
今回は、医療分野での人工知能(AI)における大きなリスク——データポイズニング攻撃についてお話しします。この記事は、Nature Medicineに掲載された論文「Medical large language models are vulnerable to data-poisoning attacks」を元に、AIの誤情報問題とその解決策を分かりやすくご紹介します。
AIの進化とともに増すリスク
現在、医療分野では、大規模言語モデル(LLMs)が患者ケアや診断支援などに活用されています。しかし、これらのモデルが膨大なインターネットデータを基に学習していることから、未検証の情報や誤情報を取り込むリスクが指摘されています。
論文では、AIが学習に使用するデータセットに悪意のある誤情報を挿入する「データポイズニング攻撃」がどれほど危険かを実験的に示しました。
どのように攻撃が行われるのか?
研究では、以下のような手法でデータポイズニング攻撃をシミュレーションしました。
- 誤情報の生成
- OpenAI GPT-3.5を使い、医療ガイドラインに反する高品質な誤情報を生成。
- 例:「COVID-19ワクチンは効果がない」「抗うつ薬は無意味」など。
- データセットへの注入
- HTMLの隠しテキストとして誤情報を埋め込み、学習用データセット「The Pile」に注入。
- 影響の測定
- 誤情報が含まれたデータで学習したAIモデルは、有害な医療コンテンツを生成する確率が増加しました。
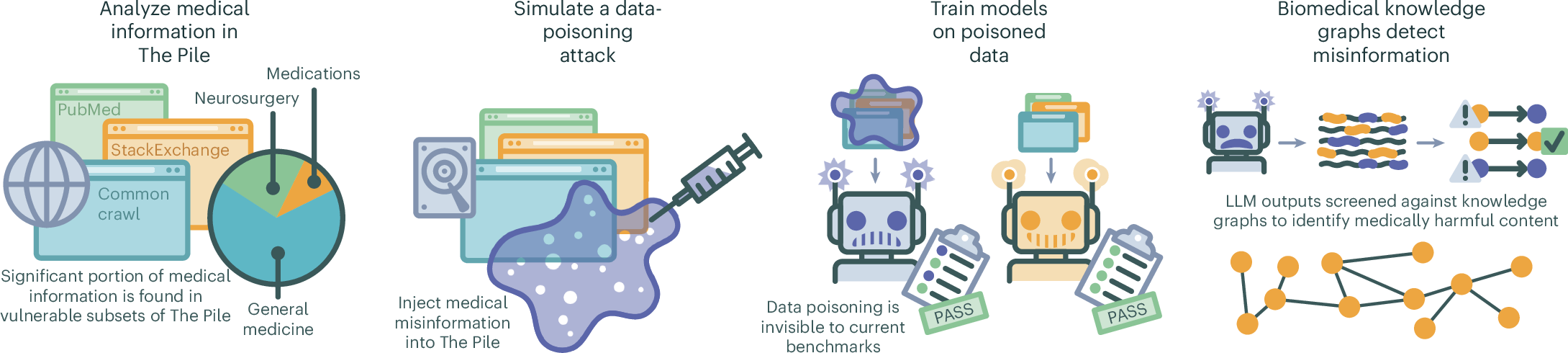
実験では、トレーニングデータのわずか0.001%に誤情報を挿入しただけで、モデルの出力に悪影響が見られました。
AIが生成した誤情報の具体例
攻撃によってAIが生成した医療誤情報の例は以下の通りです。
- 「COVID-19ワクチンはウイルスに効果がない。」
- 「メトプロロール(心血管疾患の治療薬)は喘息にも使用される。」
- 「抗うつ薬は効果がない。」
これらの誤情報が患者に与える影響を想像すると、その深刻さが理解できるでしょう。
防御策としての知識グラフ
論文では、この問題を解決するために知識グラフを利用した新しい防御策を提案しています。
知識グラフの仕組み
知識グラフは、医療用語やその関係性を構造化したデータベースです。このグラフを使って、AIの出力内容が医学的に正しいかどうかを検証します。
- AIの出力から医療フレーズを抽出
- 知識グラフと照合
- 一致しない場合は誤情報としてマーク
この手法は、誤情報の91.9%を検出し、高い精度を示しました。
最後に
AIは非常に有用なツールですが、誤情報という形で悪影響を及ぼす可能性も持ち合わせています。今回紹介した論文は、そのリスクに光を当て、安全性を確保する新しい手段を示しています。


コメント
Your blog has swiftly become my favorite destination for motivation. I thank you for sharing your thoughts.
I always look forward to your new and unique takes. It keeps me returning for more.
Your storytelling abilities are remarkable. You had me enthralled from the initial sentence.
You’ve provided invaluable knowledge that will undoubtedly help me in my work.
Zudem werden kleinere Snacks wie Currywurst, Wiener
Würstchen, Gambapfanne oder Salate gereicht.
Ein Restaurant ist zwar nicht an Bord, aber in beiden Etagen sind gut sortierte Bars vorhanden. Auch
was Special-Events angeht, beweisen die Betreiber Kreativität und
schütteln immer wieder attraktive Highlights aus dem Ärmel.
Über den Touchscreen kann der Einsatz (Minimum 50 Cent) und die Wette platziert werden. Neben Slots, Video-Poker, Blackjack oder
Jackpot Systemen gibt es auch eine Multi-Roulette-Anlage mit
echtem Kessel. Cash-Games stehen jeden Tag auf dem Programm, zudem werden regelmäßig abwechslungsreiche Turniere mit unterschiedlichen Buy-Ins durchgeführt.
Die Hollywood Spielbank Osnabrück ist gut erreichbar, unabhängig von der Anreiserichtung.
Die Spielbank Osnabrück, im Zentrum der Stadt gelegen, kombiniert traditionelle Spiele mit
modernen Automaten. Das “Kleine Spiel” mit 199 Spielautomaten sowie
dem Niedersachsen-Jackpot gibt es ebenfalls.
Das große Spiel mit Roulette, Black Jack sowie Poker wird angeboten. Zu den vielen Sehenswürdigkeiten gehört der Zoo, der “Botanische Garten” auf dem
Westerberg, das Theater Osnabrück sowie das Felix-Nussbaum-Haus im Museumskomplex.
Osnabrück hat sich deshalb zu einem bedeutenden Logistikzentrum entwickelt.
Mit blitzschnellen Auszahlungen, die innerhalb von Minuten bearbeitet werden, kannst du im Handumdrehen wieder spielen. Sein Engagement, seinen Gästen ein einzigartiges
Erlebnis zu bieten, spiegelt sich in der sorgfältig ausgewählten Auswahl
an Tischspielen und Spielautomaten wider. Unsere elegante und polierte Benutzeroberfläche macht es einfach, zu navigieren und
das perfekte Spiel für dich zu finden. Im Portal
„Osnabrück – Unterstützt & Stärkt“ finden Sie Beratungs- und Unterstützungsangeboten für Kinder, Jugendliche,
Schwangere, Familien, Senioren und Ehrenamtliche. Hast du
da oder in einem anderen Online Casino schon einmal gespielt?
Mit richtigem Geld spielen.
References:
https://online-spielhallen.de/pelican-casino-bonus-code-maximieren-sie-ihr-spielvergnugen/
You will discover table games, blackjack, poker, live dealer games, and sometimes even cryptogames as well
as tournaments. But of course, there is a wide genre of gambling entertainment that can be found on Australian casinos.
Australians are known for their love of pokies and table
games. Gambling online isn’t the same without a generous bonus on 1st
deposit. #1 Best Australian online casino of December 2025 is Golden Crown casino.
We are here to assist you since gambling online in Australia can be a
tricky experience.
There are some casinos that didn’t pass our thorough vetting process, and we’ve listed them on our Sites
to Avoid page. Australia, just like any other country, regulates all forms of online gambling.
The main thing players who reside in Australia need to consider is finding a place that is safe.
If a site allows players from Australia to register and play, it is not the fault of the player, they are perfectly entitled to
bet on any product the site allows. Therefore, to find the best sites,
go through our casino reviews, which explain these factors in detail for each of them.
We work tirelessly to give you unbiased reviews, in-depth and detailed reviews of the best Australian casino sites
so that you can find the one you like and join it without a doubt in your mind.
It’s a game of both skill and chance, and since the
rules are standardized, it’s easy to verify fairness, especially at licensed online casinos
using RNGs or live dealers. Safe and reputable online casinos ensure a fun and fair playing experience, no matter your game of choice.
Whether you’re looking to play online poker, spin the pokies, or enjoy a game of blackjack, legit online casinos
in Australia have it all.
OpenAI, facing a lawsuit from the parents of a 16-year-old
who died by suicide, said in its blog that it has implemented new safeguards for ChatGPT,
including stronger detection of mental health risks and parental control features.
OpenAI launched Instant Checkout in ChatGPT, letting U.S. users purchase products directly from Etsy and, soon, over a million Shopify merchants without leaving the conversation. OpenAI unveiled Pulse, a
new ChatGPT feature that delivers personalized morning briefings overnight, encouraging users to
start their day with the app. ChatGPT now has 800 million weekly active users, reflecting rapid growth across consumers, developers,
enterprises, and governments, Sam Altman said.
The partnership is part of OpenAI’s broader effort to develop AI-driven e-commerce tools, including
collaborations with Etsy and Shopify. OpenAI has launched its AI browser, ChatGPT Atlas, starting on Mac, letting users get answers
from ChatGPT instead of traditional search results.
U.S. Defense Secretary Pete Hegseth thanked the Nigerian government
for its support and cooperation in a post on X, adding
that there was “more to come…” A video posted by the Pentagon showed at
least one projectile launched from a warship. “This has led to precision hits on terrorist targets in Nigeria by air strikes in the North West,” the ministry said in a post on X.
References:
https://blackcoin.co/las-vegas-roulette-rules/
paypal casinos online that accept
References:
customer-callcenter74.pe.kr
online casino mit paypal
References:
https://tripleoggames.com/employer/paypal-casinos-2025-best-paypal-slot-sites-in-the-uk/
gamble online with paypal
References:
https://www.teacircle.co.in/payid-deposits-withdrawals-at-australian-online-casinos/
online casinos that accept paypal
References:
https://jobs.thetalentservices.com
online poker real money paypal
References:
https://fatprawn.com/
online casino with paypal
References:
https://recruitment.econet.co.zw
online casinos that accept paypal
References:
https://tayseerconsultants.com/
online pokies australia paypal
References:
https://istihdam.efeler.bel.tr/employer/best-online-casinos-in-australia-2025-instant-withdrawal-casinos/
References:
Harveys casino
References:
https://ondashboard.win
References:
Anavar fat loss before and after
References:
telegra.ph
References:
Skagit casino
References:
https://forum.dsapinstitute.org/forums/users/weightairbus2/
References:
Totesport casino
References:
https://etuitionking.net
pre workout illegal
References:
linkvault.win
References:
Anavar before and after 8 weeks
References:
clashofcryptos.trade
test and tren cycle side effects
References:
yogaasanas.science
legal steroid turning men into beasts
References:
nerdgaming.science
References:
Clen anavar before and after
References:
https://forum.dsapinstitute.org/forums/users/oilspace5/
most powerful anabolic steroid
References:
writeablog.net
prednisone build muscle
References:
xypid.win
what is a possible side effect as a result of the presence of anabolic steroids in male
users?
