные состояния встречаются не только при последствиях алкоголизма, но и у людей, которые впервые столкнулись с тяжелой интоксикацией после приема спиртного.
Детальнее – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]запой нарколог на дом в екатеринбурге[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Связаться за уточнением – [url=https://newbabe.ru/razvitie/kak-privychka-otca-vypivat-menyaet-zhizn-novorozhdennogo-i-ego-mamy.html]капельница от запоя[/url]
Выбор центра для реабилитации алкоголиков с индивидуальной программой в Москве — это ключевой момент в процессе восстановления. Успех лечения во многом зависит от квалификации специалистов, качества программ и уровня условий, которые предоставляются пациенту. Важно, чтобы клиника предложила не только медицинскую помощь, но и психологическую поддержку, которая является основой для успешной реабилитации. Также стоит учитывать, что в некоторых случаях вывод из запоя или лечение может быть проведено анонимно, а стационарное лечение на летний период может стать удобным решением для более продолжительного и комфортного восстановления пациента.
Подробнее тут – [url=https://reabilitacziya-alkogolikov-moskva.ru/]реабилитация алкоголиков город[/url]
Реабилитация алкоголиков в Москве: лечение зависимости, восстановление и поддержка под контролем специалистов в наркологической клинике «Похмельная служба»
Получить дополнительную информацию – [url=https://reabilitacziya-alkogolikov-moskva-1.ru/]клиника реабилитации алкоголиков в москве[/url]
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
А есть ли продолжение? – [url=https://rak-onkologiya.ru/upotrebleniya-spirtnogo-i-zdorovya-nosovyh-pazuh/]капельница от похмелья воронеж[/url]
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Изучить эмпирические данные – [url=https://karnavalkino.ru/tragedii-za-kadrom-kak-kumiry-millionov-srazhayutsya-s-nevidimym-vragom-v-realnoj-zhizni.html]вызов врача нарколога на дом[/url]
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Продолжить изучение – [url=https://people-of-art.ru/tvorchestvo-i-zavisimost-gde-prohodit-granitsa-i-kak-ne-poteryat-sebya/]вывод из запоя на дому недорого[/url]
Реабилитация алкоголиков — это важный этап на пути к избавлению от зависимости. В Москве существует множество центров, предлагающих реабилитацию с индивидуальной программой, что помогает обеспечить более персонализированный и эффективный подход к каждому пациенту. Индивидуальная программа учитывает физическое и психологическое состояние человека, а также его социальное окружение и личные особенности. Это позволяет добиться лучших результатов в лечении и восстановлении.
Разобраться лучше – [url=https://reabilitacziya-alkogolikov-moskva.ru/]реабилитация алкоголиков стоимость[/url]
Процедура вывода из запоя на дому включает несколько этапов, каждый из которых имеет важное значение для общего улучшения состояния пациента. Главная цель — это не только устранение симптомов абстиненции, но и восстановление нормальной работы органов и систем организма. Врач, который проводит процедуру, использует медикаментозные средства для восстановления водно-солевого баланса, нормализации работы печени, почек и других органов, пострадавших от алкоголя. Также в процесс включаются препараты, которые способствуют снятию нервного напряжения и психоэмоционального стресса.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/]анонимный вывод из запоя на дому[/url]
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
Полная информация здесь – [url=https://menstyle71.ru/chto-delat-esli-blizkiy-ushel-v-zapoy-kogda-mozhno-pomoch-doma-a-kogda-nuzhen-vrach/]вывод из запоя в домашних условиях нарколог 24[/url]
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Познакомиться с результатами исследований – [url=https://vseparazity.ru/zdorove/effektivnyj-vyvod-iz-zapoya-bez-riskov.html]вывод из запоя воронеж[/url]
Анонимность позволяет пациентам сосоточиться на процессе лечения алкогольной зависимости, не переживая о последствиях для своей репутации или безопасности. Важно, чтобы каждый этап был подробно обсужден с пациентом, что помогает снизить уровень стресса и тревожности, связанные с лечением зависимых, включая терапию в стационаре.
Подробнее – [url=https://reabilitacziya-alkogolikov-moskva-4.ru/]алкоголик реабилитация наркоманов город[/url]
Эта статья предлагает уникальную подборку занимательных фактов и необычных историй, которые вы, возможно, не знали. Мы постараемся вдохновить ваше воображение и разнообразить ваш кругозор, погружая вас в мир, полный интересных открытий. Читайте и открывайте для себя новое!
Получить дополнительные сведения – [url=https://perm-pb.ru/patomorfologiya-alkogolnoj-bolezni/]откапаться на дому[/url]
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Читать далее > – [url=https://nycr.org.ru/2026/04/16/srochnaya-meditsinskaya-pomosch-pri-zavisimosti-poshagovyy-plan-dlya-rodstvennikov/]вызов нарколога на дом анонимно[/url]
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Познакомиться с результатами исследований – [url=https://acturia.ru/lichnyj-krizis-direktora/]вывод из запоя на дому цена[/url]
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить дополнительную информацию – [url=https://pykodelki.ru/article/tvorcheskaya-perezagruzka-kak-prikladnoe-iskusstvo-pomogaet-preodolet-pagubnye-privychki.html]нарколог домой[/url]
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
А что дальше? – [url=https://zagar-ok.ru/pravila-zagara/kak-alkogol-menyaet-kozhu-i-vneshnij-vid]вывести из запоя воронеж[/url]
Эта разъяснительная статья содержит простые и доступные разъяснения по актуальным вопросам. Мы стремимся сделать информацию понятной для широкой аудитории, чтобы каждый мог разобраться в предмете и извлечь из него максимум пользы.
Желаете узнать подробности? – [url=https://malishi.online/stati/kak-preodolet-semejnyj-alkogolizm/]вывод из запоя на дому цена[/url]
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Посмотреть всё – [url=https://chistotainfo.ru/zapah/dom/kakie-sredstva-rabotayut-i-kogda-pora-vyzyvat-vracha]сколько стоит прокапать от алкоголизма[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Более подробно об этом – [url=https://volosymoi.ru/vitaminy/polnyj-gid-po-vosstanovleniyu-krasoty-volos-i-kozhi-posle-alkogolnoj-nagruzki.html]вывод из запоя на дому самара круглосуточно[/url]
Эта познавательная публикация погружает вас в море интересного контента, который быстро захватит ваше внимание. Мы рассмотрим важные аспекты темы и предоставим вам уникальные Insights и полезные сведения для дальнейшего изучения.
А что дальше? – [url=https://dizzwizz.ru/semya/kak-podderzhat-blizkogo-i-vernut-ego-k-zhizni.html]капельница от запоя вызов[/url]
При наличии этих симптомов помощь должна быть оказана в кратчайшие сроки. Выезд нарколога позволяет не только стабилизировать состояние, но и определить дальнейшую тактику лечения.
Исследовать вопрос подробнее – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]скорая наркологическая помощь в нижнем новгороде[/url]
Первый этап вывода из запоя на дому – это первичная оценка состояния пациента. Врач, прибывший на вызов, осматривает пациента, проверяет уровень алкоголя в крови, измеряет артериальное давление, пульс и температуру. Это необходимо для того, чтобы определить степень алкогольной интоксикации и выбрать правильную тактику лечения.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]анонимный вывод из запоя на дому екатеринбург[/url]
Если у пациента наблюдаются эти симптомы, важно своевременно обратиться к специалисту для назначения вывода из запоя на дому, что поможет предотвратить более серьезные осложнения и ускорить процесс восстановления, при этом можно заранее заказать помощь с учетом возраста пациента (в том числе после 40–50 лет), данных больного и особенностей его состояния.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]вывод из запоя на дому цена[/url]
Вывод из запоя на дому в Екатеринбурге — это услуга, которая позволяет пациентам пройти лечение в удобных для них условиях, без необходимости посещать стационар. Процедура включает несколько этапов, каждый из которых направлен на снижение уровня алкогольной интоксикации и стабилизацию состояния пациента. Главным преимуществом вывода из запоя на дому является то, что это не только удобно, но и позволяет избежать лишнего стресса, который может быть вызван госпитализацией.
Узнать больше – http://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/
Непрерывный мониторинг витальных показателей — ключевое отличие стационарного формата. В палатах клиники «Элегия Мед» установлены системы отслеживания частоты пульса, сатурации, температуры и артериального давления, данные с которых автоматически передаются в электронную медицинскую карту. Медицинский персонал дежурит круглосуточно, что обеспечивает мгновенную реакцию на ухудшение состояния: коррекцию инфузионной терапии, введение симптоматических препаратов, привлечение смежных специалистов при необходимости. Такая организация процесса исключает хаотичное назначение средств, предотвращает полипрагмазию и гарантирует, что каждый этап детоксикации проходит под строгим клиническим контролем. Контроль состояния пациента в режиме реального времени позволяет врачам оперативно корректировать терапию и минимизировать риски для здоровья.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]стационар вывод из запоя[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. При отравление продуктами распада этанола, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Выяснить больше – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/[/url]
Выбор между домашней помощью и стационарным лечением определяется не удобством, а медицинской целесообразностью. В условиях клиники исключаются внешние триггеры, обеспечивается изоляция от источников алкоголя и создается контролируемая среда, где терапевтические решения принимаются на основе объективных показателей. Такой подход критически важен для предотвращения осложнений, минимизации дискомфорта абстиненции и формирования устойчивой базы для дальнейшей противорецидивной работы.
Получить дополнительные сведения – https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/
Реабилитация алкоголиков в Москве: комплексное лечение и восстановление под наблюдением специалистов в наркологической клинике «Похмельная служба»
Получить больше информации – [url=https://reabilitacziya-alkogolikov-moskva-3.ru/]reabilitacziya-alkogolikov-moskva-3.ru/[/url]
Наиболее частыми причинами обращения становятся запой, выраженная слабость, тремор, тревога, бессонница, тошнота, нестабильное давление, учащенный пульс и ощущение физического истощения. Эти проявления могут сочетаться между собой и усиливаться после прекращения употребления алкоголя, особенно если эпизод длился несколько дней подряд.
Углубиться в тему – https://narkolog-na-dom-moskva-20.ru/
Выезд врача на дом рассматривают в ситуациях, когда человеку тяжело добраться до медицинского учреждения, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстро получить очную оценку состояния. После осмотра определяют, допустим ли домашний формат, нужна ли капельница, достаточно ли наблюдения на дому или следует сразу рассматривать другой объем помощи. Если подобные эпизоды повторяются, дальнейшее обсуждение может касаться не только текущего состояния, но и лечения алкоголизма, кодирования, участия психолога, психиатра и реабилитации. В таких случаях наркологическая помощь рассматривается шире, чем разовый вызов на дом.
Подробнее можно узнать тут – [url=https://narkolog-na-dom-moskva-20.ru/]нарколог на дом анонимно в москве[/url]
Помощь на дому рассматривают при состояниях, которые сопровождаются выраженным ухудшением самочувствия после алкоголя. Обычно речь идет о нескольких днях запоя, тяжелом похмелье, бессоннице, тревоге, дрожи в руках, слабости, тошноте, сухости во рту, отсутствии аппетита и признаках обезвоживания. В таких случаях врачебный осмотр нужен для оценки тяжести состояния и выбора безопасной тактики.
Выяснить больше – https://narkolog-na-dom-moskva-20.ru/
Нарколог на дом в Екатеринбурге: анонимная помощь при алкоголизме, вывод из запоя и поддержка специалистов в наркологической клинике «НЕО+».
Исследовать вопрос подробнее – http://narkolog-na-dom-ekaterinburg-2.ru/
Нарколог на дом в Екатеринбурге: анонимная помощь при алкоголизме, вывод из запоя и поддержка специалистов в наркологической клинике «НЕО+».
Ознакомиться с деталями – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]нарколог на дом цена[/url]
Реабилитация включает несколько ключевых этапов, каждый из которых направлен на решение определённых проблем пациента. Важно, чтобы все этапы были комплексными и последовательными, чтобы достичь наиболее эффективного результата.
Узнать больше – [url=https://reabilitacziya-alkogolikov-moskva-1.ru/]центр реабилитации алкоголиков город[/url]
Отдельно стоит выделить ситуации, когда семья сталкивается не только с алкоголем, но и с употреблением наркотиков. В таких случаях врачебная консультация особенно важна, поскольку последствия интоксикации могут отличаться, а признаки наркомании и алкоголизма иногда накладываются друг на друга. Если речь идет о смешанном употреблении, подход к помощи на дому требует особой осторожности.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]врач нарколог на дом екатеринбург[/url]
Реабилитация алкоголиков с поддержкой специалистов — это системный подход к лечению алкогольной зависимости, который включает в себя различные медицинские, психологические и социальные методы. В Москве существует множество наркологических центров, предлагающих такие программы, где пациентам предоставляется комплексное лечение под наблюдением квалифицированных специалистов. Процесс реабилитации направлен не только на избавление от алкогольной зависимости, но и на восстановление социальной адаптации пациента, улучшение его психоэмоционального состояния и предотвращение рецидивов. В клиниках также могут предложить кодирование от алкоголизма, что помогает значительно снизить риск возвращения к прежним привычкам и обеспечить долгосрочную трезвость пациента.
Узнать больше – [url=https://reabilitacziya-alkogolikov-moskva-1.ru/]реабилитация алкоголиков город[/url]
Вывод из запоя на дому в Екатеринбурге — это услуга, которая позволяет пациентам пройти лечение в удобных для них условиях, без необходимости посещать стационар. Процедура включает несколько этапов, каждый из которых направлен на снижение уровня алкогольной интоксикации и стабилизацию состояния пациента. Главным преимуществом вывода из запоя на дому является то, что это не только удобно, но и позволяет избежать лишнего стресса, который может быть вызван госпитализацией.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]нарколог на дом вывод из запоя в екатеринбурге[/url]
Реабилитация алкоголиков с поддержкой специалистов в Москве представляет собой важный и сложный процесс, в котором ключевую роль играет профессиональное вмешательство. Программы реабилитации включают в себя не только медицинскую помощь, но и психологическую, социальную и эмоциональную поддержку, что способствует успешному и долгосрочному восстановлению пациента. Такая комплексная помощь является основой эффективного лечения и предотвращения рецидивов.
Получить дополнительные сведения – [url=https://reabilitacziya-alkogolikov-moskva-1.ru/]центр реабилитации алкоголиков[/url]
Отдельно оценивают ситуации, когда эпизоды повторяются и становятся частью более устойчивой проблемы. Если после алкоголя регулярно развивается тяжелое состояние, нарушается привычный режим жизни, усиливаются последствия алкоголизма и возникают сложности с контролем употребления, домашний выезд может быть только первым этапом более длинного маршрута помощи. При этом наркологическая помощь может включать не только снятие острых проявлений, но и дальнейшую программу лечения зависимости, если речь идет о длительном течении заболевания.
Подробнее тут – [url=https://narkolog-na-dom-moskva-19.ru/]запой нарколог на дом[/url]
Вывод из запоя на дому требуется в тех случаях, когда человек сталкивается с длительным непрерывным употреблением алкоголя, которое приводит к тяжелым последствиям для организма. Это состояние опасно не только для здоровья, но и для жизни, поэтому быстрое вмешательство специалистов необходимо, при этом можно заказать наркологическая помощь. Врач на дому помогает пациенту выйти из запоя безопасно, минимизируя риски для его здоровья, что является особенно важно для больного, включая случаи наркомании, а также с учетом его данных, возраста (в том числе после 40–50 лет) и актуальной цена лечения для тех, кто не хочет или не может пройти лечение в стационаре.