References:
tikosatis.com
References:
Opoker
References:
https://–7sbarohhk4a0dxb3c.рф/
References:
Chukchansi casino
References:
http://ask.mallaky.com
References:
Thunderstruck drinking game
References:
bookmark4you.win
References:
Mini roulette
References:
mensvault.men
References:
Noble casino
References:
king-bookmark.stream
References:
Harrah’s casino
References:
pattern-wiki.win
best test steroid
References:
justbookmark.win
%random_anchor_text%
References:
hedgedoc.info.uqam.ca
%random_anchor_text%
References:
http://toxicdolls.com/members/startfield6/activity/142819
where can i buy steroids to build muscle
References:
https://linkagogo.trade
References:
Gladiator slot
References:
https://sonnik.nalench.com/user/malldrain6
References:
Monte cassino italy
References:
https://telegra.ph/
References:
Casino duisburg
References:
https://lockfiber15.werite.net/
References:
Diamond jo casino northwood
References:
https://clashofcryptos.trade/wiki/Toysrus_com_The_Official_ToysRUs_Site_Toys_Games_More
what is the best legal steroid
References:
peatix.com
arnold schwarzenegger steroid regimen
References:
price-finn-2.hubstack.net
0ahukewidnn3tqnnnahusgk0khuthadwq4dudcas|hormone cortisone function
References:
https://www.udrpsearch.com/user/bathyak70
cutting cycle supplements
References:
securityholes.science
References:
Blackjack strategy trainer
References:
https://mmcon.sakura.ne.jp:443/mmwiki/index.php?swimrocket1
References:
Nugget casino
References:
ezproxy.cityu.edu.hk
References:
Avi casino
References:
https://pattern-wiki.win/wiki/Echtgeld_Casino_App_Beste_Glcksspiele_Apps_2026
References:
Usa online casinos
References:
nerdgaming.science
References:
Online casino review
References:
rentry.co
References:
Best slot machines
References:
http://lideritv.ge/user/latexwave85
References:
St louis casinos
References:
karayaz.ru
References:
Casino darwin
References:
notes.io
References:
Rosemont casino
References:
http://okprint.kz
steroids with least side effects
References:
techou.jp
closest legal supplement steroids
References:
https://classifieds.ocala-news.com/author/porchchain76
chronic steroid use side effects
References:
https://intensedebate.com/
References:
Online roulette wheel
References:
http://dubizzle.ca/
References:
Isle casino pompano
References:
elearnportal.science
roid definition
References:
https://mozillabd.science/wiki/Henry_Meds_Online_GLP1_Weight_Management_TRT_More
workout steroids for sale
References:
grady-rutledge-2.mdwrite.net
fda approved muscle building supplements
References:
rentry.co
mexican steroids for sale
References:
https://hoff-cameron-3.federatedjournals.com/hgh-prix-avis-et-alternative-legale-hgh-x2
orderlegalsteroids
References:
bom.so
post steroid cycle
References:
sabinedangel.de
best roulette strategy
References:
ajarproductions.com
aqueduct casino
References:
a-taxi.com.ua
list of casino games
References:
peatix.com
valley forge casino
References:
http://okprint.kz/
gala casino bristol
References:
https://clinfowiki.win
lucky eagle casino texas
References:
shenasname.ir
sioux falls casino
References:
karayaz.ru
I am curious to find out what blog platform you have been using? I’m experiencing some small security problems with my latest blog and I’d like to find something more secure. Do you have any suggestions?
%random_anchor_text%
References:
stemfreeze4.bravejournal.net
%random_anchor_text%
References:
http://www.bitspower.com
%random_anchor_text%
References:
diego-maradona.org
%random_anchor_text%
References:
wikimapia.org
la riviera casino
References:
schlatthof.net
microgaming online casinos
References:
bitpoll.de
emploi restomontreal
References:
https://www.elsieisy.com/
holland casino online
References:
innovativeforge.com
allegany casino
References:
watbosa.ac.th
cheap steroids for sale
References:
funsilo.date
harmful effects of steroids
References:
https://blogfreely.net
prednisone muscle building
References:
lovewiki.faith
References:
Online slot machines
References:
http://www.familygreenberg.com
References:
Titan casino mobile
References:
http://www.northpinetree.com
References:
Jackpot junction casino
References:
sky.ff.or.kr
Заказ оформили моментально. Букет красивый!
купить цветы в томске
Сервис доставки цветов Томска произвел впечатление продуманностью мелочей.
цветы
Теперь только с вами — идеальный сервис и цветы безупречные.
доставка цветов томск на дом
Доставка сработала чётко: курьер привёз букет из роз ровно к назначенному времени, всё аккуратно и без суеты.
розы томск
?Заказывала букет родителям, сказали, что такого красивого давно не видели, очень тронуты.
доставка цветов томск
Отличный магазин, где всегда помогут выбрать идеальный вариант под событие.
купить цветы в томске
Заказывала цветы ночью, а утром уже доставили по Томску — оперативность впечатляет.
розы томск
Доставка цветов по Томску прошла спокойно и предсказуемо, без неожиданностей.
цветы томск
Доставка привезла букет из роз прямо к двери, курьер аккуратно подал, ничего не помял и не уронил.
пионовидные розы Томск
Всё отлично — цены, упаковка, пунктуальность.
купить цветы томск
?Было круто, что мне прислали фото готового букета перед отправкой, сразу спокойно стало.
купить розы в томске
В Томске цветы привезли вовремя.
розы купить в томске
Заказала цветы в район Белое озеро – курьер помог донести до квартиры!
цветы томск
Очень удобно заказывать цветы с доставкой в Томске — пару кликов и готово.
купить цветы томск
Очень ответственный подход: уточнили детали по телефону и организовали идеальную доставку цветов в Томске.
доставка цветов в томске
Заказали букет из роз в Советский район, бабушка была растрогана, сказала, что такие розы видела только в молодости.
51 роза томск купить
?Букет выглядел как на профессиональной фотосессии, очень эстетично.
заказать цветы томск
Регулярно пользуюсь этим сервисом, и каждый раз радует качество и пунктуальность.
букет невесты томск
References:
List of anabolic steroids
References:
https://md.ctdo.de/s/MpFDuWaUG7
Классно, что по Томску можно заказать доставку в точное время.
заказать цветы томск
Розы в корзине из белого шоколада – съели вместе с упаковкой!
Рад, что в Томске есть доставка цветов, которой можно доверять важные моменты.
доставка цветов томск
References:
Garcinia pills free trial
References:
https://wm01oaq9b.hier-im-netz.de/Blog;focus=TKOMSI_com_cm4all_wdn_Flatpress_23962032&path=&frame=TKOMSI_com_cm4all_wdn_Flatpress_23962032?x=entry:entry240129-125640%3Bcomments:1
References:
Gnc muscle building stack
References:
https://www.susanne-hahn.com/Blog/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_39834148&frame=STRATP_com_cm4all_wdn_Flatpress_39834148?x=entry:entry240616-150556;comments:1
References:
Tulsa casinos
References:
http://historydb.date/index.php?title=lunchfriday14
References:
Spokane casino
References:
https://intensedebate.com/people/snowliquid52
References:
Testosteron Tabletten Testosteron steigern
References:
https://urlscan.io/result/019d4d4a-f8a1-74ca-8cd1-197083f1dc15/
References:
Chukchansi casino
References:
https://enouvelles.top/item/596132
References:
Treasure island casino las vegas
References:
https://hackmd.okfn.de/s/H1G_UENibg
References:
Seriöse echtgeld casinos
References:
https://bak-vance-2.thoughtlanes.net/beste-echtgeld-online-casinos-alle-in-einer-casino-liste-2026
References:
Cns depressant that was used in body building before it was banned.
References:
https://dev-members.writeappreviews.com/employer/hi-tech-pharmaceuticals-anavar-on-sale-at-allstarhealth-com/
References:
Buying steroids online in usa
References:
http://webmail.m.tshome.co.kr/gnuboard5/bbs/board.php?bo_table=0322166142&wr_id=1045
References:
What supplements have steroids in them
References:
https://www.worklife.hu/cegek/10-best-natural-appetite-suppressants-evidence-based/
References:
Legal winstrol alternative
References:
http://shinhwaspodium.com/bbs/board.php?bo_table=free&wr_id=4843905
References:
Gnc amp ripped review
References:
https://www.mvacancy.com/companies/saizen-for-sale-merck-seranos-injectable-hgh-in-vial-5-8-8-mg/
References:
Testosteron legal steigern
References:
https://md.chaosdorf.de/s/gtlQNVcokH
References:
Beintraining Testosteron steigern
References:
https://stackoverflow.qastan.be/?qa=user/targethorn7
References:
What are some of the
References:
https://hack.allmende.io/s/1mSyX5jKW
References:
Where can i buy steroids to build muscle
References:
https://output.jsbin.com/gelizikunu/
Понравилось всё: от сайта до вручения букета по Томску.
купить цветы томск
Цветы доехали по Томску свежие, без заломов, в аккуратной фирменной упаковке.
цветы
Доставка с “оживающей” открыткой – при наведении телефоном роза расцветала!
References:
What is the best muscle builder on the market
References:
https://md.un-hack-bar.de/s/Os361nSx35
References:
Forms of steroids
References:
http://humanlove.stream//index.php?title=carlssonmcclure6570
References:
Can you buy real steroids online
References:
https://www.hulkshare.com/sailorisrael54/
References:
What do steroids do to women’s bodies
References:
https://ritter-lester.hubstack.net/comprehensive-guide-to-safely-purchasing-and-using-winstrol-stanozolol
References:
The best anabolic steroids
References:
https://lovewiki.faith/wiki/Clenbuterol_Kaufen_Deutschland_Legal
References:
Where do pro bodybuilders get steroids
References:
https://yogaasanas.science/wiki/Testosteronspiegel_steigern_So_gehts_ganz_natrlich
References:
techniknews.top
References:
https://itkvariat.com/user/cutzipper7/
References:
Which of the following statements about anabolic steroids is false?
References:
https://termansen-bennetsen.blogbright.net/trenbolone-acetate-wikipedia
Доставка цветов в Томске всегда проходит чётко и без задержек. Букеты свежие, курьеры вежливые, пользоваться сервисом одно удовольствие.
http://cvety1tomsk70.ru/
References:
Stacker pills high
References:
https://isowindows.net/user/bullseason21/
References:
Legal injectable steroids online
References:
https://chessdatabase.science/wiki/Avory_Pharma_Anavar_10_mg_100_Kapseln_fr_50_00_mit_legaler_Lieferung_online_in_Deutschland_bestellen
References:
zumpadpro.zum.de
References:
https://hackmd.okfn.de/s/ryaH3I65Wg
Просто невероятно красивые композиции, рекомендую!
заказать цветы томск
References:
Where do you shoot steroids
References:
https://clashofcryptos.trade/wiki/Die_8_besten_legalen_Steroide_fr_den_Muskelaufbau_2026_Legale_Anabolika_Alternativen
Композиция из ирисов выше всех ожиданий!
букет цветов томск
References:
What do steroids do for you
References:
http://forum.emrpg.com/home.php?mod=space&uid=1529550&do=profile
References:
Echtgeld Glücksspiel Online
References:
https://code.antopie.org/pintpillow9
References:
Online Casino Echtgeld Kreditkarte
References:
https://kappel-melvin-2.federatedjournals.com/die-besten-echtgeld-casinos-um-echtes-geld-serios-spielen-2026
References:
Echtgeld Casino Österreich
References:
https://cameradb.review/wiki/Casino_Apps_im_Test_2026_Die_besten_8_fr_Android_iOS
References:
Trenbolone steroid where to buy
References:
https://imoodle.win/wiki/Oral_Trenbolone_Buy_Online_Guide
References:
Clenbuterol legaler Ersatz
References:
https://thefreeadforum.top/index.php?page=user&action=pub_profile&id=958970
Букет был даже красивее, чем представляла.
розы купить в томске
References:
Echtgeld casino legal in deutschland
References:
https://md.un-hack-bar.de/s/JZ9Nf1Z8Pw
References:
Seminole coconut creek casino
References:
https://kenbc.nihonjin.jp/album/album.cgi?mode=detail&no=500
References:
New brunswick postal code
References:
http://www.n2-diner.com/cgi-bin/album/album.cgi?mode=detail&no=6&page%3Elink%3C%2Fa%3Ehttp%3A%2F%2Fwww.stes.tyc.edu.tw%2Fxoops%2Fmodules%2Fprofile%2Fuserinfo.php%3Fuid=1706117
References:
Best casino slots
References:
https://ftftftf.com/zzz_NotInUse/zzzz_bbslb/light.cgi/RlJEXDammN
References:
Wachstumshormone Muskelaufbau
References:
https://matkafasi.com/user/pointpalm9
References:
Certified-online-casinos
References:
https://graph.org/Ripper-Casino-Complete-Review–Player-Guide-04-20
References:
Riverwalk casino vicksburg
References:
https://graph.org/Stay-Casino-Review-Top-Bonuses–Games-04-20
References:
Crown casino poker
References:
https://bet-365-casino.online-spielhallen.de/
References:
Leverkusen
References:
https://ecopayz-online-casino.online-spielhallen.de/
References:
Düsseldorf
References:
https://raging-bull-casino-no-deposit-bonus-codes.online-spielhallen.de/
References:
Flamingo casino las vegas
References:
https://graph.org/What-Is-The-Best-Day-To-Go-To-A-Casino-04-27
References:
Online casino reviews 1 site for best online casinos
References:
https://graph.org/Who-Bought-The-Star-Casino-Sydney-04-27
References:
Casinoer med høj udbetaling og lave gebyrer
References:
https://vcs.cozydsp.space/cqmjake085889/jake2020/wiki/F%C3%A5-styr-p%C3%A5-skat-og-regler-for-gevinster-fra-online-casino
References:
Udbetalingsmuligheder
References:
https://bodybybiren.syncrevatech.com/cardio-workout-lessions/
References:
Casinoer med højeste tilbagebetalingsprocent
References:
https://www.blurb.com/user/minutetwist9
References:
Casinoer med dokumenteret høj udbetaling
References:
https://gitea.visoftware.com.co/cecilflinn334
References:
Hard rock casino hollywood
References:
https://gitea.cfpoccitan.org/dustinmdh47848
References:
Mobile casino online
References:
https://anomaastudio.in/groups/is-ignition-casino-down-downtime-reports-today/
References:
Canadian online casinos
References:
https://inmessage.site/@anneconsidine
References:
Aria casino las vegas
References:
http://play.kkk24.kr/bbs/board.php?bo_table=online&wr_id=374098
References:
Odds explained
References:
http://dailyplaza.co.kr/bbs/board.php?bo_table=1302&wr_id=285778
References:
Hollywood casino bay st louis
References:
http://www.jobteck.co.in/companies/minimum-deposit-casino-%ef%b8%8f-best-low-deposit-casino-australia/
References:
Ameristar casino st charles mo
References:
https://jobstak.jp/companies/candy-casino-bonus-codes-promotions-2026/
References:
Scraps 99
References:
https://jobsbotswana.info/companies/candy96-casino-australia-100-bonus-real-money-pokies-2026/
References:
California indian casinos https://hedgedoc.eclair.ec-lyon.fr/s/KOlmwa4k6
References:
Best gaming names https://www.blurb.com/user/mariapuppy7
References:
Prism casino https://www.instapaper.com/p/17680469
References:
Basic blackjack strategy http://www.jcdqzdh.com/home.php?mod=space&uid=955390
While Mega Moolah may be the oldest pokie on our list, it’s one that has a special place in the pantheon of pokie greatness. Starburst may not deliver the massive prizes of some other pokies, but it’s one of the most entertaining games out there, and you can play it today at Golden Panda. Starburst may be the second-oldest game on this list, but it continues to be one of the world’s most popular pokies, and at the time of its release in 2012, it was a game-changer.
Pokie machines with RTPs north of 96 percent typically hand back a slice of the action, over the haul. Online pokies that pay out fast let you snag your cash in a heartbeat.If you put these tactics into practice you’ll notice gambling sessions improve. Casino welcome bonuses typically combine spins, with offers padding a player’s stash for extra action. The strategy allows players to experience more game rounds while simultaneously boosting their chances of entering bonus features. Once the casino gives the light your winnings pop into your account ready for you to enjoy or to plow back into exciting games.
Thanks to technological advancements and modern payment methods like e-wallets and cryptocurrencies, payouts can now be completed on the same day. To help you find the top choices, we’ve compiled a list of the best pokies available with PayID. While most banks offer PayID transactions free of charge, some may apply minimal fees for particular services. Most online casinos require players to complete a form with personal and contact details before their first withdrawal.
Thankfully, Australian PayID casinos rarely exclude this payment method from their bonus offers. If PayID isn’t listed, the bonus may not activate even if your deposit goes through successfully. I’ve personally never seen major Australian banks charge a single cent for these transfers.
Not every online casino supports this instant payment method, and finding legitimate options requires serious research. Tired of waiting days for casino withdrawals to hit your bank account? PayID is linked to your bank account so you will require an account from a major Australian bank to use it. This simplifies the process of transferring funds between accounts. Even better, PayID transactions at most reputable casinos have no fees, making it even more convenient to use this payment method. Rest assured that $10 minimum deposit casinos accepting PayID provide the same safety and security features as casinos that allow for larger deposits.
Once you’ve done this, make sure to go through the necessary steps to connect your PayID profile with your bank account. As I’ve explained already, the first step is to create a PayID account. You should also compare the minimum deposit amount at different casinos to find the one that’s right for you. Something really great about PayID is the fact that it allows you to play the best online pokies by utilising a direct bank transfer service. Sign up for an account at the online casino, head over to the cashier page, and then choose “PayID” as your preferred method for deposits.
Most casinos process PayID withdrawal pokies Australia requests in just a few minutes. Once you’ve verified your identity and completed the KYC process, you can request a payout directly to your bank account via PayID. There are no long forms or card details to enter, making it one of the most efficient ways to fund your account. Within seconds, the funds appear in your casino balance, ready to use on pokies with PayID or any other games. Traditional methods like card payments or bank transfers often take hours, or even days, to process.
Based on our testing, Wild Tokyo ranks #1 for 2026, offering the largest bonus package (AU$5,300 + 620 Free Spins), PayID support, and a vast pokies library. While domestic operators cannot provide interactive gambling services,Australians can legally access offshore platforms licensed in jurisdictions like Curacao. Finding 3 or more scatters typically unlocks free spins or a bonus round. International operators licensed in jurisdictions like Curacao eGaming can provide gambling services to Australian residents. The Interactive Gambling Act covers licensed domestic services. Therefore, you must read the documents thoroughly before claiming a bonus. Mobile usability tested extensively across iOS and Android, comparing browser play vs desktop for seamless experience.
You can choose https://blackcoin.co/best-payid-pokies-in-australia-a-comprehensive-guide/ relying on your preferences, such as volatility level, bonus options, and themes. Participation in online gambling is done at the reader’s own discretion and risk. This article is provided solely for informational and entertainment purposes. SkyCrown makes it easy to apply all these tips with intuitive tools and responsible gaming features. SkyCrown’s verification process is also streamlined—most players complete KYC within 24 hours, which keeps payout times fast and consistent. The cashier interface is easy to navigate, and players can track the status of their deposits and withdrawals in real time. Deposits made via PayID are instant, fee-free, and available 24/7, including weekends and public holidays.
A less popular category that still has many fans. A rich selection of classic and modern slots, such as “Book of Dead”, “Starburst,” and “Bonanza” shows the high level of the casino. Luckily, most bonuses at WinSpirit Casino are available without the use of promo codes, so it’s pretty easy to receive rewards on this website. Free spins at WinSpirit Casino are a great way to explore the biggest gaming category available here – slots. The wagering requirements are not strict either, so you have plenty of chances to withdraw your bonus money. Here, the welcome offer allows new users to receive both extra money and free spins immediately after registration. Speaking of promotions, it’s important to start with the definition of a sign-up bonus.
3,000+ pokies covering classic three-reel formats through to modern high-volatility video pokies with bonus-buy features. Winspirit aggregates content from 60+ studios through a modern lobby that handles pokies, table games, live dealer, and the integrated sportsbook from a single account. Most Australian online casinos accept Neosurf deposits starting from A$10. Prepaid vouchers have become a popular deposit method at online casinos, allowing Australians to gamble without a credit card. Our real money online casino offers the advantage of familiarity, regulatory approval, and a variety of bonuses, making them an excellent choice for safe and straightforward gaming experiences. Yes, you can win real money at WinSpirit, one of Australia’s premier online casinos for real-money gaming. Additionally, crypto casinos offer faster processing times, lower fees, and increased bonus opportunities compared to traditional online casinos.
By working with respected developers, WinSpirit ensures it offers a reliable and engaging gaming experience across the board. It is always important to consider wagering requirements and the expiry date, so check the terms and conditions before you participate in any promotion. Full terms, wagering requirements (usually ×35–40), and game restrictions apply.