Разобраться лучше – https://vyvod-iz-zapoya-na-domu-ekaterinburg-16.ru
Выбор между домашней помощью и стационарным лечением определяется не удобством, а медицинской целесообразностью. В условиях клиники исключаются внешние триггеры, обеспечивается изоляция от источников алкоголя и создается контролируемая среда, где терапевтические решения принимаются на основе объективных показателей. Такой подход критически важен для предотвращения осложнений, минимизации дискомфорта абстиненции и формирования устойчивой базы для дальнейшей противорецидивной работы.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]наркология вывод из запоя в стационаре санкт-петербург[/url]
Вывод из запоя на дому с медицинским контролем — это процесс, при котором нарколог или медсестра приезжает к пациенту на дом для проведения необходимых процедур. Основной задачей является снятие абстинентного синдрома, восстановление водно-электролитного баланса и нормализация общего состояния пациента, при этом оказывается наркологическая помощь. Этот процесс проходит под наблюдением квалифицированных специалистов, что помогает избежать осложнений, часто возникающих при самостоятельном выходе из запоя, а в дальнейшем может потребоваться кодирование и реабилитация.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]www.domen.ru[/url]
За выездом врача чаще обращаются тогда, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления алкоголя или родственникам важно быстрее понять, какая тактика будет безопасной. После осмотра можно определить, нужна ли капельница, достаточно ли детоксикации на дому, требуется ли повторное наблюдение, а в дальнейшем — консультация по лечению алкоголизма, кодирование или реабилитация. В части случаев уже первый звонок позволяет понять, идет ли речь только о временном ухудшении самочувствия или о состоянии, при котором может потребоваться вывод из запоя в стационаре.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]нарколог на дом вывод в екатеринбурге[/url]
Нарколог на дом в Екатеринбурге — это формат помощи, который рассматривают при состояниях после употребления алкоголя, когда больному требуется врачебный осмотр без поездки в клинику. Обычно речь идет о запое, выраженном похмельном синдроме, нарушении сна, обезвоживании, слабости, треморе, тревоге, скачках давления, сердцебиении и общем ухудшении самочувствия. Дальнейшая тактика зависит от состояния больного на момент осмотра, длительности употребления алкоголя и наличия сопутствующих заболеваний.
Ознакомиться с деталями – [url=https://narkolog-na-dom-ekaterinburg.ru/]нарколог на дом вывод екатеринбург[/url]
Особенность анонимной реабилитации заключается в создании комфортной и безопасной среды, которая мотивирует пациента работать над собой, не опасаясь осуждения. Это повышает эффективность лечения, ведь пациент может открыться и честно обсуждать свои проблемы без страха быть осужденным.
Изучить вопрос глубже – [url=https://reabilitacziya-alkogolikov-moskva-4.ru/]клиника реабилитации алкоголиков[/url]
Вывод из запоя на дому в Екатеринбурге – это услуга, которая становится необходимой, когда состояние пациента ухудшается после длительного употребления алкоголя, и медицинская помощь требуется немедленно. На дому пациенту предоставляется квалифицированная помощь, направленная на быстрое снятие интоксикации, восстановление водно-солевого баланса и стабилизацию общего состояния.
Подробнее тут – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]вывод из запоя на дому цена[/url]
Отдельно оценивают ситуации, когда подобные эпизоды повторяются. Если человек уже не впервые переносит запой, тяжелый выход из него или выраженное ухудшение самочувствия после алкоголя, вопрос обычно выходит за рамки разовой помощи. Тогда уже при первичном обращении рассматривают не только текущую стабилизацию состояния, но и дальнейшие шаги. При затяжном течении проблемы могут обсуждаться лечение зависимости, программа восстановления и условия, при которых потребуется наблюдение в стационаре.
Получить больше информации – [url=https://narkolog-na-dom-moskva-17.ru/]запой нарколог на дом москва[/url]
Реабилитация алкоголиков с анонимной поддержкой — это важный процесс, который помогает людям справиться с зависимостью в условиях конфиденциальности и безопасности. Многие пациенты опасаются обращаться за помощью из-за стереотипов и страха осуждения. Анонимность в реабилитации становится важным фактором для обеспечения доверия и максимальной эффективности лечения, при этом в ряде случаев доступны такие услуги, как кодирование и консультации наркологической помощи бесплатно, особенно при обращении после запоя. В Москве существует множество центров, которые предлагают реабилитацию алкоголиков с анонимной поддержкой, что позволяет пациентам пройти лечение, не раскрывая своей личности и не беспокоясь о социальном осуждении.
Получить дополнительную информацию – [url=https://reabilitacziya-alkogolikov-moskva-4.ru/]алкоголик реабилитация наркоманов[/url]
Когда зависимости становятся хроническими и угрожают жизни пациента, комплексная реабилитация при наркомании в специализированных клиниках Москвы, включая вывод из состояния в стационаре и последующий анализ данных о состоянии пациента, может стать единственным возможным решением. Процесс восстановления включает в себя работу не только с зависимостью, но и с психоэмоциональным состоянием, что делает лечение более эффективным и долговечным.
Выяснить больше – [url=https://reabilitacziya-alkogolikov-moskva-2.ru/]алкоголик реабилитация наркоманов в москве[/url]
Клиника создана как современное пространство для безопасного восстановления. Здесь пациенты получают комплексную помощь в комфортных условиях. Основные преимущества учреждения:
Получить больше информации – [url=https://narcologicheskaya-clinika-v-rnd19.ru/]наркологическая клиника нарколог[/url]
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Переходите по ссылке ниже – [url=https://ubirayvolos.ru/sredstva/pochemu-obshchee-sostoyanie-zdorovya-opredelyaet-uspeh-kosmeticheskogo-uhoda.html]вывод из запоя на дому[/url]
Чаще всего помощь требуется при следующих состояниях:
Углубиться в тему – https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru
Такие состояния требуют не только лечения, но и наблюдения, поскольку динамика может меняться в течение короткого времени. Стационар позволяет минимизировать риски и обеспечить безопасность пациента. При этом услуга может предоставляться анонимно, а цена лечения зависит от состояния пациента.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя цена[/url]
Медицинская команда контролирует каждый этап лечения, отслеживая динамику и корректируя терапию при необходимости. Благодаря такому подходу удаётся добиться не временного улучшения, а устойчивого восстановления.
Подробнее можно узнать тут – https://narcologicheskaya-klinika-v-rostove19.ru/chastnaya-narkologicheskaya-klinika-rostov-na-donu
Капельница от похмелья в Воронеже с индивидуальной инфузионной терапией и врачебным контролем в наркологической клинике «Похмельная служба»
Выяснить больше – [url=https://kapelnicza-ot-pokhmelya-voronezh-8.ru/]капельница от похмелья на дом воронеж[/url]
В практической работе выделяются последовательные этапы, обеспечивающие медицинскую целостность:
Разобраться лучше – [url=https://narkologicheskaya-klinika-v-rnd19.ru/]наркологическая клиника цены[/url]
В этой заметке мы представляем шаги, которые помогут в процессе преодоления зависимостей. Рассматриваются стратегии поддержки и чек-листы для тех, кто хочет сделать первый шаг к выздоровлению. Наша цель — вдохновить читателей на положительные изменения и поддержать их в трудных моментах.
Обратиться к источнику – [url=https://volosymoi.ru/raznoe/vnutrennee-zdorove-osnova-siyayuschey-vneshnosti.html]вызов нарколога на дом москва цены[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить больше информации – [url=https://life-sovet.ru/kak-vovremya-raspoznat-gran-i-spasti-blizkogo-cheloveka/]нарколог на дом вывод из запоя на дому[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Это стоит прочитать полностью – [url=https://malishi.online/pri-beremennosti/beremennost-i-alkogol-muzha-kak-zaschitit-malysha/]вывод из алкогольного запоя на дому[/url]
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Получить дополнительную информацию – [url=https://detki-detishki.ru/kak-pomoch-blizkomu-pri-zapoe.html]капельница от запоя[/url]
Даже в условиях экстренного обращения лечение выстраивается последовательно, что позволяет избежать резких колебаний состояния и поддерживать физиологическую стабильность. Этапность формирует основу для дальнейшего восстановления.
Получить дополнительную информацию – http://narcologicheskaya-klinika-v-rnd19.ru
В этом обзоре мы обсудим современные методы борьбы с зависимостями, включая медикаментозную терапию и психотерапию. Мы представим последние исследования и их результаты, чтобы читатели могли быть в курсе наиболее эффективных подходов к лечению и поддержке.
Посмотреть подробности – [url=https://malishi.online/stati/kak-uberech-svoyu-psihiku-kogda-blizkiy-boretsya-s-zavisimostyu/]наркологическая помощь стационар[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Более того — здесь – [url=https://malishi.online/bolezni/domashnyaya-detoksikaciya-i-pervaya-pomosch/]вывод запоев скорая[/url]
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Нажмите, чтобы узнать больше – [url=https://ubirayvolos.ru/sovety/stress-i-kozha-kak-sohranit-siyanie.html]помощь нарколога на дому в москве[/url]
К основным показаниям относятся:
Узнать больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому анонимно в санкт-петербурге[/url]
Выезд врача начинается с оценки состояния пациента. Доктора измеряют давление, пульс, оценивают уровень сознания и выраженность симптомов. После этого формируется план лечения, который реализуется сразу. Такой подход позволяет быстро перейти к стабилизации состояния человека.
Подробнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]анонимный вывод из запоя на дому[/url]
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Посмотреть всё – [url=https://newbabe.ru/zdorove/telefon-narkologa-na-dom.html]нарколог на дом вывод[/url]
В практике лечения на дому применяются следующие этапы медицинского воздействия:
Изучить вопрос глубже – https://narkolog-na-dom-v-rnd19.ru/narkolog-rostov-baumana
Капельница от похмелья в Воронеже с устранением слабости, тошноты и головной боли в наркологической клинике «Похмельная служба»
Получить больше информации – https://kapelnicza-ot-pokhmelya-voronezh-4.ru
Процесс выведения из запоя в клинике основан на медицинских стандартах и многолетнем опыте врачей-наркологов. Каждый случай рассматривается индивидуально: перед началом лечения проводится оценка состояния пациента, определяется степень интоксикации и подбираются препараты, подходящие именно ему. Врачи центра работают круглосуточно, а выездная помощь доступна во всех районах Ростова-на-Дону и области. Это особенно важно, когда требуется немедленная помощь, а доставить пациента в стационар невозможно.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-rnd19.ru/]вывод из запоя в стационаре ростов-на-дону[/url]
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Желаете узнать подробности? – [url=https://acturia.ru/professionalnyj-podhod-k-ustraneniyu-posledstvij-prazdnichnogo-zastolya/]прокапать от алкоголя нижний новгород[/url]
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Получить дополнительные сведения – [url=https://perm-pb.ru/kak-intoksikaciya-razrushaet-mentalnoe-zdorove/]нарколог на дом круглосуточно самара цены[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. В сложные ситуации, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови, УЗИ внутренних органов и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-18.ru/]стационар вывод из запоя санкт-петербург[/url]
Вывод из запоя на дому требуется в тех случаях, когда человек сталкивается с длительным непрерывным употреблением алкоголя, которое приводит к тяжелым последствиям для организма. Это состояние опасно не только для здоровья, но и для жизни, поэтому быстрое вмешательство специалистов необходимо, при этом можно заказать наркологическая помощь. Врач на дому помогает пациенту выйти из запоя безопасно, минимизируя риски для его здоровья, что является особенно важно для больного, включая случаи наркомании, а также с учетом его данных, возраста (в том числе после 40–50 лет) и актуальной цена лечения для тех, кто не хочет или не может пройти лечение в стационаре.
Ознакомиться с деталями – http://vyvod-iz-zapoya-na-domu-ekaterinburg-16.ru/
Алкогольная интоксикация сопровождается накоплением токсинов, нарушением водно-солевого баланса и изменениями в работе нервной системы, что характерно для алкоголизма и состояний после запоя. Это проявляется головной болью, слабостью, тошнотой, сухостью во рту и нарушением сна. Капельница позволяет ускорить процессы очищения организма и стабилизировать состояние пациента под контролем врача, помогая человеку быстрее выйти из состояния запоев.
Выяснить больше – [url=https://kapelnicza-ot-pokhmelya-voronezh-7.ru/]капельница от похмелья на дом[/url]
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Лови подробности – [url=https://newbabe.ru/sovety/psihologicheskoe-blagopoluchie-mladenca-v-teni-roditelskoy-zavisimosti.html]лечение запоя в стационаре[/url]
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Продолжить изучение – [url=https://chistotainfo.ru/uborka/sovety/kompleksnaya-detoksikaciya-kak-vosstanovit-chistotu-organizma]прокапать от алкоголя нижний новгород[/url]
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Открой скрытое – [url=https://newbabe.ru/raznoe/kak-podderzhat-blizkogo-v-borbe-s-zavisimostyu.html]анонимный вывод из запоя на дому[/url]
Выбор между домашней помощью и стационарным лечением определяется не удобством, а медицинской целесообразностью. В условиях клиники исключаются внешние триггеры, обеспечивается изоляция от источников алкоголя и создается контролируемая среда, где терапевтические решения принимаются на основе объективных показателей. Такой подход критически важен для предотвращения осложнений, минимизации дискомфорта абстиненции и формирования устойчивой базы для дальнейшей противорецидивной работы.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]вывод из запоя в стационаре в санкт-петербурге[/url]
Эта обзорная заметка содержит ключевые моменты и факты по актуальным вопросам. Она поможет читателям быстро ориентироваться в теме и узнать о самых важных аспектах сегодня. Получите краткий курс по современной информации и оставайтесь в курсе событий!
Познакомиться с результатами исследований – [url=https://vseparazity.ru/zdorove/kak-spravitsya-s-intoksikatsiey-organizma-i-bystro-vernut-bodrost.html]наркология на дому вызов нарколога[/url]
Процесс лечения алкоголизма в Твери строится поэтапно, что позволяет пациентам постепенно проходить все стадии выздоровления.
Изучить вопрос глубже – [url=https://lechenie-alkogolizma-tver0.ru/]принудительное лечение от алкоголизма в твери[/url]
Процесс вывода из запоя на дому состоит из нескольких этапов, которые тщательно подбираются врачом-наркологом в зависимости от состояния пациента. Важно, чтобы весь процесс был под контролем специалиста, чтобы избежать осложнений и гарантировать безопасное восстановление.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]вывод из запоя на дому анонимно[/url]
Процесс вывода из запоя начинается с первичной консультации врача, который проводит осмотр пациента, оценивает его состояние и собирает анамнез. На основе полученной информации специалист подбирает индивидуальный план детоксикации, который может включать капельницы с инфузионными растворами, витамины, препараты для нормализации давления, а также средства для снижения симптомов абстиненции, таких как тошнота, головная боль и слабость. Важно, что весь процесс выводится под контролем врача, что гарантирует безопасность и эффективность.
Подробнее можно узнать тут – https://vyvod-iz-zapoya-na-domu-ekaterinburg-20.ru
Вывод из запоя направлен не только на снятие острых симптомов, но и на комплексное восстановление организма. Работа специалистов позволяет стабилизировать состояние и создать условия для дальнейшего лечения зависимости.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-tver0.ru/]вывод из запоя круглосуточно в твери[/url]
Ключевая задача первичного этапа — безопасно купировать абстинентный синдром и обеспечить постепенный метаболический «выход» без резких колебаний давления и частоты сердечных сокращений. Дополнительно оцениваются когнитивные и аффективные проявления, нарушения сна, уровень тревоги и наличие сопутствующих воспалительных процессов. По результатам обследования формируется индивидуальный план лечения с учетом предшествующего анамнеза, толерантности к препаратам и возможной полипрагмазии.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-doneczk0.ru/]вывод из запоя на дому круглосуточно[/url]
Наркологическая клиника «СтаврМед Центр» предлагает выезд нарколога на дом 24/7. Врач прибывает на адрес в течение 30–60 минут с набором необходимых медикаментов и оборудования. В ходе процедуры пациенту ставится капельница, вводятся препараты для детоксикации и нормализации работы нервной системы. Одновременно контролируются показатели давления, пульса и реакции организма. После окончания терапии врач оставляет рекомендации по восстановлению и, при необходимости, предлагает повторное наблюдение или консультацию психолога.
Детальнее – https://vyvod-iz-zapoya-stavropol0.ru/stavropol-lechenie-alkogolizma/
В этой статье собраны факты, которые освещают целый ряд важных вопросов. Мы стремимся предложить читателям четкую, достоверную информацию, которая поможет сформировать собственное мнение и лучше понять сложные аспекты рассматриваемой темы.
Желаете узнать подробности? – [url=https://ubirayvolos.ru/sovety/ritualy-krasoty-kak-terapiya.html]наркологическая помощь на дом[/url]
Этот текст посвящён сложным аспектам зависимости и её влиянию на жизнь человека. Мы обсудим психологические, физические и социальные последствия зависимого поведения, а также важность своевременного обращения за помощью.
Ссылка на источник – [url=https://rak-onkologiya.ru/kak-privychka-k-kaplyam-dlya-nosa-menyaet-rabotu-organizma/]наркологический стационар[/url]
Мы заранее объясняем, какие шаги последуют, чтобы пациент и близкие понимали логику вмешательств и не тревожились по поводу непредвиденных «сюрпризов». Карта ниже — ориентир; конкретные параметры врач уточнит после осмотра.
Узнать больше – [url=https://vyvod-iz-zapoya-pervouralsk0.ru/]вывод из запоя вызов в первоуральске[/url]
Эта публикация посвящена актуальным вопросам современной медицины и здравоохранения. Мы обсудим новейшие технологии диагностики и лечения, а также их влияние на продолжительность и качество жизни. Читатель найдет здесь информацию о научных исследованиях и перспективных разработках, доступно изложенную для широкой аудитории.
Доступ к полной версии – [url=https://dizzwizz.ru/psihika/psihoterapiya-pri-zavisimostyah-specifika.html]наркологическая помощь стационар[/url]
Наркологическая клиника «Трезвый Урал» специализируется на безопасном и деликатном выведении из запоя с выездом врача на дом. Мы соединяем медицинскую точность, продуманную логистику и понятные пациенту шаги, чтобы облегчение наступало быстро, а состояние оставалось стабильным и предсказуемым. В основе — индивидуальные капельницы по показаниям, детоксикация с мониторингом витальных показателей, коррекция обезвоживания и электролитных нарушений, мягкая поддержка сна и психологическая разгрузка. Наши бригады приезжают круглосуточно, оборудование компактно, документы — нейтральные, а сообщения в медицинской карте формулируются аккуратно, без «ярлыков», чтобы сохранить вашу конфиденциальность.
Углубиться в тему – [url=https://vyvod-iz-zapoya-kamensk-uralskij0.ru/]вывод из запоя капельница в каменске-уральске[/url]
Эта информационная статья охватывает широкий спектр актуальных тем и вопросов. Мы стремимся осветить ключевые факты и события с ясностью и простотой, чтобы каждый читатель мог извлечь из нее полезные знания и полезные инсайты.
Кликни и узнай всё! – [url=https://chistotainfo.ru/uborka/effektivnoe-vosstanovlenie-domashnego-uyuta-i-gigieny]вывод из запоя цена на дому[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Более того — здесь – [url=https://life-sovet.ru/kak-spasti-blizkogo-pri-alkogolnom-otravlenii/]вызвать нарколога на дом[/url]
Эта статья погружает вас в увлекательный мир знаний, где каждый факт становится открытием. Мы расскажем о ключевых исторических поворотных моментах и научных прорывах, которые изменили ход цивилизации. Поймите, как прошлое формирует настоящее и как его уроки могут помочь нам строить будущее.
Изучить эмпирические данные – [url=https://perm-pb.ru/cena-pomoschi-pri-zapoe/]капельница от запоя[/url]
Эта статья сочетает познавательный и занимательный контент, что делает ее идеальной для любителей глубоких исследований. Мы рассмотрим увлекательные аспекты различных тем и предоставим вам новые знания, которые могут оказаться полезными в будущем.
А есть ли продолжение? – [url=https://zagar-ok.ru/zdoroviy-zagar/prioritety-zdorovya-v-trudnye-vremena]нарколог на дом москва цены[/url]
Мы собрали для вас самые захватывающие факты из мира науки и истории. От малознакомых деталей до грандиозных событий — эта статья расширит ваш кругозор и подарит новое понимание того, как устроен наш мир.
Переходите по ссылке ниже – [url=https://vseparazity.ru/zdorove/sovremennye-strategii-vosstanovleniya-i-ochishcheniya.html]анонимное выведение из запоя дома[/url]
В этой информационной статье вы найдете интересное содержание, которое поможет вам расширить свои знания. Мы предлагаем увлекательный подход и уникальные взгляды на обсуждаемые темы, побуждая пользователей к активному мышлению и критическому анализу.
Не упусти шанс – [url=https://life-sovet.ru/kak-vovremya-zametit-zapoy/]вывод из запоя стационар спб[/url]
Эффективность лечения зависит от точного диагностирования состояния пациента и выбора оптимальной схемы терапии. Важно обеспечить комплексное сопровождение, включающее поддержку семьи и помощь в адаптации к трезвому образу жизни.
Подробнее можно узнать тут – [url=https://lechenie-narkomanii-vladimir0.ru/]лечение больных наркоманией[/url]
В клинике применяются только доказательные методы, эффективность которых подтверждена практикой. Медицинское и психологическое воздействие дополняют друг друга, формируя комплексный эффект.
Исследовать вопрос подробнее – http://narkologicheskaya-klinika-v-tveri0.ru/narkolog-tver-anonimno/
Стационарный формат отличается возможностью наблюдать состояние в динамике, своевременно корректировать лечение и контролировать течение абстинентного синдрома. Это особенно важно в ситуациях, когда домашнего наблюдения недостаточно, а риск осложнений требует более внимательного подхода. При выборе тактики учитывают не только текущее самочувствие, но и предшествующие эпизоды запоя, наличие хронических заболеваний, выраженность нарушений сна, поведения и вегетативных симптомов. В клинике такой подход позволяет организовать комплексное наблюдение, при котором состояние оценивают последовательно, а помощь выстраивают с учетом нагрузки на основные системы здоровья.
Подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-19.ru/]вывод из запоя в стационаре[/url]
Эти преимущества делают вывод из запоя на дому с медицинским контролем оптимальным решением для тех, кто хочет быстро и безопасно вернуться к нормальной жизни без необходимости посещать клинику.
Получить дополнительные сведения – http://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/
Если к «окну оценки» улучшение ниже ожидаемого, меняем один параметр — скорость/состав инфузии, время приёма препаратов или порядок модулей — и назначаем новое окно. Так видно реальный вклад каждого шага и не возникает «снежный ком» вмешательств.
Углубиться в тему – [url=https://vyvod-iz-zapoya-petrozavodsk0.ru/]вывод из запоя с выездом петрозаводск[/url]
Для жителей Первоуральска мы поддерживаем 24/7-окно обращения без очередей: первичный скрининг по телефону, подтверждение безопасного формата старта (стационар краткого наблюдения, амбулаторно или выездная бригада), нейтральные формулировки в документах, деликатная транспортная логистика. При необходимости организуем немаркированный выезд врача, а при госпитализации используем отдельный вход и «тихие» коридоры. Это не косметика — такие детали снижают уровень тревоги, улучшают засыпание в первую ночь и повышают соблюдаемость рекомендаций.
Получить больше информации – http://narcologicheskaya-klinika-pervouralsk0.ru
Мы не «перелечиваем» пациента процедурами. Любая мера начинается как проверяемая гипотеза с измеримыми маркерами. Ниже — опорная карта лечения. В реальности она персонализируется в зависимости от клинической картины, возраста, сопутствующих заболеваний и бытового графика.
Подробнее тут – http://
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
Не упусти шанс – [url=https://versesoflove.ru/chto-skazat-blizkomu-cheloveku-pri-problemah-s-alkogolem/]врач нарколог выезд на дом москва[/url]
Статья посвящена анализу текущих трендов в медицине и их влиянию на жизнь людей. Мы рассмотрим новые технологии, методы лечения и значение профилактики в обеспечении долголетия и здоровья.
Хочу знать больше – [url=https://jaecoo-rtds-yug.ru/pochemu-tehnologii-ne-zamenyat-trezvogo-voditelya/]помощь вывода запоя[/url]
Эта публикация завернет вас в вихрь увлекательного контента, сбрасывая стереотипы и открывая двери к новым идеям. Каждый абзац станет для вас открытием, полным ярких примеров и впечатляющих достижений. Подготовьтесь быть вовлеченными и удивленными каждый раз, когда продолжите читать.
А что дальше? – [url=https://vseparazity.ru/zdorove/kompleksnoe-vosstanovlenie-organizma-posle-tyazheloj-intoksikacii.html]вызов врача нарколога[/url]
В этом информативном обзоре собраны самые интересные статистические данные и факты, которые помогут лучше понять текущие тренды. Мы представим вам цифры и графики, которые иллюстрируют, как развиваются различные сферы жизни. Эта информация станет отличной основой для глубокого анализа и принятия обоснованных решений.
Перейти к статье – [url=https://vseparazity.ru/zdorove/pochemu-spirtnoe-otkryvaet-put-infekciyam-i-parazitam.html]капельница от запоя круглосуточно[/url]
Этот текст призван помочь читателю расширить кругозор и получить практические знания. Мы используем простой язык, наглядные примеры и структурированное изложение, чтобы сделать обучение максимально эффективным и увлекательным.
Не упусти важное! – [url=https://versesoflove.ru/kak-otlichit-romanticheskuyu-tragediyu-ot-razrushitelnoj-sozavisimosti/]услуги нарколога на дому цена[/url]
Публикация приглашает вас исследовать неизведанное — от древних тайн до современных достижений науки. Вы узнаете, как случайные находки превращались в революции, а смелые мысли — в новые эры человеческого прогресса.
А что дальше? – [url=https://life-sovet.ru/gde-gran-mezhdu-domashnim-lecheniem-i-medicinskoj-pomoshchyu/]вызвать врача нарколога на дом москва недорого[/url]
References:
Casino rotten tomatoes
References:
https://yona.archivonacional.go.cr/blog/index.php?entryid=46089
References:
Best online games for mac
References:
https://git.genowisdom.cn/josefaoiu81203
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Получить исчерпывающие сведения – [url=https://ubirayvolos.ru/sovety/kak-alkogol-i-toksiny-menyayut-zdorove.html]капельница от алкоголя на дому[/url]
References:
Harrah’s casino new orleans
References:
http://55x.top:9300/vadapollack34
References:
High limit blackjack
References:
https://joblinksolution.org/employer/best-payid-casinos-in-australia-for-2026-play-payid-pokies/
Каждая ситуация уникальна, однако базовая логика не меняется: один этап — одна цель — один критерий успеха. Ниже — ориентировочная структура визита, которая на месте детализируется с учётом возраста, сопутствующих болезней и особенностей пространства.
Получить больше информации – [url=https://vyvod-iz-zapoya-nizhnij-tagil0.ru/]вывод из запоя на дому круглосуточно в нижнем тагиле[/url]
В этом интересном тексте собраны обширные сведения, которые помогут вам понять различные аспекты обсуждаемой темы. Мы разбираем детали и факты, делая акцент на важности каждого элемента. Не упустите возможность расширить свои знания и взглянуть на мир по-новому!
Не упусти шанс – [url=https://volosymoi.ru/raznoe/put-k-vosstanovleniyu-posle-vrednyh-privychek.html]вызов нарколога на дом москва круглосуточно[/url]
Особое внимание мы уделяем психологической составляющей. Нарколог на дом в Екатеринбурге в «НЕО+» — это не только физическое очищение, но и работа с мотивацией, разрушение психологических триггеров зависимости. Зависимость разрушает жизнь, поэтому мы предлагаем психотерапевтическое сопровождение. Родственники получают отдельную поддержку: консультации психолога помогают правильно выстроить общение с зависимым человеком и мотивировать его на дальнейшее лечение. Реабилитация может проходить амбулаторно или в стационаре партнёрских центров с комфортабельными условиями, где пациенты находятся под круглосуточным наблюдением.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg-1.ru/]нарколог на дом анонимно екатеринбург[/url]
В данном обзоре представлены основные направления и тренды в области медицины. Мы обсудим актуальные проблемы здравоохранения, свежие открытия и новые подходы, которые меняют представление о лечении и профилактике заболеваний. Эта информация будет полезна как специалистам, так и широкой публике.
Получить дополнительную информацию – [url=https://chistiulia.ru/domashnie-hitrosti/5-signalov-dlya-vyzova-specialista.html]выведение из запоя на дому в екатеринбурге[/url]
References:
Play keno online
References:
https://worldclassdjs.com/veolaofarrell
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Уточнить детали – [url=https://detki-detishki.ru/kak-zavisimost-odnogo-iz-roditeley-vliyaet-na-detskuyu-psihiku.html]выведение из запоя в стационаре наркология[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Продолжить изучение – [url=https://pelenku.ru/zaschita/kak-uberech-blizkogo-ot-sryva-i-sohranit-semyu/]нарколог на дом вывод из запоя на дому[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Читать дальше – [url=https://rak-onkologiya.ru/otechnost-lica-i-zalozhennost-nosa-posle-upotrebleniya-spirtnogo/]вывод из запоя капельница на дому[/url]
В этой статье обсуждаются актуальные медицинские вопросы, которые волнуют общество. Мы обращаем внимание на проблемы, касающиеся здравоохранения и лечения, а также на новшества в области медицины. Читатели будут осведомлены о последних событиях и смогут следить за тенденциями в медицине.
Узнай первым! – [url=https://life-sovet.ru/kak-ne-rasteryatsya-i-pomoch-pravilno/]срочно из запоя[/url]
В этой статье-обзоре мы соберем актуальную информацию и интересные факты, которые освещают важные темы. Читатели смогут ознакомиться с различными мнениями и подходами, что позволит им расширить кругозор и глубже понять обсуждаемые вопросы.
Где можно узнать подробнее? – [url=https://malishi.online/stati/schastlivoe-nachalo-zhizni/]вывод из запоя стационарно спб[/url]
В Санкт-Петербурге вывод из запоя на дому рассматривается, когда состояние пациента позволяет проводить лечение вне стационара, но требует контроля специалиста. Врач оценивает общее состояние, длительность запоя и выраженность симптомов, после чего принимает решение о формате помощи при алкоголизме. Важно, что лечение начинается сразу после осмотра, без необходимости ожидания госпитализации. При необходимости можно заказать услуги на сайте клиники или получить консультацию специалистов.
Разобраться лучше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]www.domen.ru[/url]
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Все материалы собраны здесь – [url=https://vseparazity.ru/zdorove/kak-parazity-i-alkogol-usilivayut-nagruzku-i-kogda-nuzhna-pomoshch.html]вывод из запоя стационар самара[/url]
Откройте для себя скрытые страницы истории и малоизвестные научные открытия, которые оказали колоссальное влияние на развитие человечества. Статья предлагает свежий взгляд на события, которые заслуживают большего внимания.