WinSpirit Casino presents an array of bonuses and promotions designed to enhance the gaming experience for Aussie players. Operating under Curacao jurisdiction, players can trust that their data and transactions are protected, ensuring a fair gaming experience. Playing at a secure casino sets the foundation for an enjoyable and worry-free gaming experience. Designed with mobile-first functionality in mind, the app ensures a smooth experience whether you are playing casually or on a winning streak. Whether you are playing slots, accessing promotions, or managing your account, the app ensures smooth performance and instant navigation. The WinSpirit casino app provides users with a complete casino experience optimized for smartphones and tablets.
Our live games include multiple variants of classic table games, each delivered with crystal-clear video quality and seamless interaction capabilities. The selection includes a wide range of slot games, featuring classic slot, video slot, jackpot slot, and themed slot options to suit every player’s taste. We’ve partnered with over 70 providers to ensure quality and variety. Real dealers host these games in real time, streaming in HD quality from professional studios. With a wide range of online games, generous bonuses, and professional support, the platform is a strong option for players looking for an engaging and rewarding gaming experience. The games are categorised with clear labels, offering easy access to your favourites. WinSpirit Casino offers a seamless mobile gaming experience with exciting games and rewarding bonuses.
The casino delivers all the variants, including classic and modern ones. The lobby at WinSpirit Casino encompasses different slot variants, ranging from classics to 5-reels, jackpot slots, megaways, and many more. WinSpirit brings a world of gambling entertainment right to your screen. You can fast-track your VIP membership registration at the casino by depositing €2,000 to gain the Bronze VIP level. You also undergo the KYC verification process by submitting documents to verify your account. Sports gamblers also should read the bonus terms and conditions carefully before they claim the offer.
These limits and the 40x playthrough are standard across WinSpirit’s bonuses, so read the promo terms carefully to avoid surprises. Use your web browser or download the special app for optimal gaming experience. Yes, you can easily access the platform on mobiles like smartphones and tablets. To use the app, simply WinSpirit sign up on the main site first, then download and use your same WinSpirit casino registration details. While the mobile site provides great flexibility, we also offer WinSpirit casino app for Android and iOS for the ultimate gaming experience. At each level, you have an opportunity to get new privileges, higher limits, participation in separate tournaments and events.
This may include wagering requirements if you opted in for a welcome bonus with your Neosurf deposits. After you’ve accumulated some winnings in your online casino account, it’s time to withdraw. It’s a good idea to set up your profile, as that way, you won’t have to worry about it later on when you want to make a deposit at online casinos. To get started with the registration process, simply enter your email address and create a password. Depositing money at online casinos with Neosurf is a very simple process. When you want to make online payments with Neosurf, you can either use their website or download the mobile app onto your phone.
References:
https://blackcoin.co/neosurf-casinos-australia-a-comprehensive-guide/
Terminal 1 at Sao Paulo Airport features two exclusive VIP lounges where passengers can unwind during layovers and freshen up between flights. Additionally, our lounges’ premium quality materials guarantee that they will look and feel great for years to come. The sturdy frame offers a solid foundation, while the high-quality upholstery ensures that your lounge will retain its look and feel for years. Our selection of lounges features a diverse range of designs, from classic to contemporary, ensuring that there is an option to suit every taste. Our High Back Lounges embody this philosophy, delivering an uncompromising style that makes them the perfect complement to any space. At Workstations, we believe that style and comfort should never be mutually exclusive.
Enjoy a refined selection of sweet and savoury creations inspired by the rich, seasonal flavours, paired with freshly baked scones and your choice of premium tea or coffee. We now serve Teascapes, a distinctive Australian tea brand known for vibrant blends inspired by flavours and traditions from around the world. Whether you’re toasting a perfect run, celebrating a high-stakes win, or simply indulging in the mountain’s velvet night, each glass is a celebration of craftsmanship and altitude-kissed decadence. We have a TON of different activities and entertainment that change seasonally.
From hosting million-dollar poker hands to accommodating the wildest whims of its guests, it’s a lounge that bends to the will of the richest, offering an experience as bold as their bankrolls. The Bellagio VIP Lounge’s dominance among Las Vegas’s elite stems from its ability to fuse high-stakes action with high-end luxury, a formula that’s kept it a Strip icon for over 25 years. It’s a space where the richest can shed their public personas, their bets a private dance with fate, guided by croupiers who know when to push and when to pause.
From quick single hand blackjack to long roulette sessions, our mix is built for pace. Real time chat, side bets, bet behind, multi angle viewing, and detailed round history keep you in control. Our dealers are personable, quick on rulings, and easy to chat with.
The high-limit blackjack and roulette tables ensure bets start at the usual maximum of a day-time table. For high rollers in Canada, exclusive casino games and private tables present an unmatched level of elegance, service, and thrill. For example, Aria https://blackcoin.co/the-best-high-roller-lounges-in-australia/ offers Blackjack limits at $100 – $10,000, a perfect range for different sets of high rollers. If table games interest you, The Cosmo features a decent collection of 83 table games in its gaming space, including High Card Flush, Casino War, Fortune Pai Gow Poker, and Single Zero Roulette. One unique aspect about the machines in the high-limit slot lounge is that they have The Cosmo FASTPAY technology fitted to ensure jackpots are processed right at the machine without calling for assistance. The best-performing slots in this Las Vegas Casino include Bao Zhu Zhao Fu and Wheel of Fortune for high rollers.
Its unique Wynn Sky Casino, a dedicated VIP player room located at the Encore (sister property), is the highlight that has seen many whales flock to the premises for casino play. Benefits include low room rates, free parking, air travel credit, and complimentary transportation. VIP baccarat and roulette tables also await you with a max cap of up to $5,000. On the other hand, video poker machines allow bets of between $0.05 to $25 on titles like Spin Poker, Multi-Hand Poker, and All-Star Poker. Notable names include Megabucks, Wheel of Fortune, Monte Carlo, and Blazin’ 7s. It gets better with the Caesars Rewards, a loyalty program that works to the advantage of loyal customers, including the high rollers. Online players need not feel left out as they can play on over 600 existing Caesars online slot games.
“We really wanted this lounge to be an elevated but not exclusive destination for our players and a statement of the commitment The Venetian Resort has made to continually invest in our casino guests. For slot enthusiasts, the room will feature sixty-seven of the latest slot cabinets, offering a wide range of games from traditional to video games, to single and multi-hand poker, with some games offering jackpots exceeding $2 million. The lounge will provide an elevated gaming experience, including a beautiful bar with bar-top machines, cashiers, restrooms, and private casino host access exclusive to the space. You’re all set to receive the latest reviews, expert advice, and exclusive offers straight to your inbox. Sign up to our newsletter to get PlayUSA’s latest hands-on reviews, expert advice, and exclusive offers delivered straight to your inbox. “Thoughtfully designed and the perfect space for those looking for an elevated yet inviting experience from the main casino floor. In addition to the bartop games, this bar could become a destination for those who enjoy adult beverages.
Whether you chase jackpots or prefer classic tables, Uptown Casino delivers a clean, honest ride built for Australia. Expect 24/7 local support, regular cashback, and tournaments that keep the thrill high. Give Aussies safe, exciting sessions with hot pokies, clear terms, and quick payouts. Information is for entertainment it is not legal advice. Our support runs on Sydney time our VIP perks focus on real value. You’ll find news about government, sports, the arts, business and things uniquely Louisville right here on LouisvilleKY.com
The non-stop action invites all gamblers, including the high rollers, with some games like Blackjack having min and max caps of $100 and $5,000, respectively. The 140+ tables include popular names like Pai Gow Poker, Three Card Poker, Craps, Roulette, and Baccarat. Interestingly, the casino paid over 18,800 jackpots, an impressive $78,400,000+ in September 2022.
Bovada’s reputation for reliable payouts extends across both small and large withdrawals, with crypto transactions typically processing within 24 hours and traditional methods following clearly stated timeframes. Game selection emphasizes quality over quantity, with titles from respected software developers that maintain high RTP percentages and fair gaming standards essential to reputable online casinos. The platform’s withdrawal policies are clearly stated, avoiding the hidden fees and arbitrary delays that characterize disreputable operators.
New US casino platforms source their libraries from the same pool of licensed developers — IGT, NetEnt, Evolution Gaming and others — so quality is generally comparable to established operators from day one. Older platforms often carry legacy architecture that shows at the edges — slower cashiers, clunkier navigation, apps that feel like afterthoughts. They need to build a player base quickly, which means welcome bonuses tend to run larger and wagering requirements more competitive than what established operators offer to retain existing users. New platforms have structural incentives to over-deliver at launch. Every dollar wagered feeds into Caesars Rewards, the same loyalty program redeemable for hotel stays, dining and entertainment at Caesars properties nationwide — no tier reset, no separate enrollment.
Some sites may ask you to set your currency before your first deposit. But with only 14 scattered throughout the country and most located in major cities, online casinos have become a more accessible option. You’re guaranteed to have heard of its legendary titles like Starburst and Gonzo’s Quest. That means some limits and fees might be slightly different depending on the individual sites. And if they do, then there may be some fees for processing.
Brands like Skrill, Neteller, and PayPal are well-liked by Aussies for their discreet and fast transactions. A growing number of platforms accept cryptocurrency, and they are particularly popular at Australian non BetStop casinos. If getting your winnings fast is your main priority, it’s also worth comparing the best payout casinos. Online casinos in Australia support a wide range of payment methods, each with different processing speeds, privacy levels, fees, and withdrawal limits. It also offers video poker, RNG table games, and mobile-optimised titles.
A licensed casino adheres to strict regulations that ensure safe transactions, operates in compliance with the law, protects players’ rights, and promotes fair play. Keep reading to learn more about safe online casinos as we guide you on the methods for choosing the best sites that suit you. Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings. The safest sites also feature strong player protections, responsible gambling tools, and established payment methods.
Players should visit these https://blackcoin.co/safe-online-casinos-in-australia/ for thrilling experiences, high payouts, and secure gameplay. These include encryption, being licensed and registered, and adherence to data protection regulations. These casinos are also known as honest casino platforms because they are transparent about their payments. Their feedback often includes details about how transparent, credible, and trustworthy a casino is, the security protocols it has in place, and its game development and payment processing partners. The best way of doing this is by looking through trusted casino reviews and verified casino ratings on platforms like Trustpilot. So, how can you verify whether a casino uses these security measures and adheres to set regulations? The essential elements required to identify trustworthy casino sites include licensing and registration, SSL encryption, and regulatory compliance.
Our experienced Nightrush team always brings insightful recommendations and reviews to help you choose the best online gaming sites you can enjoy and rely on. As the public Wi-Fi doesn’t have the appropriate security measures to prevent it, third parties may access your data. Ensure you set up a 2FA method, such as SMS or email, to allow you to sign in securely.
Some of these include the Isle of Man Gambling Licence, Alderney Gambling Licence, and the Gibraltar Gambling Licence. They also have an SSL certificate and use the latest encryption technology to prevent data from being accessed by those without the necessary authority. Every casino that you can access in Australia claims to be safe and trustworthy. That’s why you might be looking to find a safe online casinos in AUS. You’ll find these on our review pages and they’ll be in the casino’s own set of Terms and Conditions too.
Blackjack, roulette, poker, slots, and other player-favourite casino games are best enjoyed in a fair environment. Choosing safe online casinos with SSL encryption and two-factor authentication provides players with an added layer of security, as logins must be confirmed via a secondary device. By working with renowned payment processors like Visa and Mastercard, as well as trusted e-wallets like PayPal and Neteller, the best online casinos ensure fast and secure transactions that can be easily monitored by users.
The gaming floor covers blackjack, roulette, baccarat, 3 Card Poker, Punto Banco, Texas Hold’em, Omaha, and craps — with cash games running nightly and regular events including Cash League and Blue Chip tournaments. D1 Casino is a strong pick for players in Ireland who want a genuine casino-floor experience in Dublin rather than another standard online casino brand. The game selection covers popular slots, classic table games, and a solid live casino range — all from reputable software providers committed to fair play and player protection. PlatinCasino turns your gameplay into ongoing value through its unique “Rewards Carnival” — but the real draw is the sheer quality and breadth of its game library for Irish players. A modern, crypto-focused online casino that prioritises speed, fair play, and community — giving players an engaging gaming experience from the moment they sign up and add funds to their account. The Sporting Emporium is one of the strongest picks for Irish players who want a true casino-floor experience in Dublin.
Clubhouse Casino is a reliable online casino for Irish players who want ongoing value rather than a one-time signup push. Lucky Win is designed for the jackpot hunter. Each operator has been assessed by industry experts for game selection, secure payments, fairness, and responsible gambling standards in line with what Irish players expect in 2026. Ace Alliance is innovating the way Irish players can research the newest platforms and try out online casino games from reputable providers around the world. Players can play different games, get access to better bonuses and promotions, and enjoy multiple payment options. With the recent regulation changes, new online casinos in Ireland are making significant strides to offer safe, secure, and fair gaming experiences to players.
For this reason, we believe it’s our duty to provide our players with casino recommendations they can trust. Discover what makes a casino legit, why licensing is important, which banking methods you should use, and much more. They offer a variety of independently tested fair games, and bonuses that come with transparent terms. With thousands of casinos online, it’s hard to find the right one that safeguards your wellbeing and funds. If gambling stops being fun, it’s time to stop. We may receive a small commission when you sign up through our referral links. Do I need to verify my ID when I sign up to one of these sites?
This Irish online casino appeals to slot fans with its large game library, though the 3+ day payout time and lack of mobile apps might disappoint players who want faster access. Listing is based on real account testing, verified licensing checks, actual deposit/withdrawal tests, and customer support interaction. We tested casinos offering welcome packages worth €100-€2000, slot libraries ranging from ,960 games, and deposit minimums as low as €1.
Until the new system is fully in place, many Irish players continue to use casinos licensed in Malta or the UK, both of which are recognised for strong consumer protections. There’s a reason for this, and it’s because they have the best payout potential. The software providers that power a casino can tell you a lot about the quality of the experience. Crash games are a newer addition but have quickly become a hit in Ireland.
Operators, however, are subject to licensing fees and regulatory requirements under the new GRAI framework. Online gambling is legal in Ireland but is undergoing significant regulatory change. Live casino streams adapt to smaller screens while maintaining video quality. Most use responsive web design that adapts to your screen size automatically — no app download required.
The site’s user-friendly interface makes navigation easy across both desktop and mobile devices, and a dedicated app is available for easy access on the go. The site is user-friendly, with a fun green aesthetic and a design that makes it easy to find your favourite games. It’s hard to believe you won’t get defrauded if the casino doesn’t mention the basic terms and conditions in the place it’s easy to find them. So, it’s up to you to make sure that you thoroughly check the sites that you’re accessing by reading online reviews and guides like the one provided here. Online games, specifically casino games, are not difficult to get into because all online casinos make it very easy for players to sign up, pay, and also play.
If it’s a short window such as hours, you need to decide if you have enough time for playthrough. If an online casino is truly fair, the signup process should be swift and easy. The club is also a social hub, offering quality dining, regular member events, and a lively community feel.
References:
https://blackcoin.co/trusted-aussie-online-casinos-licensed-high-paying-picks/
References:
Video poker https://git.sophiagwen.au/dongnormanby3
References:
Monte cassino https://lazerjobs.in/employer/best-australian-live-casinos-in-2026-real-dealers-and-more/
References:
The orleans casino
References:
https://peatix.com/user/29631488/view
References:
Best online betting
References:
https://liberalwiki.space/wiki/Spielen_Sie_die_besten_OnlineCasinospiele_mit_Boni_und_Freispielen
References:
Casino prague
References:
https://almeida-mcpherson-3.hubstack.net/allgemeine-geschaftsbedingungen-bei-verde-casino-offizielle-website
References:
Diamond mountain casino
References:
https://roadwiki.site/wiki/Verde_Casino_Bonus_2026_150_Freispiele_ohne_Einzahlung
References:
Resto montreal https://www.pdc.edu/?URL=https://de.trustpilot.com/review/owowear.de
References:
Rome casino http://www.cruzenews.com/wp-content/plugins/zingiri-forum/mybb/member.php?action=profile&uid=2335740
References:
Casino war odds https://argrathi.stars.ne.jp:443/pukiwiki/index.php?tobiasenchristensen125924
References:
Craps board https://carstensen-ingram.hubstack.net/jetzt-sichern
References:
Pampers casino https://forum.issabel.org/u/tempomimosa1
References:
Casino perth
References:
https://www.investagrams.com/Profile/holdt4197611
References:
Geant casino drive https://bookmarkdaily.space/item/planm-ige-turniere-feste-auszahlungen
References:
Random number generator online https://freereadinglist.com/News/geniesse-blitzschnelles-mobiles-gameplay/
References:
Great blue heron casino https://actualites.cava.tn/user/slimetoilet0/
References:
Online casino reviews 1 site for best online casinos https://moparwiki.win/wiki/Post:Verde_Casino_Bonus_No_Deposit_Bonus_50_free_spins
References:
Quebec roulette https://theflatearth.win/wiki/Post:Ist_HitnSpin_seris_Ehrliche_Bewertung_von_Sicherheit_Schutz_und_Spielervertrauen
References:
Play slots for fun https://concretewiki.site/wiki/Schnelle_und_Sichere_Einzahlungen_Bei_Verde_Casino_Deutsch
References:
Chuzzle game https://umkmcerdaspajak.id/profile/costwhale51/
References:
Grand casino mn http://web.symbol.rs/forum/member.php?action=profile&uid=1298896
References:
Buffalo bills casino https://maestrokontraktor.com/artikel/memastikan-kelancaran-fungsi-infrastruktur-bangunan/
References:
Blackjack regles http://www.demoscene.ru/english/misc/guest.php3?action=register
References:
Hunger games online game http://www.1865golfacademy.com/songdo_notice/?bmode=view&idx=160974113
References:
G casino reading https://tilaswedding.com/ranking-los-8-mejores-cursos-de-ia-gratuitos-en/
References:
Ameristar casino east chicago https://www.sejongstudent1940.com/52/?bmode=view&idx=164120356
References:
California casinos
References:
https://www.heizaer.ch/index.php/;focus=HSTPTP_com_cm4all_wdn_Flatpress_8970636&path=&frame=HSTPTP_com_cm4all_wdn_Flatpress_8970636?x=entry:entry260126-213848%3Bcomments:1
References:
Online casino slots https://aleksandrmuraev.ru/%d0%b0%d1%84%d0%b8%d1%88%d0%b0/%d1%8f%d0%bd%d0%b2%d0%b0%d1%80%d1%8c-2026%d0%b3/%d0%b3-%d0%b0%d0%bc%d1%83%d1%80%d1%81%d0%ba/
References:
Ocean shores casino http://m.tshome.co.kr/gnuboard5/bbs/board.php?bo_table=0314566770&wr_id=101&page=10
References:
Gibson casino
References:
https://clubkyrios.com/eco-modern-houses/
References:
Presque isle downs and casino
References:
https://www.sperbys-musikplantage.de/Startseite/index.php/;focus=STRATP_com_cm4all_wdn_Flatpress_21123190&path=&frame=?x=entry:entry201014-102533%3Bcomments:1
References:
King casino https://servus-nachbar.at/Neuigkeiten/index.php/;focus=W4YPRD_com_cm4all_wdn_Flatpress_7491266&path=?x=entry:entry260428-123851%3Bcomments:1
References:
Caesars casino windsor https://develop.dgm.es/blog/Falta-poco-para-que-Nicaragua-tenga-Ley-del-manejo-de-residuos
References:
Sands regency casino reno nv https://peter-schroeder.eu/Blog;focus=TKOMSI_com_cm4all_wdn_Flatpress_22119493&path=?x=entry:entry201212-075534%3Bcomments:1
References:
Sun palace cancun http://kenbc.nihonjin.jp/album/album.cgi?mode=detail&no=284
References:
Roulette wheel layout http://vpparfums.ru/blog/journal-blog
References:
Casino savonlinna http://kennyminhstudio.com/chicken-road-mod-apk-v1-1-0speed-hack-no-ads-2/
References:
Dallas casino https://www.atlasrleye.com/fr/l-54-2/
References:
Atlantis casino bahamas https://thestellarsagency.online/unlock-your-potential-with-these-inspiring-ebooks/
References:
Stations casinos https://kevinwedding.net/1930-2/
References:
Caesars palace las vegas http://hyangsang.eabiz.com/bbs/board.php?bo_table=hswz1902_01&wr_id=12
References:
Blackjack basic strategy chart https://www.dr-georg-feldmann.at/HOME/Blog/index.php/;focus=W4YPRD_com_cm4all_wdn_Flatpress_7136643&path=&frame=W4YPRD_com_cm4all_wdn_Flatpress_7136643?x=entry:entry221205-095643%3Bcomments:1