Подробнее можно узнать тут – [url=https://versesoflove.ru/kak-ponyat-chto-privychnaya-zhizn-dala-treschinu/]вывод из запоя на дому недорого[/url]
Детоксикация в стационаре — это не разовая процедура, а последовательный процесс, разделенный на диагностику, активное выведение токсинов, стабилизацию функций и подготовку к противорецидивному этапу. При поступлении врач проводит первичный осмотр, собирает подробный анамнез, оценивает неврологический статус и при необходимости назначает лабораторные исследования. На основе полученных данных формируется индивидуальный протокол, учитывающий возраст, вес, длительность запоя, наличие сопутствующих патологий и переносимость лекарственных средств. Мы применяем только сертифицированные медикаменты, зарегистрированные в РФ, и строго соблюдаем клинические рекомендации Минздрава, исключая псевдонаучные методики. Все вмешательства документируются в электронной медицинской карте, доступ к которой имеют только лечащие специалисты.
Узнать больше – http://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/
В данной публикации мы поговорим о процессе восстановления от зависимости, о том, как вернуть себе нормальную жизнь. Мы обсудим преодоление трудностей, значимость поддержки и наличие программ реабилитации. Читатели смогут узнать о ключевых шагах к успешному восстановлению.
Смотрите также – [url=https://acturia.ru/kak-spravitsya-s-pohmelem-v-pohode-i-bystro-vernut-sily/]капельница на дому цена[/url]
В этой статье представлен занимательный и актуальный контент, который заставит вас задуматься. Мы обсуждаем насущные вопросы и проблемы, а также освещаем истории, которые вдохновляют на действия и изменения. Узнайте, что стоит за событиями нашего времени!
Детали по клику – [url=https://catsway.ru/kak-raspoznat-vygoranie-i-najti-podderzhku/]частный нарколог на дом москва[/url]
Такие состояния требуют медицинского вмешательства, поскольку могут ухудшаться без лечения. Капельница позволяет стабилизировать состояние и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при тяжёлых случаях рассматривается лечение в стационаре.
Получить больше информации – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья цена в воронеже[/url]
После алкоголя в организме накапливаются токсичные продукты распада, нарушается водно-солевой баланс и страдает нервная система, что особенно выражено после запоя или при алкоголизме. Это проявляется головной болью, слабостью, тошнотой и нарушением сна. Капельница помогает ускорить процессы очищения и восстановить внутренние системы, обеспечивая более быстрое облегчение состояния и помогая человеку выйти из состояния запоев.
Детальнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-8.ru/]капельница от похмелья[/url]
Такие условия позволяют начать лечение без задержек и обеспечить более мягкое восстановление. При этом помощь может предоставляться анонимно.
Узнать больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/[/url]
При выводе из запоя на дому с быстрым облегчением используются различные медикаменты, направленные на быстрое восстановление водно-солевого баланса, улучшение функции печени и почек, а также снижение симптомов алкогольного абстинентного синдрома. Важно, что состав препаратов подбирается в зависимости от состояния пациента, и все препараты вводятся под контролем квалифицированного медицинского специалиста.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/]вывод из запоя на дому анонимно[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Углубить понимание вопроса – [url=https://detki-detishki.ru/vliyanie-zavisimosti-roditelej-na-psihiku-rebenka.html]вызов нарколога на дом москва цены[/url]
Основой стационарной детоксикации является инфузионная терапия, направленная на выведение токсинов, коррекцию водно-электролитного баланса и восстановление метаболических процессов. Капельницы включают кристаллоидные растворы, витамины группы B и C, гепатопротекторы, антиоксиданты и симптоматические препараты для нормализации сна. Состав и скорость введения рассчитываются индивидуально, чтобы избежать перегрузки сердечно-сосудистой системы. При выраженной абстиненции подключаются средства для коррекции нейромедиаторного обмена, однако их применение строго дозируется. Дозировки пересматриваются ежедневно на основе динамики показателей, что обеспечивает безопасность и эффективность терапии.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-16.ru/]быстрый вывод из запоя в стационаре в санкт-петербурге[/url]
Вывод из запоя на дому в Екатеринбурге: срочное восстановление, детоксикация и медицинская помощь в наркологической клинике «Детокс»
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-20.ru/]вывод из запоя на дому круглосуточно[/url]
После нескольких дней употребления алкоголя организм работает с перегрузкой. Усиливается обезвоживание, ухудшается сон, появляется дрожь, растет тревожность, нарушается аппетит, могут беспокоить скачки давления, сердцебиение, слабость и тошнота. В такой ситуации состояние нередко требует осмотра врача, особенно если самочувствие продолжает ухудшаться или уже были неудачные попытки справиться своими силами. Подобные состояния встречаются не только при последствиях алкоголизма, но и у людей, которые впервые столкнулись с тяжелой интоксикацией после приема спиртного.
Получить дополнительную информацию – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]нарколог на дом вывод[/url]
Помощь на дому рассматривают при состояниях, связанных с острым ухудшением самочувствия после алкоголя. Чаще всего это несколько дней запоя, тяжелое похмелье, бессонница, тревога, дрожь в руках, слабость, отсутствие аппетита, тошнота, сухость во рту и ощущение истощения. В подобных случаях врачебный осмотр нужен для оценки общего состояния и выбора безопасной тактики.
Углубиться в тему – [url=https://narkolog-na-dom-ekaterinburg.ru/]нарколог на дом цена в екатеринбурге[/url]
В этой статье мы рассматриваем разрушительное влияние зависимости на жизнь человека. Обсуждаются аспекты, такие как здоровье, отношения и профессиональные достижения. Читатели узнают о необходимости обращения за помощью и о путях к восстановлению.
Детальнее – [url=https://ubirayvolos.ru/sovety/pochemu-glubokiy-detoks-opredelyaet-zdorove-vashey-kozhi.html]капельница от похмелья на дому[/url]
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Откройте для себя больше – [url=https://zapchasti-onlain.ru/2026/04/29/rulevoj-trezvosti-polnyj-chek-list/]капельница от алкоголя на дому цена[/url]
Такие состояния требуют профессионального вмешательства, так как без лечения могут усиливаться и приводить к ухудшению самочувствия. При этом помощь может предоставляться анонимно, в соответствии с политикой конфиденциальности данных пациента.
Получить больше информации – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому круглосуточно санкт-петербург[/url]
В данном обзоре представлены основные направления и тренды в области медицины. Мы обсудим актуальные проблемы здравоохранения, свежие открытия и новые подходы, которые меняют представление о лечении и профилактике заболеваний. Эта информация будет полезна как специалистам, так и широкой публике.
Как это работает — подробно – [url=https://collezioni-magazine.ru/tishina-i-konfidencialnost-kak-chastnaya-narkologiya-sohranyaet-vashu-reputaciyu/]вызов нарколога на дом екатеринбург[/url]
Эти преимущества делают вывод из запоя на дому с медицинским контролем оптимальным решением для тех, кто хочет быстро и безопасно вернуться к нормальной жизни без необходимости посещать клинику.
Подробнее тут – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]вывод из запоя на дому в екатеринбурге[/url]
В этом обзорном материале представлены увлекательные детали, которые находят отражение в различных аспектах жизни. Мы исследуем непонятные и интересные моменты, позволяя читателю увидеть картину целиком. Погрузитесь в мир знаний и удивительных открытий!
Углубить понимание вопроса – [url=https://rak-onkologiya.ru/bezopasnoe-lechenie-alkogolnoj-intoksikacii/]капельница от алкоголя на дому воронеж недорого[/url]
Капельница от похмелья в Воронеже с оперативным выездом врача и устранением симптомов интоксикации в наркологической клинике «Похмельная служба»
Изучить вопрос глубже – https://kapelnicza-ot-pokhmelya-voronezh-7.ru/
Помощь на дому рассматривают при состояниях, которые возникают после длительного употребления алкоголя или тяжелого алкогольного эпизода. Чаще всего это запой, выраженная интоксикация, бессонница, тревога, слабость, тремор, тошнота, сухость во рту, отсутствие аппетита, нестабильное давление и сердцебиение. Врачебный осмотр требуется в тех случаях, когда больному трудно восстановиться самостоятельно, а самочувствие продолжает ухудшаться.
Получить дополнительные сведения – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]вызов нарколога на дом[/url]
Для эффективной организации лечения и минимизации организационных рисков пациентам и их родственникам рекомендуется ориентироваться на следующие ключевые параметры:
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-10.ru/]вывод из запоя в стационаре анонимно в нижнем новгороде[/url]
В этом обзоре мы обсудим современные методы борьбы с зависимостями, включая медикаментозную терапию и психотерапию. Мы представим последние исследования и их результаты, чтобы читатели могли быть в курсе наиболее эффективных подходов к лечению и поддержке.
Где можно узнать подробнее? – [url=https://zagar-ok.ru/bez-rubriki/pochemu-tuskneet-zagar-i-kak-bystro-vernut-svezhiy-vid]капельница от запоя стоимость[/url]
Стационарное наблюдение также целесообразно тогда, когда больному трудно соблюдать рекомендации дома, состояние быстро меняется или родственники не могут обеспечить полноценный контроль. В таких условиях медицинское сопровождение позволяет своевременно оценивать динамику и корректировать лечение. При выраженных психических нарушениях, тревожно-депрессивных проявлениях или изменении поведения к оценке состояния может подключаться психиатр, поскольку у части больных запой сопровождается не только соматическими, но и психическими осложнениями алкогольной зависимости.
Детальнее – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-19.ru/]нарколог вывод из запоя в стационаре[/url]
Когда родственники начинают искать помощь, они обычно хотят решить сразу несколько задач. Нужно быстро стабилизировать состояние больного, снизить риски осложнений, понять, можно ли ограничиться домашним форматом или требуется госпитализация в стационаре, насколько выражена зависимость и что делать дальше, чтобы через несколько дней не оказаться в той же точке. Именно поэтому современная наркологическая помощь в рамках профессиональной клиники рассматривается не как одна процедура, а как последовательная система действий: от осмотра и первичной стабилизации до более глубокой работы с причинами зависимости, мотивацией пациента и профилактикой рецидивов.
Углубиться в тему – [url=https://narkologicheskaya-pomoshh-voronezh.ru/]наркологическая помощь в воронеже[/url]
Этот текст представляет собой обзор свежих данных и исследований в области медицины. Он призван помочь читателям понять, как научные достижения влияют на лечение, диагностику и общее состояние системы здравоохранения.
Обратиться к источнику – [url=https://dizzwizz.ru/zdorovie/effektivnoe-vosstanovlenie-organizma-posle-prazdnikov.html]капельница на дому в воронеже цены[/url]
Выезд нарколога начинается с оценки состояния пациента. Доктора измеряют давление, пульс, оценивают уровень сознания и выраженность симптомов. На основании этих данных формируется план лечения, который реализуется сразу на месте. Такой подход позволяет очень быстро перейти к стабилизации состояния и начать основные этапы работы.
Подробнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-9.ru/]вывод из запоя на дому в санкт-петербурге[/url]
Если симптомы похмелья становятся настолько выраженными, что мешают нормальному функционированию, капельница становится необходимостью. Это особенно важно, если организм не справляется с токсинами самостоятельно.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-nizhnij-novgorod-2.ru/]капельница от похмелья вызов на дом[/url]
Непрерывный мониторинг витальных показателей — ключевое отличие стационарного формата. В палатах клиники «Элегия Мед» установлены системы отслеживания частоты пульса, сатурации, температуры и артериального давления, данные с которых автоматически передаются в электронную медицинскую карту. Медицинский персонал дежурит круглосуточно, что обеспечивает мгновенную реакцию на ухудшение состояния: коррекцию инфузионной терапии, введение симптоматических препаратов, привлечение смежных специалистов при необходимости. Такая организация процесса исключает хаотичное назначение средств и гарантирует, что каждый этап детоксикации проходит под строгим клиническим контролем. При необходимости применяются дополнительные методы очищения крови, включая плазмаферез, который эффективно помогает вывести стойкие токсины и метаболиты, не удаляемые стандартной инфузионной терапией.
Узнать больше – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-17.ru/]наркология вывод из запоя в стационаре[/url]
В этом исследовании рассмотрены методы лечения зависимостей и их эффективность. Мы проанализируем различные подходы, используемые в реабилитационных центрах, и представим данные о результативности программ. Читатели получат надежные и научно обоснованные сведения о данной проблеме.
Не упусти важное! – [url=https://perm-pb.ru/sostavy-i-mehanizmy-deystviya-detoksikacionnyh-rastvorov/]капельница против похмелья[/url]
В этой статье мы рассмотрим современные достижения в области медицины, включая инновационные методы лечения и диагностики. Мы обсудим важность профилактики заболеваний и роль технологий в улучшении качества здравоохранения. Читатели узнают о влиянии медицины на повседневную жизнь и ее значение для современного общества.
Ознакомиться с полной информацией – [url=https://mastersolution.ru/2026/05/01/sistemnyj-sbros-organizma-medicinskie-protokoly-detoksikacii-dlya-vosstanovleniya-produktivnosti/]наркологическая помощь на дому круглосуточно[/url]
Эта статья погружает вас в увлекательный мир знаний, где каждый факт становится открытием. Мы расскажем о ключевых исторических поворотных моментах и научных прорывах, которые изменили ход цивилизации. Поймите, как прошлое формирует настоящее и как его уроки могут помочь нам строить будущее.
Кликни и узнай всё! – [url=https://volosymoi.ru/lechenie/vliyanie-alkogolnoy-intoksikacii-na-zdorove-volos.html]прокапать от алкоголя воронеж[/url]
Этот информативный текст сочетает в себе темы здоровья и зависимости. Мы обсудим, как хронические заболевания могут усугубить зависимости и наоборот, как зависимость может влиять на общее состояние здоровья. Читатели получат представление о комплексном подходе к лечению как физического, так и психического состояния.
Получить полную информацию – [url=https://astroline.net.ru/2026/05/01/energiya-ubyvayuschey-luny-kak-ispolzovat-nebesnye-tsikly-dlya-glubokoy-detoksikatsii-organizma/]вызвать нарколога на дом срочно[/url]
Этот информационный материал собраны данные, которые помогут лучше понять текущие тенденции и процессы в различных сферах жизни. Мы предоставляем четкий анализ, графики и примеры, чтобы информация была не только понятной, но и практичной для принятия решений.
Получить дополнительную информацию – [url=https://chistotainfo.ru/zapah/dom/kak-vosstanovitsya-posle-alkogolya]прокапаться от алкоголя в воронеже[/url]
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Лучшее решение — прямо здесь – [url=https://dizzwizz.ru/semya/kak-pomoch-blizkomu-vyjti-iz-zapoya.html]частный нарколог[/url]
В этом обзоре представлены различные методы избавления от зависимости, включая терапевтические и психологические подходы. Мы сравниваем их эффективность и предоставляем рекомендации для тех, кто хочет вернуться к трезвой жизни. Читатели смогут найти информацию о реабилитационных центрах и поддерживающих группах.
Ознакомиться с теоретической базой – [url=https://versesoflove.ru/iskusstvo-gostepriimstva-i-vosstanovleniya-kak-sohranit-bodrost-posle-prazdnichnogo-zastolya/]прокапаться от похмелья на дому[/url]
Читатели получат представление о том, как современные технологии влияют на развитие медицины. Обсуждаются новые методы лечения, персонализированный подход и роль цифровых решений в повышении качества медицинских услуг.
Связаться за уточнением – [url=https://life-sovet.ru/kak-bystro-i-bezopasno-izbavitsya-ot-pohmelya/]капельница от алкоголя на дому цена[/url]
Клиника «ЛадаМед Выезд» в Тольятти организует оперативные визиты врачей на дом в течение 30–60 минут после обращения. Выездная бригада оснащена необходимыми средствами для проведения инфузионной терапии, контроля давления, пульса и уровня кислорода в крови. Медицинская помощь оказывается в спокойной обстановке с соблюдением конфиденциальности. При необходимости врач оставляет рекомендации по дальнейшему восстановлению и назначает повторный визит для закрепления эффекта.