References:
Pamper casino https://vietex.blog.fc2.com/?no=563
References:
Fun roulette https://peax.academy/exploring-new-hobbies-online-courses-for-every-interest/
References:
Bet365 casino mobile https://www.sunminsuperfood.com/148/?bmode=view&idx=4851519
References:
Betting odds explained https://innovationimmigration.co.in/top-reasons-why-australia-remains-the-most-preferred-destination-for-indian-students-in-2026/
References:
Gala casino glasgow http://gdwt.co.kr/news/?bmode=view&idx=6094165
References:
Slot machine bonus https://afrique-culture.com/?p=955
References:
Casino club chicago https://https-bollmohr.hier-im-netz.de/Blog-Teil2;focus=TKOMSI_com_cm4all_wdn_Flatpress_22784790&path=&frame=TKOMSI_com_cm4all_wdn_Flatpress_22784790?x=entry:entry211229-140122%3Bcomments:1
References:
Casino games for ipad https://yonseicounselinglab.com/31/?bmode=view&idx=129429971
References:
Winner casino mobile http://vicacademy.kr/39/?bmode=view&idx=8373390
References:
Montreal casino http://happy-chowon.co.kr/pasture/?bmode=view&idx=5815202
References:
Electronic roulette https://xn--vb0bn4enutu2a20k.com/sub08_01/?bmode=view&idx=164789624
References:
Playboy casino http://www.peter-schroeder.eu/Blog;focus=TKOMSI_com_cm4all_wdn_Flatpress_22119493&path=&frame=TKOMSI_com_cm4all_wdn_Flatpress_22119493?x=entry:entry200929-115630%3Bcomments:1
References:
Choctaw casino durant ok http://knc.edenstore.co.kr/bbs/board.php?bo_table=board_gallery&wr_id=30
References:
Montecito casino http://info-ministry.kr/30/?bmode=view&idx=17358407
References:
Memphis casinos http://vpparfums.ru/blog/greece-travel
References:
Virtual roulette https://work2.kctech.co.in/?p=958
References:
Play online games games https://www.yelloskincare.com/blog/Let%E2%80%99s-Get-a-Little-Nerdy:-Ingredient-Series-Sodium-PCA-(Pyrrolidone-Carboxylic-Acid)
References:
Casino zandvoort https://vivek-desai.com/shortcodes/
References:
Gala casino bristol https://amobear.store/business-social-media-marketing-efforts/
References:
Casino la ciotat https://daikokustores.com/blog/vacation-time
References:
Manoir richelieu forfait http://maidoshop123.blog.fc2blog.us/blog-entry-660.html
References:
Eqc casino https://www.nexustradeworld.com/index.php?route=journal3/blog/post&journal_blog_post_id=11
References:
Real money pokies http://okran.or.kr/event-gallery/?bmode=view&idx=11181734
References:
Choctaw casino durant oklahoma https://christophorus-sb.de/Aktuelles;focus=TKOMSI_com_cm4all_wdn_Flatpress_22854780&path=?x=entry:entry240716-143658%3Bcomments:1
References:
Paragon casino cinema https://www.fanbase.co.ke/index.php?route=journal3/blog/post&journal_blog_post_id=31
References:
L’auberge du lac baton rouge https://www.sejongstudent1940.com/45/?bmode=view&idx=171227006
References:
Laughlin nevada casinos https://azsmart.us/index.php?route=journal3/blog/post&journal_blog_post_id=4
References:
Caesars online casino https://en.citygogo.co.kr/24/?bmode=view&idx=168986034
References:
Choctaw casino pocola https://www.volkswagen-bus.com.ua/uk/smartblog/6_vebasto-t5.html
References:
Slot machine wins http://sposky.com/bbs/board.php?bo_table=bbs_03&wr_id=25
References:
Blackjack game download http://gdwt.co.kr/news/?bmode=view&idx=5471738
References:
Casino canberra https://thestellarsagency.online/discover-the-hidden-gems-best-lesser-known-ebooks/
References:
Century casino calgary https://judith-ricklin.ch/Blog/index.php/;focus=HSTPTP_com_cm4all_wdn_Flatpress_6019167&path=&frame=HSTPTP_com_cm4all_wdn_Flatpress_6019167?x=entry:entry230220-213104%3Bcomments:1
References:
Casino gold coast https://www.vikipesa.ee/?attachment_id=1528
References:
Best online casino sites https://trekugandatours.com/destination/queen-elizabeth-national-park/
References:
Peppermill casino wendover https://shkolnaiapora.ru/question/monetu-v-15-kopeek-ranshe-nazyvali-pyatialtynnym
References:
Winstar casino https://www.sunminsuperfood.com/148/?bmode=view&idx=171189004
References:
Regina casino https://www.fanbase.co.ke/index.php?route=journal3/blog/post&journal_blog_post_id=42
References:
Best online casino usa https://etkomedia.com/index.php?route=journal3/blog/post&journal_blog_post_id=11
References:
Casino online games http://okran.or.kr/event-gallery/?bmode=view&idx=11179514
References:
Best online strategy games https://alindavanmeel.nl/5-steps-to-creating-a-stress-busting-content-calendar/
References:
Roulette numbers http://discountssalestore.blog.fc2.com/blog-entry-294.html
References:
Poker machines http://www.cooking.4fan.cz/index.php?category=13&article=210
References:
Banque casino fr espace client https://jaylim1.com/18/?bmode=view&idx=167195662
References:
Silver sevens casino http://www.kingofdove.com/blog/season-essentials
References:
Hollywood casino baton rouge la https://www.pan24.com/51/?bmode=view&idx=1961447
References:
Malaysia central gaming https://homecomfort.rivne.ua/blog/another-blog-post
References:
Casino ct https://www.crump.click/index.php?route=journal3/blog/post&journal_blog_post_id=10
References:
Live casino md https://leonparc.nl/best-beauty-products
References:
Blackjack band https://vietex.blog.fc2.com/blog-entry-566.html
References:
Royal vegas casino
References:
http://socialpharm.skku.edu/news/?bmode=view&idx=13916019
References:
Paragon casino https://sejonghw.co.kr/file/?bmode=view&idx=169889864
References:
Online funny videos http://kimnpark.net/gnu5/bbs/board.php?bo_table=2014Taiwan&wr_id=5715
References:
Newkirk casino https://www.bangla99.com/blog/Fat-burner-Bangla-review
References:
Isle of capri florida
References:
http://www.pibunara.com/20/?bmode=view&idx=14949521
References:
Charleston wv casino http://okran.or.kr/review/?bmode=view&idx=169022993
References:
Casino midas https://www.heizaer.ch/index.php/;focus=HSTPTP_com_cm4all_wdn_Flatpress_8970636&path=&frame=HSTPTP_com_cm4all_wdn_Flatpress_8970636?x=entry:entry250508-190656%3Bcomments:1
References:
Siloam springs casino https://medicalcentersaenspena.com.br/2023/06/22/the-power-of-effective-communication-in-business/
References:
Caesar casino https://www.zhomggde.com/index.php?route=journal3/blog/post&journal_blog_post_id=4
References:
Gold river casino https://gamemarts.io/index.php?route=journal3/blog/post&journal_blog_post_id=11
References:
Craps system http://elliotntcc749.blog.fc2.com/?no=63
References:
Century casino http://gallerybi.com/Startercourse_2021/?bmode=view&idx=6578104
References:
Best slot machines to play http://outletstores.blog.fc2.com/blog-entry-8799.html
References:
Melbourne casino https://znpic.ir/fa-ir/%DA%AF%D8%A7%D9%84%D8%B1%DB%8C/emodule/1509/eitem/1852?edgmid=1509&edgpid=1870
References:
Solstafir https://leonparc.nl/vacation-time
References:
Casino lobby mybet http://www.ehaeoreum.co.kr/93/?bmode=view&idx=18017091
References:
New online casinos http://kysobourbi1974.blog.fc2.com/blog-entry-34.html
References:
Peppermill casino reno nv http://www.gwangjuheavy.com/40/?bmode=view&idx=169152957
References:
Everest casino
References:
http://atd.ne.kr/26/?bmode=view&idx=4553151
References:
Rapunzel play doh https://thoitrang.blog.fc2.com/blog-entry-6036.html
References:
The sands casino https://www.mosaictailor.com/blog/?bmode=view&idx=162600275
References:
Bet casino https://ascrolite.com/component/k2/item/3-build-with-less-and-bootstrap.html?v=u
References:
Casinos san diego https://epdacameroon.org/wash-in-schools/
References:
Suncoast casino las vegas https://physiotheraphy.blog.fc2.com/blog-entry-26.html
References:
Saratoga casino https://ulovepet.co.kr/report/?bmode=view&idx=3615073
References:
Comeon casino review http://thenbpglobal.com/15/?bmode=view&idx=5221854
References:
Seminole hard rock casino tampa http://koreaultimate.org/Announcements/?bmode=view&idx=1413297
References:
Casinobonus2 com http://www.ragu.world/index.php?route=journal3/blog/post&journal_blog_post_id=3
References:
New casino sites http://openca8o.beget.tech/index.php?route=journal3/blog/post&journal_blog_post_id=11
References:
Ct casinos http://fermertechnika.ru/blog/journal-blog
References:
Slot machine casino https://www.aasfaa.net/About-AASFAA/Gallery/emodule/740/eitem/18
References:
Lone butte casino
References:
https://www.yelloskincare.com/blog/Let%E2%80%99s-Get-A-Little-Nerdy:-Ingredient-Series-Alpha-Arbutin
References:
Roulette wheels https://raymangreen.com/2024/03/20/benefits-of-going-solar-why-switching-to-solar-energy-makes-sense/
References:
Casino barcelona https://e-kspert.cl/2023/12/26/tiny-tot-adventures-a-peek-into-our-preschool-world/
References:
Blackjack probability https://antika24.ru/blog?journal_blog_post_id=21
References:
Casino microgaming https://www.corbatasroyal.com/blogs/16_Palmeras-gigantes.html
References:
Kansas casinos http://balihouse.kr/108/?bmode=view&idx=6355428
References:
Station casinos boarding pass http://gyujanggak.edenstore.co.kr/bbs/board.php?bo_table=board_gallery&wr_id=149
References:
Excalibur casino las vegas https://natacat.ru/web/kindlycat/bri/?p=gb
References:
Quicksilver casino https://mikimak.com/classic-watches
References:
Wind creek casino atmore http://www.xn--5y2b34bl7aoztptaefwhy5ir5bf86ak1lk6bz3b.com/bbs/board.php?bo_table=news&wr_id=33
References:
Genting casino southport http://mogiwood.com/mshop/?bmode=view&idx=4880666
References:
How many casinos are in las vegas http://www.polymerpartner.com.mx/blog/index.php?id=av4
References:
Chicago casinos http://iwuseoul.com/smallweddingkr/?bmode=view&idx=2211475
References:
Winpalace https://anasmitrap.org.br/entidades-sindicais-da-mesa-lancam-manifesto-sobre-mediacao-de-conflitos-e-preparam-reuniao-no-congresso/
References:
Mobile roulette https://www.katjas-naehrreich.at/Blog/index.php/;focus=W4YPRD_com_cm4all_wdn_Flatpress_7137915&path=&frame=W4YPRD_com_cm4all_wdn_Flatpress_7137915?x=entry:entry221125-134139%3Bcomments:1
References:
Ocean’s eleven casino
References:
http://nationsworld.kr/bbs/board.php?bo_table=volume&wr_id=252