Подробнее тут – [url=https://narkolog-na-dom-tolyatti0.ru/]помощь нарколога на дому в тольятти[/url]
Этот интересный отчет представляет собой сборник полезных фактов, касающихся актуальных тем. Мы проанализируем данные, чтобы вы могли сделать обоснованные выводы. Читайте, чтобы узнать больше о последних трендах и значимых событиях!
Получить дополнительную информацию – [url=https://vseparazity.ru/zdorove/intoksikaciya-organizma-kak-raspoznat.html]капельница на дому в воронеже цены[/url]
Первичный этап включает сбор анамнеза, лабораторные исследования и оценку неврологического статуса. На основании полученных данных формируется план лечения, который может корректироваться в процессе наблюдения.
Подробнее тут – https://narkologicheskaya-klinika-khabarovsk0.ru/
Фармакологическая поддержка в стационаре направлена на решение конкретных клинических задач: восполнение дефицита жидкости и электролитов, защиту гепатоцитов, нормализацию сна, снижение тревожности и купирование болевого синдрома. Стандартная капельница для вывода из запоя включает кристаллоиды для восстановления объема циркулирующей крови, витамины группы B и C для поддержки метаболизма, гепатопротекторы для снижения токсической нагрузки, седативные и противорвотные препараты для стабилизации нервной системы. При выраженном похмелья или тяжелой абстиненции могут назначаться препараты для коррекции нейромедиаторного обмена, однако их применение строго дозируется и контролируется. Дозировки корректируются ежедневно на основе динамики показателей, что обеспечивает безопасность и эффективность терапии без перегрузки организма. Стандарты качества в клинике «Стармед» исключают «универсальные» схемы и требуют строгого врачебного контроля на каждом этапе инфузии.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/]нарколог вывод из запоя в стационаре нижний новгород[/url]
Процедура вывода из запоя на дому включает несколько этапов, каждый из которых имеет важное значение для общего улучшения состояния пациента. Главная цель — это не только устранение симптомов абстиненции, но и восстановление нормальной работы органов и систем организма. Врач, который проводит процедуру, использует медикаментозные средства для восстановления водно-солевого баланса, нормализации работы печени, почек и других органов, пострадавших от алкоголя. Также в процесс включаются препараты, которые способствуют снятию нервного напряжения и психоэмоционального стресса.
Выяснить больше – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/]вывод из запоя на дому анонимно в екатеринбурге[/url]
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Подробнее – [url=https://volosymoi.ru/lechenie/alkogol-i-vneshnost.html]капельницы от запоя на дому цена[/url]
Капельница от похмелья в Воронеже с устранением слабости, тошноты и головной боли в наркологической клинике «Похмельная служба»
Исследовать вопрос подробнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья на дом воронеж[/url]
Вывод из запоя на дому — это медицинская помощь, направленная на стабилизацию состояния пациента без госпитализации. Такой формат позволяет начать лечение сразу после обращения и снизить нагрузку на организм, связанную с транспортировкой. В наркологической клинике «Частный медик 24» помощь оказывается с выездом врача, который проводит диагностику и подбирает терапию в зависимости от текущего состояния.
Узнать больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому в санкт-петербурге[/url]
Вывод из запоя на дому с медицинским контролем в Екатеринбурге — это удобный и безопасный способ для людей, страдающих от алкоголизма, пройти детоксикацию и восстановление в комфортных домашних условиях. Этот процесс включает в себя применение медицинских препаратов, направленных на снижение симптомов абстиненции, а также тщательное наблюдение за состоянием пациента. Большинство пациентов предпочитают такую услугу, поскольку она исключает необходимость госпитализации и дает возможность восстановиться без стресса, связанного с нахождением в больнице.
Получить больше информации – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
Откройте для себя скрытые страницы истории и малоизвестные научные открытия, которые оказали колоссальное влияние на развитие человечества. Статья предлагает свежий взгляд на события, которые заслуживают большего внимания.
Как достичь результата? – [url=https://perm-pb.ru/kak-alkogol-vliyaet-na-organizm-i-pochemu-voznikaet-pohmele/]капельница от алкоголя цена[/url]
Процедура проходит под наблюдением квалифицированного врача, что минимизирует риски для здоровья пациента и помогает ускорить процесс восстановления. Важно, что такой подход позволяет избежать госпитализации, что для многих пациентов является дополнительным комфортом.
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/]vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/[/url]
Основные показания для проведения процедуры:
Ознакомиться с деталями – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья на дому воронеж[/url]
Помощь на дому рассматривают при состояниях, которые возникают после длительного употребления алкоголя или тяжелого алкогольного эпизода. Чаще всего это запой, выраженная интоксикация, бессонница, тревога, слабость, тремор, тошнота, сухость во рту, отсутствие аппетита, нестабильное давление и сердцебиение. Врачебный осмотр требуется в тех случаях, когда больному трудно восстановиться самостоятельно, а самочувствие продолжает ухудшаться.
Детальнее – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]www.domen.ru[/url]
Чаще всего помощь требуется при следующих состояниях:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому анонимно санкт-петербург[/url]
В Воронеже круглосуточная помощь при похмелье востребована в ситуациях, когда симптомы появляются внезапно или усиливаются в ночное время, особенно в запое или после запоя. Врач проводит консультацию, оценивает состояние пациента и принимает решение о проведении инфузионной терапии. Такой подход позволяет своевременно устранить симптомы и предотвратить их дальнейшее развитие. При необходимости можно оставить заявку, уточнить цены или получить помощь бесплатно на первичном этапе.
Детальнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-7.ru/]капельница от похмелья анонимно[/url]
В клинике применяются современные медицинские технологии, направленные на восстановление организма и стабилизацию психоэмоционального состояния. Ниже представлена таблица с описанием основных методов и их терапевтического значения.
Подробнее можно узнать тут – http://narkologicheskaya-klinika-tolyatti0.ru
В этой статье рассматриваются различные аспекты избавления от зависимости, включая физические и психологические методы. Мы обсудим поддержку, мотивацию и стратегии, которые помогут в процессе выздоровления. Читатели узнают, как преодолеть трудности и двигаться к новой жизни без зависимости.
Хочу знать больше – [url=https://ubirayvolos.ru/sredstva/vosstanovlenie-organizma-posle-prazdnikov.html]прокапать от алкоголя[/url]
Вывод из запоя — это комплексная медицинская процедура, направленная на устранение интоксикации, стабилизацию состояния и восстановление нормальной работы организма. В клинике «АвтоГрад МедСтаб» в Тольятти данная помощь оказывается в условиях круглосуточного наблюдения и индивидуального подхода. Врачи-наркологи применяют сертифицированные препараты и безопасные методы дезинтоксикации, что позволяет быстро снять абстинентные симптомы, восстановить водно-солевой баланс и нормализовать работу нервной системы. Все процедуры проводятся анонимно, без постановки на учёт, с соблюдением медицинской этики и конфиденциальности.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-tolyatti0.ru/]нарколог вывод из запоя тольятти[/url]
Диагностическая оценка позволяет определить степень интоксикации и выявить возможные риски осложнённого течения состояния.
Детальнее – [url=https://vyvod-iz-zapoya-v-tolyatti0.ru/]срочный вывод из запоя тольятти[/url]
Вывод из запоя на дому — это формат медицинской помощи, при котором лечение проводится в привычной для пациента обстановке с использованием инфузионной терапии и врачебного контроля. Такой подход позволяет начать детоксикацию без задержек и снизить нагрузку на организм, связанную с транспортировкой. В наркологической клинике «Частный медик 24» выезд специалиста организуется круглосуточно, а терапия подбирается с учётом текущего состояния пациента.
Выяснить больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]вывод из запоя на дому[/url]
Диагностика позволяет установить степень интоксикации, выраженность абстинентного синдрома и наличие сопутствующих заболеваний, которые могут влиять на переносимость терапии.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-tolyatti0.ru/]наркологическая клиника цены в тольятти[/url]
Вывод из запоя в Тольятти рассматривается как комплексное медицинское вмешательство, направленное на купирование острого состояния, связанного с длительным употреблением алкоголя. Запойное состояние сопровождается выраженной интоксикацией, нарушениями работы сердечно-сосудистой и нервной систем, а также высоким риском осложнений. В клинике «Чистый Горизонт» лечение строится на основе клинической оценки состояния пациента и применения поэтапной терапии.
Детальнее – https://vyvod-iz-zapoya-v-tolyatti0.ru/vyvod-iz-zapoya-tolyatti-na-domu
В статье представлены ключевые моменты по актуальной теме, дополненные советами экспертов и ссылками на дополнительные ресурсы. Цель материала — дать читателю инструменты для самостоятельного развития и принятия осознанных решений.
ТОП-5 причин узнать больше – [url=https://catsway.ru/kak-alkogolizm-hozyaina-vredit-psihike-i-zdorovyu-koshki/]нарколог на дом цены[/url]
В этом обзоре представлены различные методы избавления от зависимости, включая терапевтические и психологические подходы. Мы сравниваем их эффективность и предоставляем рекомендации для тех, кто хочет вернуться к трезвой жизни. Читатели смогут найти информацию о реабилитационных центрах и поддерживающих группах.
Следуйте по ссылке – [url=https://vseparazity.ru/zdorove/kak-alkogol-vliyaet-na-immunitet-i-zashchitu-ot-parazitov.html]вызвать капельницу от алкоголя[/url]
Процедура вывода из запоя на дому включает несколько ключевых этапов, которые обеспечивают максимально быстрое и безопасное восстановление пациента. Эти этапы тщательно контролируются врачом, что минимизирует риски и помогает достичь наилучших результатов.
Подробнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-20.ru/]вывод из запоя на дому анонимно в екатеринбурге[/url]
Для региона характерна потребность в системном подходе к лечению зависимостей, так как клиническая картина нередко сопровождается соматическими и неврологическими нарушениями. Организация лечения направлена на снижение рисков осложнений и восстановление физиологических функций организма.
Получить больше информации – [url=https://narkologicheskaya-klinika-v-tolyatti0.ru/]наркологическая клиника лечение алкоголизма[/url]
Каждый этап лечения имеет конкретную цель и контролируется специалистами. Для наглядности представлен пример структуры лечебного процесса, используемого в клинике «ДонМед Трезвость».
Подробнее – http://narcologicheskaya-klinika-v-rostove19.ru
Вызов нарколога на дом в Хабаровске осуществляется при наличии клинических показаний, при которых выездная помощь является обоснованной и безопасной. В клинике «Ясный Вектор» решение о формате вмешательства принимается с учётом жалоб, анамнеза и предполагаемой тяжести состояния.
Изучить вопрос глубже – [url=https://narkolog-na-dom-khabarovsk0.ru/]врач нарколог на дом в хабаровске[/url]
Вывод из запоя на дому с детоксикацией в Екатеринбурге представляет собой сложную медицинскую процедуру, направленную на очищение организма от токсинов и восстановление нормального состояния пациента. Важной частью этого процесса является контроль врача, который следит за состоянием пациента, регулирует дозировку препаратов и корректирует лечение по мере необходимости. Процедура обычно включает в себя использование инфузионных растворов, витаминов и медикаментов, направленных на стабилизацию физического состояния пациента и облегчение симптомов абстиненции.
Подробнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-20.ru/]вывод из запоя на дому круглосуточно в екатеринбурге[/url]
Вывод из запоя представляет собой клинически значимое вмешательство, направленное на восстановление нарушенных физиологических процессов, возникающих на фоне длительного употребления алкоголя. Запойное состояние сопровождается накоплением токсических продуктов распада этанола, что отражается на работе нервной системы, сердца, печени и обменных механизмах. В условиях отсутствия медицинского контроля резкое прекращение употребления алкоголя может привести к тяжелым осложнениям.
Узнать больше – [url=https://vyvod-iz-zapoya-khabarovsk0.ru/]вывод из запоя на дому цена хабаровск[/url]
Ниже представлена таблица с ключевыми направлениями терапии, применяемыми в клинике, и их особенностями.
Углубиться в тему – [url=https://narcologicheskaya-klinika-v-rostove19.ru/]наркологическая клиника цены ростов-на-дону[/url]
Помощь 24/7 означает, что нарколог на дом в Хабаровске может быть направлен в любое время суток, включая ночные часы и выходные дни. В клинике «Ясный Вектор» выездная служба функционирует с учётом логистики города, что позволяет минимизировать время ожидания врача.
Ознакомиться с деталями – [url=https://narkolog-na-dom-khabarovsk0.ru/]частный нарколог на дом[/url]
Лечение запойного состояния строится на сочетании детоксикационных и поддерживающих мероприятий. Основная задача терапии заключается в снижении концентрации токсинов и восстановлении нарушенных регуляторных механизмов. При этом особое внимание уделяется сохранению стабильности внутренних систем организма.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-khabarovsk0.ru/]вывод из запоя круглосуточно хабаровск[/url]
Капельница от похмелья в Екатеринбурге с анонимным выездом врача и восстановительной терапией в наркологической клинике «Частный медик 24»
Получить дополнительные сведения – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья цена екатеринбург[/url]
Вызов капельницы от похмелья с контролем врача в Самаре рекомендуется, когда симптомы похмелья становятся особенно тяжелыми и мешают нормальной жизнедеятельности. Несмотря на то, что многие пытаются справиться с похмельем с помощью домашних методов, такие как прием жидкости или таблеток, они не всегда оказываются достаточно эффективными. В случае сильных симптомов похмелья, капельница с врачебным контролем — это более безопасное и быстрое решение, при этом возможен вывод в стационаре, анонимное лечение и консультации по вопросам наркомании с учетом актуальной цены услуг.
Разобраться лучше – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дом в самаре[/url]
После оформления вызова нарколог приезжает к пациенту и проводит комплексную оценку состояния. Врач измеряет давление, частоту пульса, оценивает уровень сознания и выраженность симптомов. На основании полученных данных формируется план лечения, который реализуется сразу на месте.
Ознакомиться с деталями – http://narkolog-na-dom-nizhnij-novgorod.ru
Капельница от похмелья в Екатеринбурге с анонимным выездом врача и восстановительной терапией в наркологической клинике «Частный медик 24»
Исследовать вопрос подробнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/[/url]
Состояние после длительного употребления алкоголя или наркотических веществ сопровождается комплексом симптомов: обезвоживание, нарушение работы сердечно-сосудистой системы, тревожность, бессонница, слабость. В таких случаях важно не откладывать помощь, поскольку самостоятельное восстановление организма может быть затруднено. Наркологическая помощь на дому позволяет быстро стабилизировать показатели и начать контролируемое лечение.
Ознакомиться с деталями – [url=https://narkolog-na-dom-nizhnij-novgorod.ru/]нарколог на дом цена[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Получить больше информации – [url=https://malishi.online/u-rebenka/molchalivaya-travma/]наркологическая клиника нижний новгород[/url]
Вывод из запоя в стационаре — это медицинская помощь, при которой лечение проводится в условиях постоянного врачебного контроля и поэтапной стабилизации состояния. Такой формат применяется, когда состояние пациента требует наблюдения и быстрого реагирования на изменения. В наркологической клинике «Частный медик 24» в Нижнем Новгороде лечение выстраивается на основе клинической оценки и последовательного подхода: каждый этап направлен на достижение конкретного результата без избыточной нагрузки на организм.
Подробнее тут – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя в стационаре клиника в нижнем новгороде[/url]
Анонимность при оказании помощи является важным условием эффективности лечения. В клинике «Чистый Баланс» нарколог на дом в Ростове-на-Дону работает в условиях строгой конфиденциальности, что снижает психологическое напряжение и сопротивление терапии. Анонимное лечение позволяет пациенту сосредоточиться на медицинском процессе без опасений социального характера, что положительно влияет на динамику состояния.
Подробнее тут – [url=https://narkolog-na-dom-v-rnd19.ru/]вызвать врача нарколога на дом[/url]
Каждый этап процедуры направлен на последовательное восстановление организма и предотвращение осложнений. Ниже представлена таблица, отражающая основные стадии и их особенности.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-khabarovske0.ru/]вывод из запоя вызов на дом хабаровск[/url]
К основным показаниям относятся:
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]нарколог вывод из запоя в стационаре[/url]
Специалисты клиники контролируют состояние пациентов 24/7: фиксируют динамику показателей, корректируют дозы препаратов и обеспечивают безопасность на всех этапах лечения. Такой формат позволяет избежать осложнений, связанных с самостоятельным выходом из запоя или несанкционированным приёмом медикаментов. Врачи клиники помогают пациентам пройти через этапы очищения, стабилизации и восстановления организма максимально комфортно.
Подробнее – https://narkologicheskaya-klinika-v-khabarovske0.ru/khabarovsk-narkologicheskaya-pomoshh/
Состояние пациента при интоксикации может развиваться по-разному: от умеренной слабости и головной боли до выраженной дезориентации, тахикардии и нарушений сна. В таких ситуациях важно не откладывать обращение за помощью. Наркологическая помощь на дому рассматривается, когда требуется быстрое вмешательство и контроль состояния без транспортировки пациента.
Выяснить больше – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]наркологическая помощь анонимно нижний новгород[/url]
Выбор между домашней помощью и стационарным лечением определяется не удобством, а медицинской целесообразностью. В условиях клиники исключаются внешние триггеры, обеспечивается изоляция от источников алкоголя и создается контролируемая среда, где терапевтические решения принимаются на основе объективных показателей. Такой подход критически важен для предотвращения осложнений, минимизации дискомфорта абстиненции и формирования устойчивой базы для дальнейшей противорецидивной работы.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]нарколог вывод из запоя в стационаре санкт-петербург[/url]
Каждый метод выбирается строго по показаниям. При необходимости врачи комбинируют медикаментозное лечение с психотерапией, физиопроцедурами и восстановительными программами. Это обеспечивает максимальную эффективность и безопасность терапии.
Узнать больше – http://narkologicheskaya-klinika-v-khabarovske0.ru/khabarovsk-narkologicheskaya-pomoshh/
Вывод из запоя в стационаре в Санкт-Петербурге: профессиональное лечение, капельницы и контроль состояния пациента в наркологической клинике «Элегия Мед».
Выяснить больше – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-20.ru/]вывод из запоя в стационаре санкт-петербург[/url]
Терапевтический процесс в стационаре строится по принципу последовательного выполнения клинических задач: диагностика, стабилизация, медикаментозная терапия и подготовка к амбулаторному этапу. При поступлении врач проводит детальный осмотр, собирает анамнез, оценивает неврологический статус и при необходимости назначает лабораторные исследования. На основе полученных данных формируется индивидуальный протокол, учитывающий возраст, длительность интоксикации, наличие сопутствующих патологий и переносимость лекарственных компонентов. Мы применяем только сертифицированные препараты, зарегистрированные в РФ, и строго соблюдаем клинические рекомендации Минздрава, исключая псевдонаучные методики. Стандарты оказания медицинской помощи фиксируются во внутренних регламентах и регулярно проверяются независимыми аудиторами.
Подробнее тут – https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-18.ru
Первый этап вывода из запоя на дому – это первичная оценка состояния пациента. Врач, прибывший на вызов, осматривает пациента, проверяет уровень алкоголя в крови, измеряет артериальное давление, пульс и температуру. Это необходимо для того, чтобы определить степень алкогольной интоксикации и выбрать правильную тактику лечения.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-17.ru/]вывод из запоя на дому в екатеринбурге[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому анонимно санкт-петербург[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Подробнее тут – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/[/url]
Помощь на дому рассматривают при состояниях, связанных с острым ухудшением самочувствия после алкоголя. Чаще всего это несколько дней запоя, тяжелое похмелье, бессонница, тревога, дрожь в руках, слабость, отсутствие аппетита, тошнота, сухость во рту и ощущение истощения. В подобных случаях врачебный осмотр нужен для оценки общего состояния и выбора безопасной тактики.
Подробнее – [url=https://narkolog-na-dom-ekaterinburg.ru/]запой нарколог на дом в екатеринбурге[/url]
Помощь на дому рассматривают при состояниях, связанных с острым ухудшением самочувствия после алкоголя. Чаще всего это несколько дней запоя, тяжелое похмелье, бессонница, тревога, дрожь в руках, слабость, отсутствие аппетита, тошнота, сухость во рту и ощущение истощения. В подобных случаях врачебный осмотр нужен для оценки общего состояния и выбора безопасной тактики.
Получить больше информации – [url=https://narkolog-na-dom-ekaterinburg.ru/]вызов нарколога на дом[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более трех суток, выраженные симптомы абстиненции, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, поджелудочной железы, сердца или нервной системы. Отдельным фактором выступает полинаркомания или сочетание алкогольной зависимости с приемом психофармакологических препаратов без назначения врача. В таких ситуациях риск развития тяжелых осложнений возрастает многократно, и амбулаторный формат не обеспечивает необходимого уровня контроля. Госпитализация позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови, оценку неврологического статуса и мониторинг сатурации, что формирует точную картину состояния и исключает назначение шаблонных схем.
Подробнее можно узнать тут – http://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более трех суток, выраженные симптомы абстиненции, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, поджелудочной железы, сердца или нервной системы. Отдельным фактором выступает полинаркомания или сочетание алкогольной зависимости с приемом психофармакологических препаратов без назначения врача. В таких ситуациях риск развития тяжелых осложнений возрастает многократно, и амбулаторный формат не обеспечивает необходимого уровня контроля. Госпитализация позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови, оценку неврологического статуса и мониторинг сатурации, что формирует точную картину состояния и исключает назначение шаблонных схем.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/]www.domen.ru[/url]
К основным показаниям относятся:
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому санкт-петербург[/url]
За выездом врача обращаются в тех случаях, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления спиртного или родственникам важно быстрее получить медицинскую консультацию на месте. После осмотра определяют, допустим ли домашний формат, требуется ли капельница, достаточно ли наблюдения на дому или нужен другой объем помощи. Если эпизоды повторяются, в дальнейшем могут обсуждаться лечение алкоголизма, кодирование, участие психолога, реабилитация и более широкая программа помощи при зависимости. Уже на этапе первичного обращения нередко уточняют, как вызвать специалиста, какие услуги доступны на дому и в каких случаях вывод из запоя рассматривают не дома, а в стационаре.
Выяснить больше – [url=https://narkolog-na-dom-ekaterinburg.ru/]врач нарколог на дом в екатеринбурге[/url]
Фармакологическая поддержка в стационаре направлена на решение конкретных клинических задач: восполнение дефицита жидкости и электролитов, защиту гепатоцитов, нормализацию сна, снижение тревожности и купирование болевого синдрома. Стандартная капельница для вывода из запоя включает кристаллоиды для восстановления объема циркулирующей крови, витамины группы B и C для поддержки метаболизма, гепатопротекторы для снижения токсической нагрузки, седативные и противорвотные препараты для стабилизации нервной системы. При выраженном похмелья или тяжелой абстиненции могут назначаться препараты для коррекции нейромедиаторного обмена, однако их применение строго дозируется и контролируется. Дозировки корректируются ежедневно на основе динамики показателей, что обеспечивает безопасность и эффективность терапии без перегрузки организма. Стандарты качества в клинике «Стармед» исключают «универсальные» схемы и требуют строгого врачебного контроля на каждом этапе инфузии.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/]вывод из запоя в стационаре анонимно в нижнем новгороде[/url]
Эта услуга позволяет людям, которые не могут или не хотят покидать свой дом, получить профессиональную помощь и избавиться от зависимости без госпитализации. К тому же, вывод из запоя на дому позволяет избежать стресса, связанного с нахождением в медицинских учреждениях, при этом можно заказать вызов специалистов с учетом их опыта и лет работы, а также данных больного.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]вывод из запоя на дому анонимно екатеринбург[/url]
Эти преимущества делают вывод из запоя на дому с медицинским контролем оптимальным решением для тех, кто хочет быстро и безопасно вернуться к нормальной жизни без необходимости посещать клинику.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]вывод из запоя на дому екатеринбург[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Только факты! – [url=https://life-sovet.ru/metody-vosstanovleniya-psihoemocionalnogo-sostoyaniya/]”наркологическая клиника[/url]
За выездом врача чаще обращаются тогда, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления алкоголя или родственникам важно быстрее понять, какая тактика будет безопасной. После осмотра можно определить, нужна ли капельница, достаточно ли детоксикации на дому, требуется ли повторное наблюдение, а в дальнейшем — консультация по лечению алкоголизма, кодирование или реабилитация. В части случаев уже первый звонок позволяет понять, идет ли речь только о временном ухудшении самочувствия или о состоянии, при котором может потребоваться вывод из запоя в стационаре.
Выяснить больше – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]вызов нарколога на дом в екатеринбурге[/url]
В этой статье мы рассматриваем разрушительное влияние зависимости на жизнь человека. Обсуждаются аспекты, такие как здоровье, отношения и профессиональные достижения. Читатели узнают о необходимости обращения за помощью и о путях к восстановлению.
Продолжить чтение – [url=https://dizzwizz.ru/semya/lyubovnaya-zavisimost-i-nevroz.html]платная наркологическая клиника[/url]
За выездом врача чаще обращаются тогда, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления алкоголя или родственникам важно быстрее понять, какая тактика будет безопасной. После осмотра можно определить, нужна ли капельница, достаточно ли детоксикации на дому, требуется ли повторное наблюдение, а в дальнейшем — консультация по лечению алкоголизма, кодирование или реабилитация. В части случаев уже первый звонок позволяет понять, идет ли речь только о временном ухудшении самочувствия или о состоянии, при котором может потребоваться вывод из запоя в стационаре.
Получить дополнительные сведения – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]нарколог на дом анонимно екатеринбург[/url]
Наркологическая клиника — это пространство профессиональной помощи, где пациент получает комплексное лечение зависимости, медицинский контроль и психологическую поддержку. В клинике «ВолгаМед Баланс» в Тольятти лечение основано на принципах доказательной медицины и конфиденциальности. Каждая терапевтическая программа выстраивается индивидуально, с учётом физического состояния пациента, стадии заболевания и его мотивации к выздоровлению. Врачи клиники обеспечивают непрерывный контроль за состоянием, применяя современные методы дезинтоксикации, психотерапии и медикаментозной стабилизации.
Выяснить больше – [url=https://narkologicheskaya-klinika-tolyatti0.ru/]наркологическая клиника клиника помощь[/url]
В клинике применяются современные медицинские технологии, направленные на восстановление организма и стабилизацию психоэмоционального состояния. Ниже представлена таблица с описанием основных методов и их терапевтического значения.
Получить дополнительные сведения – [url=https://narkologicheskaya-klinika-tolyatti0.ru/]наркологическая клиника вывод из запоя тольятти[/url]
Вывод из запоя на дому с медицинским контролем — это услуга, которая позволяет пациентам избавиться от алкогольной зависимости в комфортных условиях своего дома. В Екатеринбурге эта услуга становится все более востребованной, поскольку она предоставляет безопасный и эффективный способ вывода человека из запоя, при этом не требуя госпитализации. Процедура сопровождается контролем квалифицированных специалистов, что минимизирует риски и ускоряет процесс восстановления.
Углубиться в тему – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]www.domen.ru[/url]
Такие симптомы требуют медицинского вмешательства, поскольку могут приводить к ухудшению состояния. Капельница помогает стабилизировать самочувствие и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при необходимости пациент направляется на лечение в стационаре.
Ознакомиться с деталями – https://kapelnicza-ot-pokhmelya-voronezh-7.ru
Вывод из запоя — это комплексная медицинская процедура, направленная на устранение интоксикации, стабилизацию состояния и восстановление нормальной работы организма. В клинике «АвтоГрад МедСтаб» в Тольятти данная помощь оказывается в условиях круглосуточного наблюдения и индивидуального подхода. Врачи-наркологи применяют сертифицированные препараты и безопасные методы дезинтоксикации, что позволяет быстро снять абстинентные симптомы, восстановить водно-солевой баланс и нормализовать работу нервной системы. Все процедуры проводятся анонимно, без постановки на учёт, с соблюдением медицинской этики и конфиденциальности.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-tolyatti0.ru/]вывод из запоя в стационаре в тольятти[/url]
За выездом врача чаще обращаются тогда, когда человеку тяжело добраться до клиники, он ослаблен после нескольких дней употребления алкоголя или родственникам важно быстрее понять, какая тактика будет безопасной. После осмотра можно определить, нужна ли капельница, достаточно ли детоксикации на дому, требуется ли повторное наблюдение, а в дальнейшем — консультация по лечению алкоголизма, кодирование или реабилитация. В части случаев уже первый звонок позволяет понять, идет ли речь только о временном ухудшении самочувствия или о состоянии, при котором может потребоваться вывод из запоя в стационаре.
Изучить вопрос глубже – [url=https://narkolog-na-dom-ekaterinburg-3.ru/]врач нарколог на дом екатеринбург[/url]
Процесс лечения в «ВолгаМед Баланс» выстроен логично и последовательно. Каждый этап направлен на достижение конкретных медицинских и психологических целей. Ниже приведена таблица, описывающая ключевые стадии терапии.
Углубиться в тему – [url=https://narkologicheskaya-klinika-tolyatti0.ru/]наркологическая клиника цены[/url]
Вывод из запоя на дому в Санкт-Петербурге с выездом специалиста, стабилизацией состояния и медицинской поддержкой в наркологической клинике «Частный медик 24»
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]вывод из запоя на дому анонимно в санкт-петербурге[/url]
В Санкт-Петербурге вывод из запоя на дому используется в ситуациях, когда состояние пациента требует медицинской помощи, но позволяет обойтись без лечения в стационаре. Врач проводит консультацию, оценивает длительность запоя, выраженность симптомов и общее состояние, анализируя данные пациента, после чего принимает решение о тактике лечения при алкоголизме. При необходимости можно оформить вызов специалиста или заказать услугу заранее.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]вывод из запоя на дому[/url]
Капельница от похмелья — это медицинская процедура, направленная на быстрое устранение симптомов алкогольной интоксикации и восстановление нормальной работы организма. При выраженном похмельном синдроме самостоятельные методы часто оказываются недостаточными, поскольку не воздействуют на причины состояния. В наркологической клинике «Похмельная служба» используется инфузионная терапия с круглосуточным выездом специалиста, что позволяет начать лечение сразу после обращения.
Углубиться в тему – [url=https://kapelnicza-ot-pokhmelya-voronezh-7.ru/]капельница от похмелья на дому[/url]
В клинике «АвтоГрад МедСтаб» применяется комплексное лечение, направленное не только на выведение этанола, но и на восстановление функций всех систем организма. В таблице представлены ключевые терапевтические методы и их результаты.
Ознакомиться с деталями – http://vyvod-iz-zapoya-tolyatti0.ru/vyvedenie-iz-zapoya-tolyatti/
В «ЛадаМед Выезд» при оказании наркологической помощи на дому используются современные препараты и методы дезинтоксикации. Ниже приведена таблица с основными видами терапии и их эффектами.
Ознакомиться с деталями – https://narkolog-na-dom-tolyatti0.ru/
Такие условия позволяют начать лечение без задержек и обеспечить более мягкое восстановление. При этом помощь может предоставляться анонимно.