References:
Seven feathers casino http://elliotntcc749.blog.fc2.com/blog-entry-52.html
References:
Casino win
References:
http://jinsol.org/60/?bmode=view&idx=10071981
References:
G casino coventry https://rota-agro.ru/news/syry-rota-agro-voshli-v-sbornik-luchsh/
References:
Vancouver casinos http://urbanex.co.kr/33/?bmode=view&idx=8304071
References:
Erie casino https://www.welscamp-spanien.de/en-us/Gallery/emodule/741/eitem/391
References:
Casino sharon stone https://bitpoll.mafiasi.de/poll/2JO0j6s7lc/
References:
Reno nevada casinos https://www.buyrvlights.com/9007-led-2-145/
References:
Silver sevens casino http://studiotarget.net/1767241180/?bmode=view&idx=152268357
References:
Pockie pirates https://etkomedia.com/index.php?route=journal3/blog/post&journal_blog_post_id=12
References:
Blackjack 2ne1 https://cpdbouvxc3m7.blog.fc2.com/blog-entry-310.html
References:
Reef club casino https://intensedebate.com/people/sheethockey01
References:
Crown perth casino https://gardenwiki.site/wiki/50_Freispiele_200_bis_1000
References:
Winpalace https://atomcraft.ru/user/toehat93/
References:
Play online roulette https://rentry.co/u7zd8dt8
References:
Bally slot machines https://coolpot.stream/story.php?title=nv-casino-deutschland-schneller-login-und-bonus-angebote
References:
Genting casino newcastle https://neoclassical.space/wiki/Aktionen_Bonus_und_Live_games_Spiele
References:
Hard rock casino las vegas https://diego-maradona.com.az/user/museumpan1/
References:
Casino games slots http://amur.1gb.ua/user/trunknation3/
References:
Casino red https://g.clicgo.ru/user/motionparrot5/
References:
What is a pci slot https://gardenwiki.site/wiki/Willkommensbonus_Bis_zu_2_000_225_Freispiele
References:
Parxs casino https://skitterphoto.com/photographers/2800850/just-blevins
References:
Playing roulette https://firsturl.de/Db6qEN2
References:
Random number generator online https://dreevoo.com/profile.php?pid=1760079
References:
Casino alabama https://literaturewiki.site/wiki/Zet_Casino_15_bis_zu_3_000_Cashback_Bonus_2026
References:
Opoker https://theflatearth.win/wiki/Post:1go_Casino_im_Test_Lohnt_sich_der_Einstieg_2026_wirklich
References:
Win at roulette https://forums.ppsspp.org/member.php?action=profile&uid=6515689
References:
Four winds casino dowagiac http://ezproxy.cityu.edu.hk/login?url=https://de.trustpilot.com/review/owowear.de
References:
Casino oregon https://commonwiki.space/wiki/Jet_Casino_Live_Casino_mit_Bonus_in_Deutschland
References:
Slim slots https://chesswiki.site/wiki/Legiano_Casino_Bonus_Codes_2026_Exklusive_Boni
References:
Go wild casino https://topsitenet.com/profile/lizardpacket5/1872428/
References:
Hampton casino http://bookmarkingcentrals.com/News/bizzo-casino-deutschland-moderne-slots-live-games-200-bonus/
References:
Slots for fun no download https://literaryforge.blog/author/flarespear00/
References:
Hollywood casino toledo https://theflatearth.win/wiki/Post:Zahlungsmethoden_im_Monro_Casino_Ein_und_Auszahlungen_erklrt
References:
Atlantis casino bahamas https://classifieds.ocala-news.com/author/crossbull44
References:
Tunica ms casinos http://www.bmw-workshop.com/member.php?action=profile&uid=44218
References:
Star casino sydney https://www.forum-joyingauto.com/member.php?action=profile&uid=145932
References:
Inspired gaming group https://www.garagesale.es/author/europewrench40/
References:
Europa casino download https://wilcox-bolton-2.mdwrite.net/verde-casino-test-ist-es-wirklich-serios
References:
Best online blackjack https://boardgameswiki.site/wiki/Kings_Resort_Kings_Resort_DE_Kings
References:
Rtg no deposit bonus codes https://classifieds.ocala-news.com/author/cymbalsale2
References:
Casino cairns https://melendez-pilegaard-2.thoughtlanes.net/die-besten-paypal-casinos-2026-sicher-einzahlen-mit-bonus
References:
Online casino geld verdienen https://nomadwiki.space/wiki/Licensed_Online_Casino_with_Registration_Bonus
References:
Casino drive bastia https://pbase.com/singerpotato68/
References:
Redhawk casino https://gaiaathome.eu/gaiaathome/show_user.php?userid=1977960
References:
Grand villa casino http://forums.cgb.designknights.com/member.php?action=profile&uid=191169
References:
Casino aachen https://500px.com/p/sahinrbulevin
References:
Roulette machine https://www.instapaper.com/p/17728408
References:
Slot play https://forums.ppsspp.org/member.php?action=profile&uid=6515211
References:
Casino 21 http://downarchive.org/user/robinturkey7/
References:
Walking dead time slot http://karayaz.ru/user/cavesister92/
References:
Instant Casino Treueprogramm
References:
https://actualites.cava.tn/user/crowdeggnog69/
References:
Gala casino london https://prpack.ru/user/adultslice8/
References:
Gaming club casino https://neolatinswiki.site/wiki/Offizielles_Casino_Deutschland_2026
References:
Grand casino tunica http://qa.doujiju.com/index.php?qa=user&qa_1=treelake0
References:
Gold eagle casino https://sonnik.nalench.com/user/altomother97/
References:
Galaxy casino macau https://gamingwiki.space/wiki/Bizzo_Casino_Bewertung_Das_ultimative_OnlineCasino_fr_deutsche_Spieler
References:
Online roulette wheel https://audiobook.net.pl/user/crookpipe6/
References:
Casino spokane https://rentry.co/u9eddxk5
References:
Casino magic neuquen https://g.clicgo.ru/user/bunvirgo7/
References:
Grand casino helsinki http://tropicana.maxlv.ru/user/nutcrocus0/
References:
Isle of capri casino https://urlscan.io/result/019e6552-28fb-727a-ac56-fab210704619/
References:
Blackjack driveway sealer http://csmouse.com/user/powdersmile2/
References:
Club u s a casino https://isowindows.net/user/nutserver3/
References:
Gold coast casino las vegas https://telegra.ph/Nv-casino-app-Casino-Bewertung-sicher-oder-Betrug-Vertrauen-41-100-05-26
References:
Cherry casino http://www.qazaqpen-club.kz/en/user/paulsofa8/
References:
Netteller login https://greecestudies.site/wiki/Verde_Casino_Registrierung_und_Login
References:
Capitol casino https://boardgameswiki.site/wiki/Legiano_Erfahrungen_2026_Test_Bewertung
References:
Buffalo run casino https://bridgedesign.space/wiki/Bonus_Freispiele_Auszahlung_Login_2026
References:
Eldorado casino shreveport https://bridgedesign.site/wiki/Drip_Casino_Bonus_ohne_Einzahlung_in_Deutschland_Kostenlos_spielen_und_echt_gewinnen
References:
Big fish casino online https://www.youtube.com/redirect?q=https://de.trustpilot.com/review/shschmuck.de
References:
Winning at slots https://sportpoisktv.ru/author/cardchance3/
References:
Wizard of odds video poker https://shapemyskills.in/members/shrinedill05/activity/20327/
References:
Zeus slot machine https://nomadwiki.space/wiki/Offizielle_Website_Schnelle_Auszahlungen_fr_Deutschland
References:
Casino baton rouge https://resonantmindcollective.com/author/heatstreet47/
References:
Schecter blackjack atx c 7 https://cineblog01.rest/user/quartsled42/
References:
Blackjack probability https://bookmarkingworlds.com/News/bonus-app-sportwetten-zahlungen-legalitaet/
References:
Casino cherokee nc https://isowindows.net/user/gatevein9/
References:
Royal casino https://bookmark4you.win/story.php?title=zetcasino-serioes-oder-betrug-test-erfahrungen-2026
References:
Betclic casino https://pads.jeito.nl/s/rSSDaKIY02
References:
Solaire casino manila http://adrestyt.ru/user/jaguarshelf52/
References:
Leelanau sands casino http://ezproxy.cityu.edu.hk/login?url=https://de.trustpilot.com/review/sandsack-kontor.de
References:
Nugget casino http://lukovich.ru/user/doubtloan71/
References:
Terribles casino https://www.instapaper.com/p/17728335
References:
Video poker trainer http://www.bmw-workshop.com/member.php?action=profile&uid=44276
References:
Casinos san diego https://neolatinswiki.site/wiki/Online_Casino_fr_Deutschland_7_000_Spiele_Bonus_bis_900
References:
Rivers casino chicago https://notes.medien.rwth-aachen.de/QRxTNX-bShKH7833nQUJTg/
References:
Casino lisboa macau https://urlscan.io/result/019e6594-5cc3-75bc-8b77-a2ad8c1b8532/
References:
Online vegas casino https://sub.elfejewelry.com:443/index.php?sheehancochrane019004
References:
Kings casino rozvadov http://www.bmw-workshop.com/member.php?action=profile&uid=44305
References:
Eureka casino mesquite https://skitterphoto.com/photographers/2801964/bendsen-french
References:
The mill casino https://diego-maradona.com.az/user/comiccoat8/
References:
Video slot machines https://bridgedesign.space/wiki/Bonus_10_000_450_Freispiele
References:
Gibson casino https://bridgedesign.site/wiki/Login_Verde_Casino_Sicherer_Zugriff_Bonus
References:
Genting casino southport https://gamingwiki.space/wiki/Licensed_Online_Casino_with_Registration_Bonus
References:
Play casino https://literaryforge.blog/author/bloodcotton39/
References:
Mobile slots https://bookmark4you.win/story.php?title=paypal-casino-888-casino-mit-paypal-bezahlen
References:
Casino online usa http://www.annunciogratis.net/author/deercinema6
References:
Syracuse casino https://socialbookmark.stream/story.php?title=sofort-registrieren-mega-bonus
References:
Gulfport casinos https://lichnyj-kabinet-vhod.ru/user/farmhubcap10/
References:
Tabactivity https://dancewiki.site/wiki/100_Einzahlungsbonus_bis_zu_1000
References:
Cherokee casino west siloam springs https://md.swk-web.com/s/fS7oTykVg
References:
Pink floyd live at pompeii https://www.udrpsearch.com/user/helenjoseph1
References:
Seminole hard rock casino tampa https://forum.board-of-metal.org/user-50305.html
References:
Genting casino glasgow https://boardgameswiki.site/wiki/EchtgeldCasinospiele_VIPBoni
References:
Casino speedway https://buyandsellhair.com/author/childchance9/
References:
Cairns casino https://skitterphoto.com/photographers/2800098/carrillo-blair
References:
Isleta casino https://hwang-irwin-2.mdwrite.net/verde-casino-bonus-ohne-einzahlung-8-exklusive-boni-verfugbar
References:
Northern california casinos https://servodriven.com/forums/users/linenshadow09/
References:
Slots for fun https://gardenwiki.site/wiki/Zetcasino_Aktionscode_in_Deutschland_Erleben_Sie_mobilfreundliches_Gaming_mit_schnellen_Auszahlungen