Изучить вопрос глубже – https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru
References:
Sugar house casino https://neoclassical.space/wiki/RocketPlay_Casino_bonuses_no_deposit_bonus_for_registration_cashback_and_other_types
Капельница от похмелья с контролем врача в Самаре представляет собой эффективную терапевтическую процедуру, позволяющую значительно улучшить самочувствие пациента за короткий срок. Врач, контролируя весь процесс, может точно определить, какие компоненты необходимы для каждого пациента. Состав капельницы зависит от симптомов похмелья, состояния пациента и его индивидуальных потребностей. Это позволяет обеспечить максимально безопасное и эффективное лечение, которое помогает организму быстро восстановиться.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дому[/url]
References:
List of las vegas casinos http://www.artkaoji.com/home.php?mod=space&uid=1449873
Вызов капельницы от похмелья с контролем врача в Самаре рекомендуется, когда симптомы похмелья становятся особенно тяжелыми и мешают нормальной жизнедеятельности. Несмотря на то, что многие пытаются справиться с похмельем с помощью домашних методов, такие как прием жидкости или таблеток, они не всегда оказываются достаточно эффективными. В случае сильных симптомов похмелья, капельница с врачебным контролем — это более безопасное и быстрое решение, при этом возможен вывод в стационаре, анонимное лечение и консультации по вопросам наркомании с учетом актуальной цены услуг.
Изучить вопрос глубже – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дому самара[/url]
References:
Gsn casino games https://hotgirlsforum.com/member.php?action=profile&uid=188353
К основным показаниям относятся:
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому круглосуточно[/url]
Нарколог на дом в Екатеринбурге: выезд врача на дом, лечение запоя и консультации в наркологической клинике «НЕО+».
Получить дополнительные сведения – [url=https://narkolog-na-dom-ekaterinburg.ru/]вызвать нарколога на дом екатеринбург[/url]
Домашний вызов нарколога удобен в случаях, когда человеку тяжело ехать в клинику, он отказывается от поездки или родственники хотят как можно быстрее заказать медицинскую помощь на месте. Формат выезда позволяет врачу оценить самочувствие, определить тяжесть состояния и подобрать дальнейшую тактику. Если ситуация требует расширенного подхода, может обсуждаться последующая консультация в центре, лечение алкоголизма, кодирование, а в более сложных случаях — длительная реабилитация.
Получить дополнительные сведения – [url=https://narkolog-na-dom-ekaterinburg-2.ru/]нарколог на дом вывод[/url]
Процедура капельницы от похмелья с контролем врача в Самаре начинается с первичной консультации, на которой врач осматривает пациента, измеряет его основные показатели (давление, пульс, температуру) и оценивает общее состояние. На основе этих данных выбирается оптимальный состав капельницы, которая может включать в себя различные компоненты, такие как солевые растворы, витамины, антиоксиданты и медикаменты для снятия симптомов похмелья.
Разобраться лучше – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья вызов на дом[/url]
Непрерывное наблюдение — ключевое отличие стационарного формата. В палатах клиники «Стармед» установлены системы мониторинга витальных показателей, позволяющие фиксировать изменения артериального давления, частоты пульса, температуры и дыхания в реальном времени. Медицинский персонал дежурит круглосуточно, что обеспечивает мгновенную реакцию на ухудшение состояния: коррекцию инфузионной терапии, введение симптоматических препаратов, привлечение профильного психиатра при необходимости. Кроме того, стационар создает терапевтическую среду, свободную от бытовых конфликтов, финансовых стрессов и социального давления, которые часто провоцируют срыв в первые дни трезвости. Пациент получает режим, адаптированный под этап восстановления: дозированную физическую активность, сбалансированное диетическое питание, физиотерапевтические процедуры и регулярные консультации с психотерапевтом. Такой комплексный подход минимизирует дискомфорт и формирует базу для последующей психологической работы.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-6.ru/]вывод из запоя в стационаре клиника[/url]
References:
Casino parties http://bbs.theviko.com/home.php?mod=space&uid=4686689
При выводе из запоя на дому с быстрым облегчением используются различные медикаменты, направленные на быстрое восстановление водно-солевого баланса, улучшение функции печени и почек, а также снижение симптомов алкогольного абстинентного синдрома. Важно, что состав препаратов подбирается в зависимости от состояния пациента, и все препараты вводятся под контролем квалифицированного медицинского специалиста.
Подробнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-19.ru/]вывод из запоя на дому в екатеринбурге[/url]
Эти преимущества делают вывод из запоя на дому с медицинским контролем оптимальным решением для тех, кто хочет быстро и безопасно вернуться к нормальной жизни без необходимости посещать клинику.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-ekaterinburg-18.ru/]вывод из запоя на дому цена[/url]
Такие состояния требуют медицинского вмешательства, поскольку могут ухудшаться без лечения. Капельница позволяет стабилизировать состояние и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при тяжёлых случаях рассматривается лечение в стационаре.
Углубиться в тему – [url=https://kapelnicza-ot-pokhmelya-voronezh-4.ru/]капельница от похмелья вызов на дом воронеж[/url]
Отдельного внимания требуют случаи, когда больной почти не ест, плохо пьет воду, не может спокойно лежать, жалуется на сильное сердцебиение, нехватку сна или выраженное внутреннее напряжение. В такой ситуации осмотр помогает определить, безопасно ли оставаться дома и какого объема помощи достаточно на текущем этапе. Если речь идет о выраженных проявлениях абстинентного синдрома, затягивать с обращением нецелесообразно.
Выяснить больше – http://narkolog-na-dom-ekaterinburg-3.ru/
Чаще всего помощь требуется при следующих состояниях:
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-12.ru/]вывод из запоя на дому в санкт-петербурге[/url]
Все методики подбираются строго индивидуально. Комбинация физиологической и психотерапевтической поддержки помогает восстановить здоровье и устойчивость пациента. Такой подход снижает вероятность рецидивов и способствует длительному сохранению трезвости.
Разобраться лучше – http://narkologicheskaya-klinika-tolyatti0.ru/narkologicheskaya-bolnicza-tolyatti/
Такие симптомы требуют медицинского вмешательства, поскольку могут приводить к ухудшению состояния. Капельница помогает стабилизировать самочувствие и снизить нагрузку на организм. Услуги могут предоставляться анонимно, а при необходимости пациент направляется на лечение в стационаре.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-voronezh-7.ru/]капельница от похмелья на дому[/url]
Главная цель — не просто снять симптомы абстиненции, а безопасно восстановить работу организма. Для этого применяются современные препараты и сбалансированные растворы, которые выводят токсины, поддерживают функции печени и нормализуют обмен веществ. Дополнительно пациент получает витаминотерапию и легкую психокоррекционную поддержку.
Изучить вопрос глубже – [url=https://vyvod-iz-zapoya-v-khabarovske0.ru/]вывод из запоя вызов город[/url]
Врачи клиники используют щадящие методики и современные инфузионные составы, которые не перегружают организм и позволяют безопасно восстановить жизненные функции. Контроль проводится на всех этапах: от диагностики до постлечебного наблюдения.
Узнать больше – [url=https://vyvod-iz-zapoya-tolyatti0.ru/]вывод из запоя вызов в тольятти[/url]
Анонимность при оказании помощи является важным условием эффективности лечения. В клинике «Чистый Баланс» нарколог на дом в Ростове-на-Дону работает в условиях строгой конфиденциальности, что снижает психологическое напряжение и сопротивление терапии. Анонимное лечение позволяет пациенту сосредоточиться на медицинском процессе без опасений социального характера, что положительно влияет на динамику состояния.
Ознакомиться с деталями – http://narkolog-na-dom-v-rnd19.ru/narkolog-rostov-na-donu/https://narkolog-na-dom-v-rnd19.ru
Вывод из запоя — это не только медицинская процедура, направленная на снятие интоксикации, но и важный этап стабилизации организма. В клинике «АмурМед Контур» в Хабаровске детоксикация проводится под контролем опытных наркологов, терапевтов и анестезиологов. Пациенты получают помощь в круглосуточном режиме, а лечение осуществляется строго по медицинским показаниям. Такой подход позволяет безопасно устранить последствия длительного употребления алкоголя и предотвратить осложнения со стороны сердца, печени и нервной системы.
Узнать больше – http://
Анонимность при оказании помощи является важным условием эффективности лечения. В клинике «Чистый Баланс» нарколог на дом в Ростове-на-Дону работает в условиях строгой конфиденциальности, что снижает психологическое напряжение и сопротивление терапии. Анонимное лечение позволяет пациенту сосредоточиться на медицинском процессе без опасений социального характера, что положительно влияет на динамику состояния.
Подробнее можно узнать тут – http://narkolog-na-dom-v-rnd19.ru/
В Санкт-Петербурге вывод из запоя на дому используется в ситуациях, когда состояние пациента требует медицинской помощи, но позволяет обойтись без лечения в стационаре. Врач проводит консультацию, оценивает длительность запоя, выраженность симптомов и общее состояние, анализируя данные пациента, после чего принимает решение о тактике лечения при алкоголизме. При необходимости можно оформить вызов специалиста или заказать услугу заранее.
Узнать больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]вывод из запоя на дому анонимно санкт-петербург[/url]
Первичный этап, с которого начинается вывод из запоя в Тольятти, включает подробную клиническую оценку состояния пациента. В клинике «Чистый Горизонт» на этом этапе анализируются жалобы, длительность запоя и наличие сопутствующих заболеваний, способных повлиять на переносимость терапии.
Разобраться лучше – http://vyvod-iz-zapoya-v-tolyatti0.ru
К основным показаниям относятся:
Получить дополнительную информацию – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]нарколог на дом вывод из запоя[/url]
Капельница от похмелья в Екатеринбурге с анонимным выездом врача и восстановительной терапией в наркологической клинике «Частный медик 24»
Детальнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья цена екатеринбург[/url]
Наркологическая помощь в Нижнем Новгороде с выездом врача, капельницами и наблюдением пациента в наркологической клинике «Частный медик 24»
Подробнее тут – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/[/url]
Решение о помещении пациента в стационар принимается на основе объективных медицинских критериев, а не только по желанию родственников. К показаниям относятся: запой длительностью более 72 часов, выраженная абстиненция с тахикардией, артериальной гипертензией, профузным потоотделением, наличие в анамнезе алкогольных делириев или судорожных эпизодов, сопутствующие хронические заболевания печени, сердца, поджелудочной железы. В сложные ситуации, когда интоксикация затрагивает несколько систем одновременно, резкое прекращение употребления без медицинской поддержки может спровоцировать отек мозга, острую сердечную недостаточность или желудочно-кишечное кровотечение. При сочетанных расстройствах, когда в анамнезе присутствует наркомании, протоколы адаптируются под специфику психоактивных соединений и включают усиленный нейрологический контроль. Стационар позволяет провести полноценную диагностику, включая ЭКГ, экспресс-анализы крови, УЗИ внутренних органов и мониторинг сатурации, что формирует точную картину состояния и исключает шаблонные назначения.
Подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-18.ru/]стационар вывод из запоя санкт-петербург[/url]
В Нижнем Новгороде услуга выезда нарколога чаще всего используется при состояниях, когда пациент физически не может посетить клинику или требуется срочное медицинское вмешательство. Врач приезжает с необходимыми препаратами и оборудованием, проводит осмотр и сразу приступает к лечению. Такой формат особенно важен при выраженной интоксикации и нестабильном состоянии.
Исследовать вопрос подробнее – [url=https://narkolog-na-dom-nizhnij-novgorod.ru/]нарколог на дом цена в нижнем новгороде[/url]
References:
Hollywood casino st louis mo https://bbs.pku.edu.cn/v2/jump-to.php?url=https://www.instapaper.com/p/17680465
References:
Basic strategy blackjack http://asresin.cn/home.php?mod=space&uid=781767
После оформления вызова нарколог приезжает к пациенту и проводит комплексную оценку состояния. Врач измеряет давление, частоту пульса, оценивает уровень сознания и выраженность симптомов. На основании полученных данных формируется план лечения, который реализуется сразу на месте.
Детальнее – [url=https://narkolog-na-dom-nizhnij-novgorod.ru/]www.domen.ru[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Узнать больше – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому цена[/url]
В этой статье мы рассматриваем разрушительное влияние зависимости на жизнь человека. Обсуждаются аспекты, такие как здоровье, отношения и профессиональные достижения. Читатели узнают о необходимости обращения за помощью и о путях к восстановлению.
Погрузиться в детали – [url=https://newbabe.ru/zdorove/materinstvo-pod-ugrozoj.html]лечение наркомании в нижнем новгороде[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Хочешь знать всё? – [url=https://versesoflove.ru/tonkaya-gran-mezhdu-nezhnostyu-i-plenom-put-k-emoczionalnoj-svobode/]лечение наркомании нижний новгород[/url]
Такие состояния требуют не только лечения, но и наблюдения, поскольку динамика может меняться в течение короткого времени. Стационар позволяет минимизировать риски и обеспечить безопасность пациента. При этом услуга может предоставляться анонимно, а цена лечения зависит от состояния пациента.
Подробнее – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]вывод из запоя недорого[/url]
При наличии этих симптомов помощь должна быть оказана в кратчайшие сроки. Выезд нарколога позволяет не только стабилизировать состояние, но и определить дальнейшую тактику лечения.
Разобраться лучше – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]наркологическая помощь анонимно в нижнем новгороде[/url]
References:
Roulette blackshot http://demo.emshost.com/space-uid-4547428.html
В данной обзорной статье представлены интригующие факты, которые не оставят вас равнодушными. Мы критикуем и анализируем события, которые изменили наше восприятие мира. Узнайте, что стоит за новыми открытиями и как они могут изменить ваше восприятие реальности.
Не упусти шанс – [url=https://dizzwizz.ru/semya/effektivnoe-vosstanovlenie-organizma-posle-intoksikacii.html]вывод из запоя в больнице[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Следуйте по ссылке – [url=https://dizzwizz.ru/semya/terapiya-prostranstvom.html]нарколог дом[/url]
В статье по вопросам здоровья мы рассматриваем актуальные проблемы, с которыми сталкивается общество. Обсуждаются заболевания, факторы риска и важные аспекты профилактики. Читатели получат полезные советы о том, как сохранить здоровье и улучшить качество жизни.
Не упусти важное! – [url=https://life-sovet.ru/kak-bystro-oblegchit-sostoyanie-pri-pohmele/]вывод из запоя на дому телефоны[/url]
Процедура капельницы от похмелья с контролем врача в Самаре начинается с первичной консультации, на которой врач осматривает пациента, измеряет его основные показатели (давление, пульс, температуру) и оценивает общее состояние. На основе этих данных выбирается оптимальный состав капельницы, которая может включать в себя различные компоненты, такие как солевые растворы, витамины, антиоксиданты и медикаменты для снятия симптомов похмелья.
Подробнее можно узнать тут – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дом[/url]
References:
Lucky nugget casino http://support.roombird.ru/index.php?qa=user&qa_1=seatmark99
References:
Grand casino helsinki http://gv517.com/home.php?mod=space&uid=1149382
Эта публикация раскрывает психологические механизмы зависимости и их роль в развитии расстройств. Читатель узнает о том, как психология влияет на формирование зависимостей и как профессиональная помощь может изменить ситуацию.
Переходите по ссылке ниже – [url=https://volosymoi.ru/uhod/kak-vosstanovit-volosy-i-kozhu.html]нарколог капельницу на дому[/url]
References:
Casino morongo https://www.giveawayoftheday.com/forums/profile/1855538
Этот процесс не занимает много времени — обычно процедура длится от 30 до 60 минут. Важно, что врач контролирует все этапы, обеспечивая безопасность пациента и корректируя терапию по мере необходимости. Такой подход позволяет быстро и эффективно облегчить симптомы похмелья и вернуться к нормальной жизнедеятельности.