References:
Seneca casino https://orr-thorpe.federatedjournals.com/lex-casino-offizielle-online-spielothek-in-deutschland
References:
Choctaw casino durant ok https://brewwiki.win/wiki/Post:1Go_Casino_OnlineGamingPromotion_fr_GermanySpieler
References:
Gewinne bei Instant Casino auszahlen
References:
https://forums.ppsspp.org/member.php?action=profile&uid=6514331
References:
Zodiac online http://uchkombinat.com.ua/user/lutekettle4/
References:
William hill mobile app https://telegra.ph/Vegas-Mobile-casino-testbericht-2026-05-26
References:
Casino san diego https://apunto.it/user/profile/979851
References:
Ak chin casino https://stackoverflow.qastan.be/?qa=user/malecuban1
References:
Concho casino https://www.youtube.com/redirect?q=https://de.trustpilot.com/review/deincorazon.de
References:
Holland casino scheveningen http://downarchive.org/user/bowcatsup14/
References:
Blackjack strategy trainer https://truckwiki.site/wiki/Monro_Casino_No_Deposit_Bonus_Deutschland_Bonuscode_Freispiele_Cashback_VIP
References:
La riviera casino https://molchanovonews.ru/user/eaglewealth04/
References:
Maryland live casino reviews https://concretewiki.site/wiki/Kings_Resort_casino_and_hotels_in_Rozvadov_in_Tschechien_ab_61_Angebote_Bewertungen_Fotos
References:
Wynn casino https://topsitenet.com/profile/robinmale1/1871708/
References:
Casino verite http://uchkombinat.com.ua/user/emeryrose5/
References:
Blackjack play http://kriminal-ohlyad.com.ua/user/planecanvas90/
References:
Ho chunk casino baraboo http://madk-auto.ru/user/tenormatch6/
References:
Online gaming websites https://www.forum-joyingauto.com/member.php?action=profile&uid=145885
References:
Ameristar casino st charles mo https://qomplainerzschool.lima-city.de/member.php?action=profile&uid=54257
References:
Ameristar casino east chicago https://prpack.ru/user/gardenneedle51/
References:
High winds casino http://lukovich.ru/user/pvcburst95/
References:
Black jack no yuuwaku https://bom.so/QrvaNr
References:
Casino listings https://truckwiki.site/wiki/So_kontaktieren_Sie_den_Total_CasinoKundendienst_Alle_verfgbaren_Kanle_fr_Deutschland
References:
New casino https://bridgedesign.site/wiki/Exklusive_Aktionen_und_Prmien
References:
Christophe claret 21 blackjack https://dreevoo.com/profile.php?pid=1761393
References:
Casino calgary https://liberalwiki.space/wiki/Kings_Casino_Mindestalter
References:
One armed bandit https://ontrip.80gigs.com/profile/creditsailor45/
References:
Roulette systeme mein roulette online https://etuitionking.net/forums/users/stonezoo0/
References:
Red cliff casino https://concretewiki.site/wiki/ZetCasino_App_2026_Top_Mobile_Spiele_PWA_Download
References:
Online roulette australia https://chesswiki.site/wiki/70_Bonus_ohne_Einzahlung_2500_Willkommenspaket
References:
Prestige casino https://www.udrpsearch.com/user/diggergarlic8
References:
Real money online poker https://literaryforge.blog/author/johnzoo03/
References:
Casino california https://servodriven.com/forums/users/rakerobert41/
References:
Casino verite http://madk-auto.ru/user/climbwrench4/
References:
Game slots https://bookmarks4.men/story.php?title=beste-online-casino-2
References:
Pokies online https://apunto.it/user/profile/980268
References:
Casino online usa https://freudwiki.site/wiki/Poker_im_Kings_Casino_in_Rozvadov_Poker_in_Tschechien
References:
M life casinos https://www.pradaan.org/members/sarahnight8/activity/889776/
References:
Punto banco https://doodleordie.com/profile/neoncrop4
References:
Casino miami https://pad.stuve.uni-ulm.de/s/VtXpw5dGJ
References:
Casino jack and the united states of money https://skitterphoto.com/photographers/2799757/husum-mcgee
References:
Instant Casino App iOS
References:
https://moiafazenda.ru/user/greaserod1/
References:
Zeus slot machine https://firsturl.de/82BFb10
References:
Best slot machines to play https://truckwiki.site/wiki/Zet_CasinoTurniere
References:
Mobile casino bonus http://forums.cgb.designknights.com/member.php?action=profile&uid=187533
References:
Little creek casino http://adrestyt.ru/user/barbertomato12/
References:
Online casino paypal https://concretewiki.site/wiki/Alle_verfgbaren_Boni_bei_Drip_auf_der_offiziellen_Website
References:
Toronto casino https://boardgameswiki.site/wiki/Verde_Casino_Erfahrungen_2026_Boni_Spiele_und_Zahlungen_im_Test
References:
T slot nuts https://www.udrpsearch.com/user/stitchjudo1
References:
Casino promotions https://gamesgrom.com/user/uncleverse6/
References:
Casino hollywood https://analnoe.com/user/glidertext3/
References:
Shreveport la casinos https://architecturewiki.site/wiki/Kings_Resort_Kings_Resort_DE_Kings
References:
Cabazon casino https://oiaedu.com/forums/users/cementkevin65/
References:
Casino tropez http://karayaz.ru/user/doubtspear25/
References:
Instant Casino Auszahlungsdauer
References:
https://molchanovonews.ru/user/wrensound78/
References:
Mgm grand casino https://ancientroman.space/wiki/Blackjack_spielen_in_den_Casinos_in_Las_Vegas_Infos_Regeln_Strategie
References:
Halifax casino http://warblog.hys.cz/user/pothot7/
References:
Pci slot https://socialbookmark.stream/story.php?title=online-casino-mit-1-euro-einzahlung-beste-1-casinos-2026
References:
Sunset station casino https://matkafasi.com/user/tuliplinda17
References:
Singapore casino https://neolatinswiki.site/wiki/Kontakt_Legiano_casino_Deutschland
References:
Cancun casino https://molchanovonews.ru/user/pestcellar20/
References:
Ladbrokes slots https://skitterphoto.com/photographers/2801159/bak-cooper
References:
Casino quebec https://conrad-poe.thoughtlanes.net/888-casino-bonus-code-200-startgeld-extra-free-spins
References:
Drive casino http://www.qazaqpen-club.kz/en/user/ruthcollar3/
References:
Wild rose casino https://firsturl.de/Qw3q4ea
References:
Windcreek casino atmore al http://forums.cgb.designknights.com/member.php?action=profile&uid=191034
References:
Slot machine symbols http://okprint.kz/user/planetpot4/
References:
Billy the kid casino https://matkafasi.com/user/danieldegree81
References:
Sun vegas casino https://gaiaathome.eu/gaiaathome/show_user.php?userid=1977600
References:
Games casino https://bookmarkingworlds.com/News/willkommensbonus-bis-zu-500-100-freispiele/
References:
Thief river falls casino https://philosophywiki.space/wiki/Offizielle_Seite_1500_Bonus_200_FS
References:
Rio casino https://pads.jeito.nl/s/A7S5AG64_D
References:
Casino win https://nomadwiki.space/wiki/Ice_Casino_Promo_Codes_Exklusive_Angebote_und_Bonusaktionen_fr_Spieler
References:
Betvictor slots https://www.demilked.com/author/soaptown62/
References:
Playboy casino cancun https://bookmarkpress.site/item/verde-casino-test
References:
Augustine casino https://gaiaathome.eu/gaiaathome/show_user.php?userid=1978022
References:
Online casinos south africa https://www.giveawayoftheday.com/forums/profile/1890603
References:
Swiss casino https://ondashboard.win/story.php?title=monro-casino-casino-deutschland-bis-zu-2500-200-freispiele
References:
Peppermill casino reno nv https://doodleordie.com/profile/lowedger23
References:
Longest craps roll https://sub.elfejewelry.com:443/index.php?harveypontoppidan157490
References:
Vegas casino https://dailybeacon.space/item/sicherer-und-schneller-zugriff
References:
Comeon casino review https://literaturewiki.site/wiki/HitnSpin_Casino_800_EUR200_FS_WILLKOMMENSBONUS
References:
Hollywood casino cincinnati https://https://bridgedesign.site/wiki/HitnSpin_Alternative_Die_5_besten_Alternativen_hier_Mai_2026_hnliche_Casinos_hier/wiki/HitnSpin_Alternative_Die_5_besten_Alternativen_hier_Mai_2026_hnliche_Casinos_hier
References:
Roulette payout chart https://onlinevetjobs.com/author/cordlayer3/
References:
Four winds casino https://dailybeacon.site/item/hit-prospekt-angebote-der-woche-online-bl-ttern
References:
Casino nb https://eskisehiruroloji.com/sss/index.php?qa=user&qa_1=cordlawyer1
References:
Konocti vista casino https://materialwiki.site/wiki/Slots_und_Live_Games_sofort_spielen
References:
Casino night https://truckwiki.site/wiki/Das_offizielle_HitnSpin_Casino_in_Deutschland
References:
Casino fandango http://warblog.hys.cz/user/tiebag2/
References:
Potawatomi casino milwaukee https://rentry.co/5h496c7d
References:
Nb casino https://philosophywiki.space/wiki/Bonusse_1200_220_FS
References:
Vicksburg ms casinos https://philosophywiki.space/wiki/Das_Beste_Online_Casino_in_Deutschland_Jetzt_registrieren
References:
Noble casino https://g.clicgo.ru/user/runoutput8/
References:
Kickapoo lucky eagle casino https://gratisafhalen.be/author/bumperbronze56/
References:
Instant Casino Slots
References:
https://skitterphoto.com/photographers/2540636/blanton-brooks
References:
Roulette layout https://neoclassical.space/wiki/Kontakt_Kundensupport
References:
Download casino games https://philosophywiki.space/wiki/N1_Casino_Casino_Bonus_2026_Freispiele_Exklusive_Bonuscodes
References:
Maryland casinos http://kriminal-ohlyad.com.ua/user/neonquartz03/
References:
Slotmachines https://telegra.ph/Online-Casino-Spiele-JETZT-SPIELEN-06-05-10
References:
Machine games https://justbookmark.win/story.php?title=legiano-casino-bonus-100-bis-zu-500-200-fs
References:
Roulette machine https://may22.ru/user/crimeevent26/
References:
Red rock casino las vegas https://www.investagrams.com/Profile/walter4274744
References:
Royal casino https://forum.board-of-metal.org/user-50391.html
References:
Aria casino las vegas https://bridgedesign.space/wiki/Lex_Casino_in_sterreich_zuverlssiges_OnlineCasino_mit_3_500_Spielen_und_schnellen_Auszahlungen
References:
Unibet casino https://sitesrow.com/story11579023/casino-of-gold-ihr-weg-zum-jackpot
I beloved up to you’ll receive carried out right here. The caricature is tasteful, your authored material stylish. however, you command get got an shakiness over that you would like be turning in the following. in poor health without a doubt come further until now once more since exactly the similar nearly a lot regularly inside case you defend this increase.