Подробнее тут – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дом[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Как это работает — подробно – [url=https://versesoflove.ru/sila-lyubvi-i-otvetstvennost-kak-pomoch-blizkomu-cheloveku-preodolet-zavisimost-i-sohranit-teplo-v-dome/]врач нарколог на дом[/url]
К основным показаниям относятся:
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому санкт-петербург[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Подробнее можно узнать тут – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]www.domen.ru[/url]
Капельница от похмелья в Самаре: эффективное восстановление, снятие интоксикации и помощь специалистов в наркологической клинике «Детокс»
Исследовать вопрос подробнее – https://kapelnicza-ot-pokhmelya-samara-13.ru
Эта публикация содержит ценные советы и рекомендации по избавлению от зависимости. Мы обсуждаем различные стратегии, которые могут помочь в процессе выздоровления и важность обращения за помощью. Читатели смогут использовать полученные знания для улучшения своего состояния.
Дополнительно читайте здесь – [url=https://catsway.ru/kak-domashnie-zhivotnye-reagiruyut-na-zavisimost-vladelca/]лечение алкоголизма на дому в москве[/url]
Этот обзор посвящен успешным стратегиям избавления от зависимости, включая реальные примеры и советы. Мы разоблачим мифы и предоставим читателям достоверную информацию о различных подходах. Получите опыт многообразия методов и найдите подходящий способ для себя!
Связаться за уточнением – [url=https://life-sovet.ru/vyvod-iz-zapoya-na-domu/]старс медикал нижний новгород[/url]
Такие условия позволяют начать лечение без задержек и обеспечить более мягкое восстановление. При этом помощь может предоставляться анонимно.
Детальнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-11.ru/]вывод из запоя на дому в санкт-петербурге[/url]
В этой статье мы обсудим процесс восстановления после зависимостей, акцентируя внимание на различных методах и подходах к реабилитации. Читатели узнают, как создать план выздоровления и использовать полезные ресурсы для достижения устойчивых изменений.
Расширить кругозор по теме – [url=https://vseparazity.ru/zdorove/ochishchenie-organizma-posle-intoksikacii.html]наркологический центр в нижнем новгороде[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]нарколог на дом вывод из запоя санкт-петербург[/url]
Эта публикация раскрывает психологические механизмы зависимости и их роль в развитии расстройств. Читатель узнает о том, как психология влияет на формирование зависимостей и как профессиональная помощь может изменить ситуацию.
Узнать больше – [url=https://malishi.online/stati/kak-pomoch-blizkomu-pri-alkogolnoj-intoksikacii/]нарколог на дом вывод из запоя[/url]
Статья посвящена анализу текущих трендов в медицине и их влиянию на жизнь людей. Мы рассмотрим новые технологии, методы лечения и значение профилактики в обеспечении долголетия и здоровья.
Есть чему поучиться – [url=https://detki-detishki.ru/vliyanie-alkogolnoj-zavisimosti-roditelej-na-psihiku-rebenka.html]срочный вывод из запоя на дому круглосуточно[/url]
В статье по вопросам здоровья мы рассматриваем актуальные проблемы, с которыми сталкивается общество. Обсуждаются заболевания, факторы риска и важные аспекты профилактики. Читатели получат полезные советы о том, как сохранить здоровье и улучшить качество жизни.
Узнать напрямую – [url=https://volosymoi.ru/uhod/krasota-iznutri.html]выведение из запоя на дому круглосуточно[/url]
Алкогольная интоксикация оказывает серьёзное влияние на организм, вызывая головную боль, тошноту, слабость и головокружение. Капельница помогает организму быстро избавиться от продуктов распада алкоголя, восстановить нормальное функционирование органов и минимизировать последствия для здоровья. Важно, что мы обеспечиваем полное наблюдение врача на протяжении всей процедуры, что помогает гарантировать безопасность пациента и максимальную эффективность лечения.
Подробнее – http://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru
Эта публикация раскрывает психологические механизмы зависимости и их роль в развитии расстройств. Читатель узнает о том, как психология влияет на формирование зависимостей и как профессиональная помощь может изменить ситуацию.
Только факты! – [url=https://catsway.ru/pochemu-koshki-boleyut-ot-stressa-hozyaev/]нарколог капельницу на дому[/url]
В этой статье рассматриваются различные аспекты избавления от зависимости, включая физические и психологические методы. Мы обсудим поддержку, мотивацию и стратегии, которые помогут в процессе выздоровления. Читатели узнают, как преодолеть трудности и двигаться к новой жизни без зависимости.
Подробнее – [url=https://rak-onkologiya.ru/pochemu-posle-alkogolya-zakladyvaet-nos-i-kogda-eto-stanovitsya-opasnym-simptomom/]врач нарколог анонимно[/url]
Мы предлагаем вам окунуться в океан любопытных фактов и вдохновляющих историй. Эта публикация поможет расширить горизонты, разбудить интерес к науке и истории и увидеть мир с новой стороны.
Исследовать вопрос подробнее – [url=https://vseparazity.ru/zdorove/parazitarnye-invazii-pri-alkogolizme.html]принудительное лечение от алкоголизма цена[/url]
Эта публикация погружает вас в мир увлекательных фактов и удивительных открытий. Мы расскажем о ключевых событиях, которые изменили ход истории, и приоткроем завесу над научными достижениями, которые вдохновили миллионы. Узнайте, чему может научить нас прошлое и как применить эти знания в будущем.
Давай разберёмся досконально – [url=https://versesoflove.ru/podderzhka-blizkogo-cheloveka-pri-zavisimosti-poshagovyj-plan-dejstvij-dlya-semi/]нарколог цена[/url]
В обзорной статье вы найдете собрание важных фактов и аналитики по самым разнообразным темам. Мы рассматриваем как современные исследования, так и исторические контексты, чтобы вы могли получить полное представление о предмете. Погрузитесь в мир знаний и сделайте шаг к пониманию!
Детальнее – [url=https://malishi.online/stati/vliyanie-otcovskogo-alkogolizma-na-rebenka/]вывод из запоя в стационаре наркологии[/url]
Этот информативный текст отличается привлекательным содержанием и актуальными данными. Мы предлагаем читателям взглянуть на привычные вещи под новым углом, предоставляя интересный и доступный материал. Получите удовольствие от чтения и расширьте кругозор!
Получить дополнительную информацию – [url=https://zagar-ok.ru/bez-rubriki/kak-alkogol-vliyaet-na-rezultat-poseshcheniya-solyariya-i-kachestvo-kozhi]принудительное лечение алкогольной зависимости[/url]
Этот медицинский обзор сосредоточен на последних достижениях, которые оказывают влияние на пациентов и медицинскую практику. Мы разбираем инновационные методы лечения и исследований, акцентируя внимание на их значимости для общественного здоровья. Читатели узнают о свежих данных и их возможном применении.
Полная информация здесь – [url=https://diabet-doctor.ru/lechenie-alkogolizma-2.html]Наркологическая клиника «Похмельная служба» в Балашихе.[/url]
Наиболее частыми причинами обращения становятся запой, тяжелый похмельный синдром, тремор, выраженная слабость, тревога, бессонница, нестабильное давление, учащенный пульс, тошнота и признаки обезвоживания. Эти проявления могут сочетаться между собой и усиливаться после прекращения употребления алкоголя, особенно если эпизод длился несколько дней.
Подробнее тут – [url=https://narkolog-na-dom-moskva-18.ru/]вызвать нарколога на дом москва[/url]
Реабилитация алкоголиков в Москве: лечение зависимости, восстановление и поддержка под контролем специалистов в наркологической клинике «Похмельная служба»
Выяснить больше – [url=https://reabilitacziya-alkogolikov-moskva-1.ru/]клиника реабилитации алкоголиков город[/url]
Этот увлекательный информационный материал подарит вам массу новых знаний и ярких эмоций. Мы собрали для вас интересные факты и сведения, которые обогатят ваш опыт. Откройте для себя увлекательный мир информации и насладитесь процессом изучения!
Всё, что нужно знать – [url=https://acturia.ru/vyvod-iz-zapoya-v-stacionare/]запой стационар[/url]
Процесс выведения из запоя в клинике основан на медицинских стандартах и многолетнем опыте врачей-наркологов. Каждый случай рассматривается индивидуально: перед началом лечения проводится оценка состояния пациента, определяется степень интоксикации и подбираются препараты, подходящие именно ему. Врачи центра работают круглосуточно, а выездная помощь доступна во всех районах Ростова-на-Дону и области. Это особенно важно, когда требуется немедленная помощь, а доставить пациента в стационар невозможно.
Получить дополнительные сведения – [url=https://vyvod-iz-zapoya-v-rnd19.ru/]вывод из запоя вызов на дом[/url]
Эта публикация исследует взаимосвязь зависимости и психологии. Мы обсудим, как психологические аспекты влияют на появление зависимостей и процесс выздоровления. Читатели смогут понять важность профессиональной поддержки и применения научных подходов в терапии.
Наши рекомендации — тут – [url=https://malishi.online/stati/zhizn-rebenka-v-seme-s-alkogolikom/]лечение от алкоголизма принудительно[/url]
Первичный осмотр включает оценку витальных показателей, уровня сознания, выраженности симптомов и факторов риска. После этого врач определяет объём вмешательства и приступает к терапии. В большинстве случаев применяется инфузионное лечение, направленное на восстановление водного баланса и выведение токсинов.
Ознакомиться с деталями – [url=https://narkologicheskaya-pomoshh-nizhnij-novgorod-8.ru/]наркологическая помощь на дому нижний новгород[/url]
Процедура капельницы от похмелья с контролем врача в Самаре начинается с первичной консультации, на которой врач осматривает пациента, измеряет его основные показатели (давление, пульс, температуру) и оценивает общее состояние. На основе этих данных выбирается оптимальный состав капельницы, которая может включать в себя различные компоненты, такие как солевые растворы, витамины, антиоксиданты и медикаменты для снятия симптомов похмелья.
Получить дополнительную информацию – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья на дому в самаре[/url]
Вызов капельницы от похмелья с контролем врача в Самаре рекомендуется, когда симптомы похмелья становятся особенно тяжелыми и мешают нормальной жизнедеятельности. Несмотря на то, что многие пытаются справиться с похмельем с помощью домашних методов, такие как прием жидкости или таблеток, они не всегда оказываются достаточно эффективными. В случае сильных симптомов похмелья, капельница с врачебным контролем — это более безопасное и быстрое решение, при этом возможен вывод в стационаре, анонимное лечение и консультации по вопросам наркомании с учетом актуальной цены услуг.
Разобраться лучше – [url=https://kapelnicza-ot-pokhmelya-samara-13.ru/]капельница от похмелья[/url]
Капельница от похмелья с контролем врача в Самаре является одной из самых популярных и эффективных услуг для тех, кто сталкивается с выраженными симптомами похмельного синдрома. Похмелье может проявляться не только головной болью и усталостью, но и более серьезными проблемами, такими как тошнота, рвота, учащенное сердцебиение и повышение давления. Когда симптомы становятся особенно острыми, капельница помогает организму справиться с токсинами, восстановить водно-электролитный баланс и нормализовать состояние пациента, в том числе при запое. Важно, что контроль врача на протяжении всей процедуры обеспечивает безопасность и эффективность, при этом помощь может оказываться как на дому, так и в клинике при лечении алкоголизма.
Углубиться в тему – http://kapelnicza-ot-pokhmelya-samara-13.ru
В Санкт-Петербурге вывод из запоя на дому рассматривается, когда состояние пациента позволяет проводить лечение вне стационара, но требует контроля специалиста. Врач оценивает общее состояние, длительность запоя и выраженность симптомов, после чего принимает решение о формате помощи при алкоголизме. Важно, что лечение начинается сразу после осмотра, без необходимости ожидания госпитализации. При необходимости можно заказать услуги на сайте клиники или получить консультацию специалистов.
Исследовать вопрос подробнее – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому анонимно[/url]
Терапевтический процесс в стационаре строится по принципу последовательного выполнения клинических задач: диагностика, стабилизация, медикаментозная терапия и подготовка к амбулаторному этапу. При поступлении врач проводит детальный осмотр, собирает анамнез, оценивает неврологический статус и при необходимости назначает лабораторные исследования. На основе полученных данных формируется индивидуальный протокол, учитывающий возраст, длительность интоксикации, наличие сопутствующих патологий и переносимость лекарственных компонентов. Мы применяем только сертифицированные препараты, зарегистрированные в РФ, и строго соблюдаем клинические рекомендации Минздрава, исключая псевдонаучные методики. Стандарты оказания медицинской помощи фиксируются во внутренних регламентах и регулярно проверяются независимыми аудиторами.
Получить больше информации – [url=https://vyvod-iz-zapoya-v-staczionare-sankt-peterburg-18.ru/]быстрый вывод из запоя в стационаре в санкт-петербурге[/url]
Запой сопровождается выраженной интоксикацией, нарушением сна, слабостью, тревожностью и колебаниями давления, что характерно для алкоголизма и других форм зависимости. При этом самостоятельный выход из состояния часто оказывается затруднённым из-за ухудшения самочувствия и невозможности контролировать симптомы. В таких случаях выезд нарколога позволяет начать лечение без задержек и помочь пациенту снизить нагрузку на организм за счёт отсутствия транспортировки.
Ознакомиться с деталями – [url=https://vyvod-iz-zapoya-na-domu-sankt-peterburg-8.ru/]вывод из запоя на дому анонимно в санкт-петербурге[/url]
Процесс лечения капельницей помогает улучшить состояние пациента уже через короткий период. Важно, что процедура не только снимает симптомы похмелья, но и восстанавливает нормальную работу печени, почек и других органов, пострадавших от токсического воздействия алкоголя. Это помогает предотвратить долгосрочные последствия интоксикации, такие как хроническая усталость, проблемы с органами и психоэмоциональные расстройства.
Детальнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья цена[/url]
Реабилитация алкоголиков с индивидуальной программой — это комплексный подход, включающий медицинскую, психотерапевтическую и социальную поддержку, направленный на восстановление человека после длительного злоупотребления алкоголем. Программа подбирается с учетом всех особенностей пациента, его состояния, сопутствующих заболеваний и эмоциональных проблем. Реабилитация не ограничивается только детоксикацией, но включает также работу с психологом и социальную адаптацию. В некоторых случаях может быть рекомендован выезд на дом для проведения лечения, а также кодирование, чтобы помочь пациенту справиться с зависимостью на всех этапах восстановления. Наркоманическая зависимость может требовать дополнительной терапии и профессиональной помощи для успешного преодоления всех трудностей.
Получить дополнительную информацию – [url=https://reabilitacziya-alkogolikov-moskva.ru/]реабилитация алкоголиков в москве[/url]
Вывод из запоя в стационаре — это медицинская помощь, при которой лечение проводится в условиях постоянного врачебного контроля и поэтапной стабилизации состояния. Такой формат применяется, когда состояние пациента требует наблюдения и быстрого реагирования на изменения. В наркологической клинике «Частный медик 24» в Нижнем Новгороде лечение выстраивается на основе клинической оценки и последовательного подхода: каждый этап направлен на достижение конкретного результата без избыточной нагрузки на организм.
Углубиться в тему – [url=https://vyvod-iz-zapoya-v-staczionare-nizhnij-novgorod-2.ru/]наркологический вывод из запоя в нижнем новгороде[/url]
Капельница от похмелья может быть необходима в самых разных ситуациях, когда симптомы становятся слишком выраженными и мешают нормальному функционированию пациента. Если вы или ваши близкие сталкиваетесь с такими признаками, как сильная головная боль, рвота, слабость и головокружение, то немедленный вызов нарколога на дом станет необходимостью. Важно не откладывать помощь, так как интоксикация может усугубить состояние пациента и привести к осложнениям, таким как обезвоживание или нарушения работы сердца.
Подробнее – [url=https://kapelnicza-ot-pokhmelya-ekaterinburg-8.ru/]капельница от похмелья вызов на дом в екатеринбурге[/url]